MaperReduce实验
MaperReduce实现WordCount程序二次排序
前期准备
启动Zookeeper
./zkServer.sh start
启动HDFS
start-dfs.sh
启动Yarn
start-yarn.sh
将要处理的数据文件上传到HDFS
##这里数据文件名为wordcount.txt,目标存放路径为hdfs:/wc/srcdata/
##在HDFS根目录下创建wc目录
hadoop fs -mkdir /wc
##创建srcdata目录
hadoop fs -mkdir /wc/srcdata
##上传wordcount.txt
hadoop fs -put wordcount.txt /wc/srcdata
##不需要创建输出目录,否则会报错
1. 工程结构
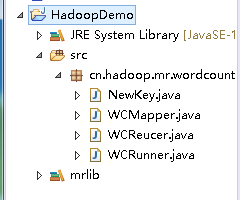
- 导入
common核心包及其依赖包 - 导入
mapreduce包及其依赖包 - 导入
tools包及其依赖
2. 编写自定义NewKey类
package cn.hadoop.mr.wordcount;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
/*
* newKey是自定义的数据类型,要在hadoop的各个节点之间传输,应该遵循hadoop的序列化机制
* 就必须实现hadoop相应的序列化接口
*/
public class NewKey implements WritableComparable<NewKey>{
private String word;
//反序列化时,反射机制需要调用空参构造函数,所以显示定义了一个空参构造函数
public NewKey() {}
//初始化对象
public NewKey(String word) {
this.word = word;
}
public String getWord() {
return word;
}
public void setWord(String word) {
this.word = word;
}
//从数据流中反序列化出对象的数据
//从数据流中读出对象字段时,必须与序列化时的顺序一致
@Override
public void readFields(DataInput in) throws IOException {
word = in.readUTF();
}
//将对象数据序列化到流中
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(word);
}
@Override
public String toString() {
return word;
}
//实现倒序排序
@Override
public int compareTo(NewKey o) {
return o.getWord().compareToIgnoreCase(word);
}
}
3. 编写WCMapper类
package cn.hadoop.mr.wordcount;
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
//四个泛型中,前两个时指定mapper输入数据的类型,KEYIN是输入的key的类型,VALUE是输入的value的类型
//map和reduce的数据输入输出都是以key-value对的形式封装的
//默认情况下,框架传递给我们的mapper的输入数据中,key是要处理的文本中一行的起始偏移量,这一行的内容作为value
//mapreduce框架将Long类型封装为可序列化的LongWriteble类型,String封装为Text
public class WCMapper extends Mapper<LongWritable, Text, NewKey, LongWritable>{
//mapreduce框架每读一行数据就调用一次该方法
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//具体的业务处理逻辑在该方法中编写,业务处理所需的数据由框架进行传递,在方法的参数中体现key-value
//key是这一行数据的起始偏移量,value是这一行的文本内容
//将这一行内容转化为string类型
String line=value.toString();
//调用Hadoop工具类对这一行文本按特定分隔符切分
String[] words = StringUtils.split(line," ");
//遍历单词数组输出到context中,输出为key-value形式,key为单词,value为1
for(String word:words) {
context.write(new NewKey(word), new LongWritable(1));
}
}
}
4. 编写WCReduer类
package cn.hadoop.mr.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Reducer;
public class WCReucer extends Reducer<NewKey, LongWritable, NewKey, LongWritable>{
//框架在map处理完成之后,缓存所有k-v对,根据k进行分组(相同k为同一组)后传递<key,value{}>,对每一组k调用一次reduce方法
//<hello,{1,1,1,1....}>
@Override
protected void reduce(NewKey key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count =0;
//遍历values进行累加求和
for(LongWritable value : values) {
count += value.get();
}
//输出这一个单词的统计结果
context.write(key, new LongWritable(count));
}
}
5. 编写作业描述类
package cn.hadoop.mr.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* 用来描述一个特定的作业
* 例如:
* 指定该作业所使用的map类和reduce类;
* 指定作业所需输入数据的存放路径;
* 指定作业输出结果存放路径
* @author Administrator
*
*/
public class WCRunner extends Configured implements Tool{
@Override
public int run(String[] arg0) throws Exception {
//配置文件
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//设置整个job所调用类的jar包路径
job.setJarByClass(WCRunner.class);
//设置该作业所使用的mapper和reducer类
job.setMapperClass(WCMapper.class);
job.setReducerClass(WCReucer.class);
//指定mapper输出数据的k-v类型,和reduce输出类型一样,可缺省
job.setMapOutputKeyClass(NewKey.class);
job.setOutputValueClass(LongWritable.class);
//指定reduce输出数据的k-v类型
job.setOutputKeyClass(NewKey.class);
job.setOutputValueClass(LongWritable.class);
//指定输入数据存放路径
FileInputFormat.setInputPaths(job, new Path(arg0[0]));
//指定输出数据存放路径
FileOutputFormat.setOutputPath(job, new Path(arg0[1]));
//将job提交给集群运行,参数为true表示提示运行进度
return job.waitForCompletion(true)?0:1;
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new WCRunner(), args);
System.exit(res);
}
}
6. 将工程打包
注:工程所使用的JDK版本必须和Hadoop所使用的JDK版本一致
``
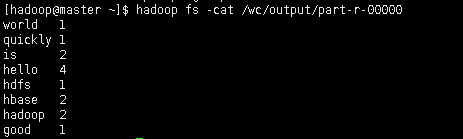
8. 查看输出结果
##查看指定的输出路径是否生成文件
hadoop fs -ls /wc/output
##查看运行结果
hadoop fs -cat /wc/output/part-r-00000
结果如图所示
MaperReduce实验的更多相关文章
- [原] 利用 OVS 建立 VxLAN 虚拟网络实验
OVS 配置 VxLAN HOST A ------------------------------------------ | zh-veth0(10.1.1.1) VM A | | ---|--- ...
- Android中Activity的四大启动模式实验简述
作为Android四大组件之一,Activity可以说是最基本也是最常见的组件,它提供了一个显示界面,从而实现与用户的交互,作为初学者,必须熟练掌握.今天我们就来通过实验演示,来帮助大家理解Activ ...
- SEED实验系列文章目录
美国雪城大学SEEDLabs实验列表 SEEDLabs是一套完整的信息安全实验,涵盖本科信息安全教学中的大部分基本原理.项目组2002年由杜文亮教授创建,目前开发了30个实验,几百所大学已采用.实验楼 ...
- 物联网实验4 alljoyn物联网实验之手机局域网控制设备
AllJoyn开源物联网协议框架,官方描述是一个能够使连接设备之间进行互操作的通用软件框架和系统服务核心集,也是一个跨制造商来创建动态近端网络的软件应用.高通已经将该项目捐赠给了一个名为“AllSee ...
- (转)linux下和云端通讯的例程, ubuntu和openwrt实验成功(一)
一. HTTP请求的数据流总结#上传数据, yeelink的数据流如下POST /v1.0/device/4420/sensor/9089/datapoints HTTP/1.1Host: api. ...
- (原创) alljoyn物联网实验之手机局域网控制设备
AllJoyn开源物联网协议框架,官方描述是一个能够使连接设备之间进行互操作的通用软件框架和系统服务核心集,也是一个跨制造商来创建动态近端网络的软件应用.高通已经将该项目捐赠给了一个名为“AllSee ...
- 实验:Oracle直接拷贝物理存储文件迁移
实验目的:Oracle直接拷贝物理文件迁移,生产库有类似施工需求,故在实验环境简单验证一下. 实验环境: A主机:192.168.1.200 Solaris10 + Oracle 11.2.0.1 B ...
- Oracle RAC 更换存储实验
实验环境准备: RHEL 6.5 + Oracle 11.2.0.4 RAC (2nodes) OCR和Voting Disk使用的是OCR1磁盘组,底层对应3个1G大小的共享LUN,一般冗余: DA ...
- Vertica集群扩容实验过程记录
需求: 将3个节点的Vertica集群扩容,额外增加3个节点,即扩展到6个节点的Vertica集群. 实验环境: RHEL 6.5 + Vertica 7.2.2-2 步骤: 1.三节点Vertica ...
随机推荐
- python发送邮件的实例代码(支持html、图片、附件)
转自http://www.jb51.net/article/34498.htm 第一段代码 #!/usr/bin/python# -*- coding: utf-8 -*- import emaili ...
- Roslyn 入门:使用 Roslyn 静态分析现有项目中的代码
Roslyn 是微软为 C# 设计的一套分析器,它具有很强的扩展性.以至于我们只需要编写很少量的代码便能够分析我们的项目文件. 作为 Roslyn 入门篇文章,你将可以通过本文学习如何开始编写一个 R ...
- vector 中的clear()
为什么clear之后,还是输出fdsafdsa.有什么办法可以真正清空之? 因为对于vector,clear并不真正释放内存(这是为优化效率所做的事),clear实际所做的是为vector中所保存的所 ...
- Vue生命周期函数详解
vue实例的生命周期 1 什么是生命周期(每个实例的一辈子) 概念:每一个Vue实例创建.运行.销毁的过程,就是生命周期:在实例的生命周期中,总是伴随着各种事件,这些事件就是生命周期函数: 生命周期: ...
- lapis 集成openresty最新版本cjson 问题的解决
备注: 为了解决安装了lapis.同时又希望使用新版nginx 以及openresty 的特性(stream ...) 1. 解决方法 参考: https://github.com/leaf ...
- Cocos2d-x学习笔记1
版权声明:本文为博主原创文章.未经博主同意不得转载. https://blog.csdn.net/u014734779/article/details/26077453 1.创建新的cocos2d-x ...
- c# 数据库通用类DbUtility
DbProviderType数据库类型枚举 /// <summary> /// 数据库类型枚举 /// </summary> public enum DbProviderTyp ...
- Eclipse中添加web dynamic project【菜鸟学JAVA】
很多eclipse版本是不能直接新建web dynamic project的,需要从网上找插件或更新.我的Eclipse的版本是(Version: 3.7.0) 比较方便的是在Help → Insta ...
- appium+python自动化28-name定位
前言 appium1.5以下老的版本是可以通过name定位的,新版本从1.5以后都不支持name定位了 name定位报错 1.最新版appium V1.7用name定位,报错: selenium.co ...
- java------------break;
总结: package com.mmm; public class Pnal { public static void main(String[] args) { int i = 0; while ( ...