7.Python使用pandans遇到的坑
1.开始入门Pandas,然后跟着网上的例子,编写以下代码:
import pandas as pd
import datetime
import pandas.io.data as web start = datetime.datetime(2010,1,1)
end = datetime.datetime(2015,8,22) df = web.DataReader('XOM','yahoo',start,end) print(df)
2.一运行报错信息为:ModuleNotFoundError: No module named ' pandas.io.data'
pandas.io.data'

3.查找网上教程,发现pandas.io.data已经用不成了,得替换为pandas_datareader,故在dos命令输入:pip3 install pandas_datareader,在pycharm-setting导入
4.修改后的代码如下所示:
import pandas as pd
import datetime
import pandas_datareader.data as web start = datetime.datetime(2010,1,1)
end = datetime.datetime(2015,8,22) df = web.DataReader('XOM','yahoo',start,end) print(df)
5.依旧报错:ImportError: cannot import name 'is_list_like'
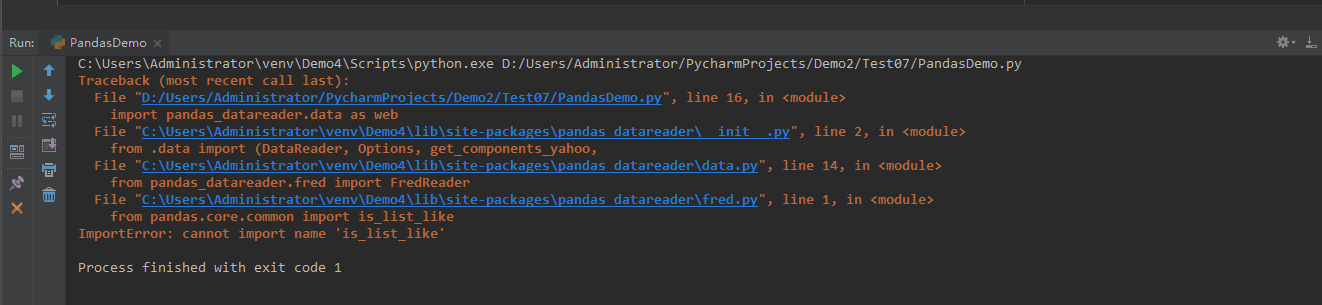
6.查找网上教程后,需要去fred.py中修改信息,在pycharm报错信息中,点击C:\Users\Adinistrator\venv\Demo4\lib\site-packages\pandas_datareader\fred.py中,将from pandas.core.common import is_list_like替换为:from pandas.api.types import is_list_like(正确方式)
7.继续修改代码后,运行,依旧报错,报错信息如下:
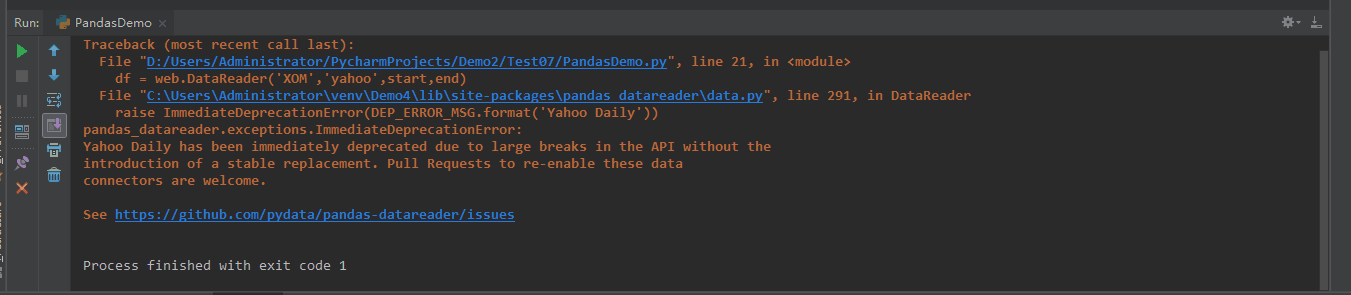
8.依旧寻找教程,发现错误原因为:Yahoo的数据源已经失效,使用另一个数据源即可,最后代码如下所示:
import pandas as pd
import datetime
import pandas_datareader.data as web start = datetime.datetime(2010,1,1)
end = datetime.datetime(2015,8,22) df = web.DataReader('F-F_Research_Data_factors','famafrench',start,end)
print(df)
7.Python使用pandans遇到的坑的更多相关文章
- 关于python数据序列化的那些坑
-----世界上本来没那么多坑,python更新到3以后坑就多了 无论哪一门语言开发,都离不了数据储存与解析,除了跨平台性极好的xml和json之外,python要提到的还有自身最常用pickle模块 ...
- Python开发过程中17个坑
一.不要使用可变对象作为函数默认值 复制代码代码如下: In [1]: def append_to_list(value, def_list=[]): ...: def_list. ...
- python 库之lxml安装 坑一个
error: command 'C:\\Users\\Admin\\AppData\\Local\\Programs\\Common\\Microsoft\\Visual C++ for Python ...
- python中sqlite问题和坑
import sqlite3 #导入模块 conn = sqlite3.connect('example.db') C=conn.cursor() #创建表 C.execute('''CREATE T ...
- Python读取大文件的"坑“与内存占用检测
python读写文件的api都很简单,一不留神就容易踩"坑".笔者记录一次踩坑历程,并且给了一些总结,希望到大家在使用python的过程之中,能够避免一些可能产生隐患的代码. 1. ...
- influx+grafana自定义python采集数据和一些坑的总结
先上网卡数据采集脚本,这个基本上是最大的坑,因为一些数据的类型不正确会导致no datapoint的错误,真是令人抓狂,注意其中几个key的值必须是int或者float类型,如果你不慎写成了strin ...
- 基于python的Appium自动化测试的坑
真的感谢@虫师 这位来自互联网的老师,让我这个原本对代码胆怯且迷惑的人开始学习自动化测试. 一开始搜索自动化测试的时候,虫师的博客园教程都是在百度的前几位的,我就跟着虫师博客园里面的教程学习.后来学s ...
- Python Django开发遇到的坑(版本不匹配)
这个问题 进入django 后台, 添加,修改都不可以,只有删除可以,那么百分之百是这个问题 对照一下,是你的django 版本低了还是 python版本高了,对照的话就没问题了 这个坑,弄了两天啊! ...
- Python可变数据类型list填坑一则
前提概要 最近写业务代码时遇到一个列表的坑,在此记录一下. 需求 现在有一个普通的rule列表: rule = [["ID",">",0]] 在其他地方经 ...
随机推荐
- IOS UI-键盘处理和UIToolbar
// // ViewController.m // IOS_0225-键盘处理和UIToolBar // // Created by ma c on 16/2/25. // Copyright © 2 ...
- [WinForm]FastColoredTextBox控件(附源码)
Fast Colored TextBox is text editor component for .NET. Allows you to create custom text editor with ...
- 【zznu-夏季队内积分赛3-I】逛超市
题目描述 “别人总说我瓜,其实我一点也不瓜,大多数时候我都机智的一批“我宝儿姐背包学的太差了,你们谁能帮我解决这道题,我就让他做我的男朋友!宝儿姐现在在逛超市,超市里的种类实在是太多了,每种都有很多很 ...
- SQL2008R2 收缩数据库问题 - 日志文件不变小
数据库的日志文件(*.ldf)越来越大,怎么办? 收缩吧.收缩日志文件的操作真不简单哟,还跟数据库的恢复模式有关啊. 一.“简单恢复模式”时的日志收缩 1. 截断日志 当数据库的恢复模式为“简单”的时 ...
- 词频统计 ——Java
github地址 :https://github.com/NSDie/personal-project 一.计划表 PSP2.1 Personal Software Process Stages 预估 ...
- Java静态绑定和动态绑定
程序绑定的概念: 绑定指的是一个方法的调用与方法所在的类(方法主体)关联起来.对java来说,绑定分为静态绑定和动态绑定:或者叫做前期绑定和后期绑定 静态绑定(早绑定 编译器绑定): 在程序执行前方法 ...
- flask 文件的上传下载和excel操作
文件的下载 from flask import send_from_directory @excel_bp.route('/get_attachment/<path:filename>') ...
- Gcov 详解 + 内核函数覆盖率测试方法详述及产生错误解决办法
http://blog.csdn.net/wangyezi19930928/article/details/42638345 http://www.uml.org.cn/Test/201208311. ...
- React之事件处理
在react中,事件处理的写法和处理方式可能会和vue以及传统html有些不同. 一.事件名和默认行为阻止 事件名采用驼峰写法,并且方法名用大括号引入,而不是双引号: <button onCli ...
- three.js入门系列之旋转的圆台、球体、正方体
先来张图: 一.调整机位和辅助线 由上述代码可知,现在的机位是三维坐标轴上的点(2,2,2),方框的那一句很重要,有了这一句,你将获得上帝视角!!! 接下来添加辅助线(立体空间三轴): 这样就添加了一 ...