Hadoop(HDFS、YARN、HBase、Hive和Spark等)默认端口表
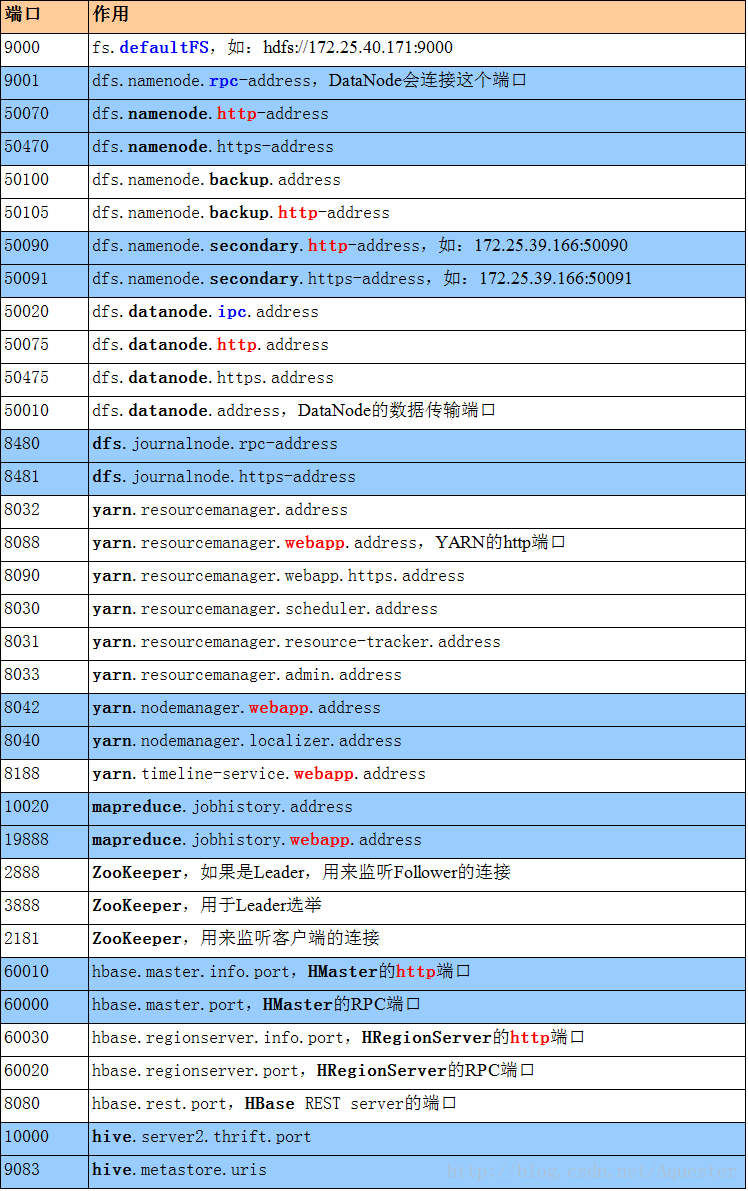
| 端口 | 作用 |
| 9000 | fs.defaultFS,如:hdfs://172.25.40.171:9000 |
| 9001 | dfs.namenode.rpc-address,DataNode会连接这个端口 |
| 50070 | dfs.namenode.http-address |
| 50470 | dfs.namenode.https-address |
| 50100 | dfs.namenode.backup.address |
| 50105 | dfs.namenode.backup.http-address |
| 50090 | dfs.namenode.secondary.http-address,如:172.25.39.166:50090 |
| 50091 | dfs.namenode.secondary.https-address,如:172.25.39.166:50091 |
| 50020 | dfs.datanode.ipc.address |
| 50075 | dfs.datanode.http.address |
| 50475 | dfs.datanode.https.address |
| 50010 | dfs.datanode.address,DataNode的数据传输端口 |
| 8480 | dfs.journalnode.rpc-address |
| 8481 | dfs.journalnode.https-address |
| 8032 | yarn.resourcemanager.address |
| 8088 | yarn.resourcemanager.webapp.address,YARN的http端口 |
| 8090 | yarn.resourcemanager.webapp.https.address |
| 8030 | yarn.resourcemanager.scheduler.address |
| 8031 | yarn.resourcemanager.resource-tracker.address |
| 8033 | yarn.resourcemanager.admin.address |
| 8042 | yarn.nodemanager.webapp.address |
| 8040 | yarn.nodemanager.localizer.address |
| 8188 | yarn.timeline-service.webapp.address |
| 10020 | mapreduce.jobhistory.address |
| 19888 | mapreduce.jobhistory.webapp.address |
| 2888 | ZooKeeper,如果是Leader,用来监听Follower的连接 |
| 3888 | ZooKeeper,用于Leader选举 |
| 2181 | ZooKeeper,用来监听客户端的连接 |
| 60010 | hbase.master.info.port,HMaster的http端口 |
| 60000 | hbase.master.port,HMaster的RPC端口 |
| 60030 | hbase.regionserver.info.port,HRegionServer的http端口 |
| 60020 | hbase.regionserver.port,HRegionServer的RPC端口 |
| 8080 | hbase.rest.port,HBase REST server的端口 |
| 10000 | hive.server2.thrift.port |
| 9083 | hive.metastore.uris |
Hadoop(HDFS、YARN、HBase、Hive和Spark等)默认端口表的更多相关文章
- hadoop集群的各部分一般都会使用到多个端口,有些是daemon之间进行交互之用,有些是用于RPC访问以及HTTP访问。而随着hadoop周边组件的增多,完全记不住哪个端口对应哪个应用,特收集记录如此,以便查询。这里包含我们使用到的组件:HDFS, YARN, Hbase, Hive, ZooKeeper:
组件 节点 默认端口 配置 用途说明 HDFS DataNode 50010 dfs.datanode.address datanode服务端口,用于数据传输 HDFS DataNode 50075 ...
- hadoop+yarn+hbase+storm+kafka+spark+zookeeper)高可用集群详细配置
配置 hadoop+yarn+hbase+storm+kafka+spark+zookeeper 高可用集群,同时安装相关组建:JDK,MySQL,Hive,Flume 文章目录 环境介绍 节点介绍 ...
- 大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
转自:http://blog.csdn.net/iamdll/article/details/20998035 分类: 分布式 2014-03-11 10:31 156人阅读 评论(0) 收藏 举报 ...
- 第十一章: Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
HDFS的体系架构 整个Hadoop的体系结构主要是通过HDFS来实现对分布式存储的底层支持,并通过MR来实现对分布式并行任务处理的程序支持. HDFS采用主从(Master/Slave)结构模型,一 ...
- Hadoop(HDFS,YARN)的HA集群安装
搭建Hadoop的HDFS HA及YARN HA集群,基于2.7.1版本安装. 安装规划 角色规划 IP/机器名 安装软件 运行进程 namenode1 zdh-240 hadoop NameNode ...
- Hadoop HDFS, YARN ,MAPREDUCE,MAPREDUCE ON YARN
HDFS 系统架构图 NameNode 是主节点,存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表和块所在的DataNode等.NameNode将 ...
- hadoop/hdfs/yarn 详细命令搬运
转载自文章 http://www.cnblogs.com/davidwang456/p/5074108.html 安装完hadoop后,在hadoop的bin目录下有一系列命令: container- ...
- Hadoop默认端口表及用途
端口 用途 9000 fs.defaultFS,如:hdfs://172.25.40.171:9000 9001 dfs.namenode.rpc-address,DataNode会连接这个端口 ...
随机推荐
- 论 html与css的关系
一.网页前端三剑客基础介绍 1-1 Html和CSS的关系学习web前端开发基础技术需要掌握:HTML.CSS.JavaScript语言.下面我们就来了解下这三门技术都是用来实现什么的: 1. HTM ...
- 【转】java与.net比较学习系列(3) 基本数据类型和类型转换
原文地址:https://www.cnblogs.com/mcgrady/p/3397874.html 阅读目录 一,整数类型 二,浮点数类型 三,字符类型 四,布尔类型 五,类型转换之自动转换 六, ...
- 20_java之集合Map
01Map集合概述 A:Map集合概述: 我们通过查看Map接口描述,发现Map接口下的集合与Collection接口下的集合,它们存储数据的形式不同 a:Collection中的集合,元素是孤立 ...
- 关于where和having的直观理解
一,查询区别 where是对前面select的字段没有要求,直接查询库表的 having是对前面的select的字段有要求,字段已经select出来的 可以用having进行处理 select id, ...
- codeforce 1070 E Getting Deals Done(二分求最大化最小值)
Polycarp has a lot of work to do. Recently he has learned a new time management rule: "if a tas ...
- GitHub个人使用入门
今天突然想起来了github 于是开始了入门之旅 如果你用过svn 那么你用起来感觉入门比较快的(至少我是这么感觉的)和在svn服务器上建项目的流程很像 每次修改代码之后提交的过程是: add, co ...
- 查看端口占用情况lsof,并关闭对应进程kill
lsof -n -P| grep ":<端口号>" | grep LISTEN #监听对应端口号的进程 lsof -i tcp:<端口号> #和对应端口号有 ...
- jquery中ready函数,$(function(){})与自执行函数的区别
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" ...
- Solo and Mute
[Solo and Mute ] Muting means a transition will be disabled. Soloed transtions are enabled and with ...
- Apache Hive (一)Hive初识
转自:https://www.cnblogs.com/qingyunzong/p/8707885.html Hive 简介 什么是Hive 1.Hive 由 Facebook 实现并开源 2.是基于 ...