词频统计 ——Java
一、计划表
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 400 | 690 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 20 | 15 |
| · Design Spec | · 生成设计文档 | 20 | 0 |
| · Design Review | · 设计复审 | 20 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 15 |
| · Design | · 具体设计 | 20 | 30 |
| · Coding | · 具体编码 | 60 | 90 |
| · Code Review | · 代码复审 | 20 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 20 | 120 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 120 | 240 |
| · Size Measurement | · 计算工作量 | 20 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 90 |
| 合计 | 400 | 690 |
二、 解题思路
题目要求:文本读写、词频统计。
文本读写用io库 ,读入字符串后用正则表达式或者自己写字符串分割函数或者封装好的分割函数来获取单词,词频统计用HashMap存,结果排序一下输出。
三、 设计实现
流程图如下:
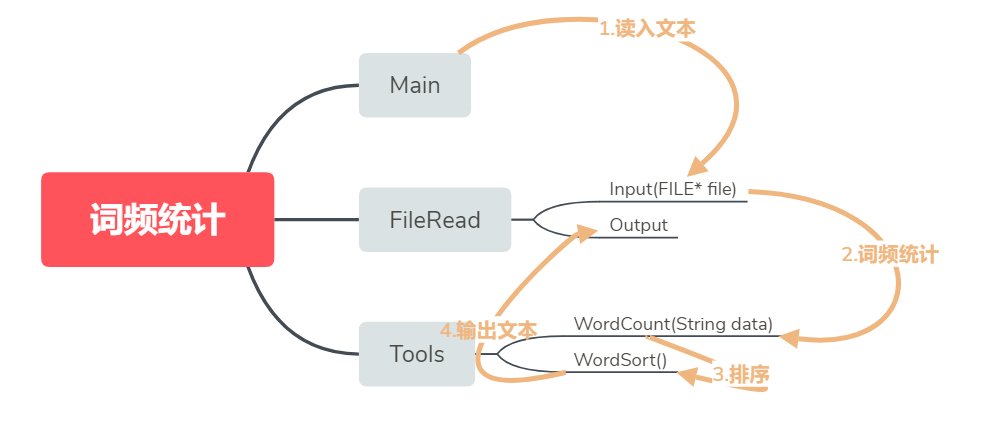
主函数里调用各个功能。
单元测试:每个函数依次测试,测试通过后;整合到主函数里;然后用命令行窗口进行整体功能测试。
四、改进程序
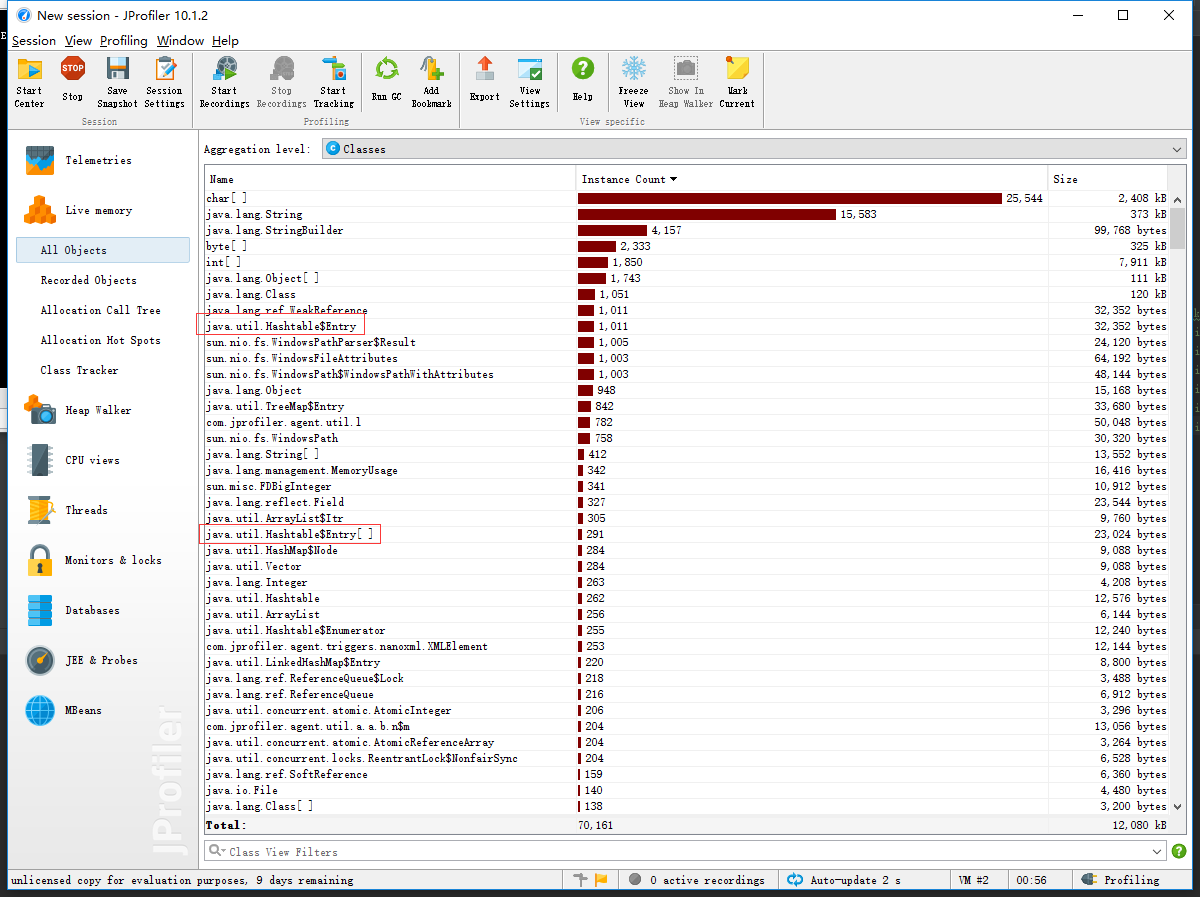

目前没怎么改进程序,由图中可以看见,Tool类之调用了一次,就是在主函数统计那一次。其余的就是排序跟文本读写,HashMap的插入与查找的性能消耗。
五、 代码说明
这是主函数,实现主要流程。
public class Main {
public static void main(String[] args) {
//文本读入
File file = new File(args[0]);
FileRead fileRead = new FileRead();
String data = fileRead.Input(file);
//处理文本
Tools tools = new Tools();
int length = data.length();
int wordAmount = tools.WordCount(data);
int lines = data.split("\n").length;
List<HashMap.Entry<String, Integer>> wordList = tools.WordSort();
//文本输出
fileRead.Output(length,wordAmount,lines,wordList);
}
}
Tool类中的词频统计:
调用了几个函数,StringTokenizer()——split()函数的加强版,也是用来分割字符串的;replaceAll()——替换部分非字母数字字符。
public int WordCount(String data){
int amount = 0;
String data_l = data.toLowerCase(); // 全部字母转小写。
String regex = "[^0-9a-zA-Z]"; //正则表达式,过滤非字母数字字符。
data_l = data_l.replaceAll(regex, " "); //清洗文本。
StringTokenizer words = new StringTokenizer(data_l); //分割文本成单词。
try {
while (words.hasMoreTokens()) {
String word = words.nextToken();
if (word.length() >= 4) { //判断单词长度是否大于等于4
if (Character.isLetter(word.charAt(0)) && Character.isLetter(word.charAt(1)) && Character.isLetter(word.charAt(2)) && Character.isLetter(word.charAt(3))) { //判断单词前4个是否为字母
amount++;
if (!wordCount.containsKey(word)) {
wordCount.put(word, new Integer(1));
} else {
int count = wordCount.get(word) + 1;
wordCount.put(word, count);
}
}
}
}
}catch (Exception e){
System.out.println("词频统计报错:");
System.out.println(e.getMessage());
}
return amount;
}
其他 FileRead就是一些文本处理,读与写。
具体见github。
六、异常处理
有基本的容错性:
根据输入的文件名找不到文件。

文件过大,会数组越界无法读入,现已修复。顺带优化了读写的速度。
找了一个日志文件测试了一下。

调优:

发现String通过"+"这种方法来拼接字符串是非常低效率的,于是用StringBuilder来代替。
附上几次的测试图:


七、总结
这次作业总体来说,花在写报告跟测试的时间比较多。而且对于词频统计这一问题来说,以前做过类似的oj题,但是算法题跟项目又是两码事,算法题只要做到最优能过测试就行,但是项目不一样。《构建之法》中提到的,“能证明所开发的软件是可以继续维护和发展的”,项目不仅仅做到满足用户需求,还要做到低耦合,无论是方便以后别人参与进来还是接手你的项目,都会更省时间。所以虽然花了很多时间,但是我觉得是有价值的。单元测试也是如此。
词频统计 ——Java的更多相关文章
- 如何用java完成一个中文词频统计程序
要想完成一个中文词频统计功能,首先必须使用一个中文分词器,这里使用的是中科院的.下载地址是http://ictclas.nlpir.org/downloads,由于本人电脑系统是win32位的,因此下 ...
- 词频统计的java实现方法——第一次改进
需求概要 原需求 1.读取文件,文件内包可含英文字符,及常见标点,空格级换行符. 2.统计英文单词在本文件的出现次数 3.将统计结果排序 4.显示排序结果 新需求: 1.小文件输入. 为表明程序能跑 ...
- 效能分析——词频统计的java实现方法的第一次改进
java效能分析可以使用JProfiler 词频统计处理的文件为WarAndPeace,大小3282KB约3.3MB,输出结果到文件 在程序本身内开始和结束分别加入时间戳,差值平均为480-490ms ...
- 【第二周】Java实现英语文章词频统计(改进1)
本周根据杨老师的spec对英语文章词频统计进行了改进 1.需求分析: 对英文文章中的英文单词进行词频统计并按照有大到小的顺序输出, 2.算法思想: (1)构建一个类用于存放英文单词及其出现的次数 cl ...
- Java实现的词频统计——Web迁移
本次将原本控制台工程迁移到了web工程上,依旧保留原本控制台的版本. 需求: 1.把程序迁移到web平台,通过用户上传TXT的方式接收文件: 2.在页面上给出链接 (如果有封皮.作者.字数.页数等信息 ...
- java词频统计——web版支持
需求概要: 1.把程序迁移到web平台,通过用户上传TXT的方式接收文件. 2.用户直接输入要统计的文本,服务器返回结果 3.在页面上给出链接 (如果有封皮.作者.字数.页数等信息更佳)或表格,展示经 ...
- java词频统计——改进后的单元测试
测试项目 博客文章地址:[http://www.cnblogs.com/jx8zjs/p/5862269.html] 工程地址:https://coding.net/u/jx8zjs/p/wordCo ...
- Java实现的词频统计——功能改进
本次改进是在原有功能需求及代码基础上额外做的修改,保证了原有的基础需求之外添加了新需求的功能. 功能: 1. 小文件输入——从控制台由用户输入到文件中,再对文件进行统计: 2.支持命令行输入英文作品的 ...
- Java实现中文词频统计
昨日有个中文词频统计的需求, 百度一番后, 发现一大堆标题党文章, 讲的与内容严重不符, 这里就简单记录下自己实现的流程吧! 与英文单词的词频统计不同, 中文的难点在于如何分词, 不过好在有许多优秀的 ...
随机推荐
- netty8---自定义编码解码器
package com.cn.codc; import org.jboss.netty.buffer.ChannelBuffer; import org.jboss.netty.channel.Cha ...
- Spring事务用法示例与实现原理
关于Java中的事务,简单来说,就是为了保证数据完整性而存在的一种工具,其主要有四大特性:原子性,一致性,隔离性和持久性.对于Spring事务,其最终还是在数据库层面实现的,而Spring只是以一种比 ...
- awk十三问-【AWK学习之旅】
---===AWK学习之旅===--- 十三个常用命令行处理 [root@monitor awkdir]# cat emp.txt Beth 4.00 0 Dan 3.75 0 Kathy 4.0 ...
- 20145307《信息安全系统设计基础》第五周学习总结PT2
20145307<信息安全系统设计基础>第五周学习总结PT2: 教材学习内容总结 之前有第一部分学习总结: http://www.cnblogs.com/Jclemo/p/5962219. ...
- java第一周学习总结
学号20145336 <Java程序设计>第1周学习总结 教材学习内容总结 java是sun推出的一门高级编程语言,现已经成为web开发的首选语言.他分为三种技术架构,j2ee针对web应 ...
- creator cocos2d-js-min.js 文件廋身 变小 太大解决方法
使用的 cocos creator 1.2 版本, 菜单栏 项目 -- 项目设置 -- 模块设置 里面 把不要的模块去掉
- [NOIP2017]时间复杂度
题目描述 小明正在学习一种新的编程语言 A++,刚学会循环语句的他激动地写了好多程序并 给出了他自己算出的时间复杂度,可他的编程老师实在不想一个一个检查小明的程序, 于是你的机会来啦!下面请你编写程序 ...
- No module named _sqlite3 django python manage.py runserver
linux 执行django(python manage.py runserver),报错No module named _sqlite3,需要安装sqlite-devel,再重新编译安装python ...
- 第七篇:Spark SQL 源码分析之Physical Plan 到 RDD的具体实现
/** Spark SQL源码分析系列文章*/ 接上一篇文章Spark SQL Catalyst源码分析之Physical Plan,本文将介绍Physical Plan的toRDD的具体实现细节: ...
- java.lang.IllegalArgumentException的解决方法
java.lang.IllegalArgumentException这个错误基本上就是jdk版本的问题 把jdk1.8换成jdk1.7就可以了 这里可以设置jdk最低版本 这里默认要选择jdk1.7 ...