StanFord ML 笔记 第一部分
本章节内容:
1.学习的种类及举例
2.线性回归,拟合一次函数
3.线性回归的方法:
A.梯度下降法--->>>批量梯度下降、随机梯度下降
B.局部线性回归
C.用概率证明损失函数(极大似然函数)
监督学习:有实际的输入和输出,给出标准答案做参照。比如:回归的运算,下面有例子。
非监督学习:内有标准答案,靠自己去计算。比如:聚类。
梯度下降法:
注释:以下直接复制Stanford课程的一位同学评论:super萝卜 [网易北京市海淀区网友]。
m代表训练样本的数量,number of training examples; n代表特征的数量(如房屋估价问题中房屋面积,卧室数量为特征,则n=2); x代表输入变量或者特征,input variables/features; y代表输出变量或目标变量,output variable/target ; variable; (x,y)代表一个样本
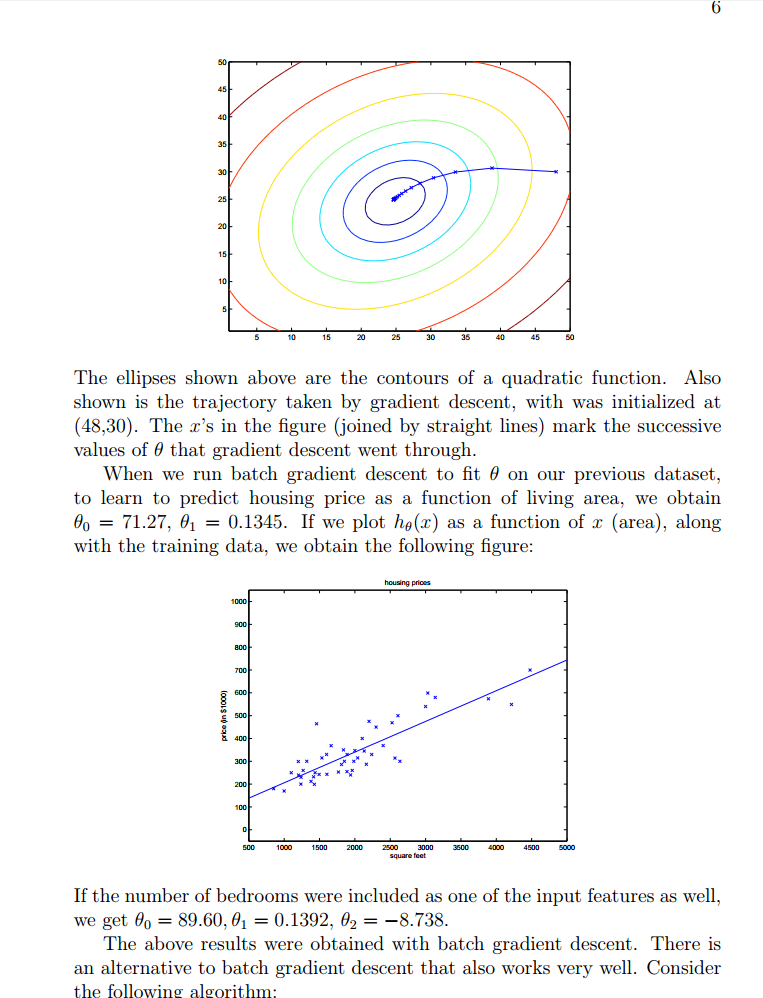
梯度下降的结果有时依赖于参数的初始值。(局部最优问题) 梯度下降法: θj := θj − α ∂(J(θ))/∂θj α:学习速率,控制收敛的速度,过小则需要花费太多时间收敛,过大则可能会跳过最小值部分。 当你接近局部最小值的时候,步子会越来越小,最终直到收敛,当达到局部最小值的时候,梯度值也会为0,所以当越来越接近局部最小值的时候,梯度值也是越来越小,梯度下降的步子也会越来越小。 检测收敛的方法:比较两次迭代的结果,看两次结果是否变化很多,最常见的还是检测J(θ)函数的值,如果该值没有很大变化,则认为达到收敛的效果。 梯度下降算法中,计算的梯度(偏导),事实上已经是梯度变化最大的方向。 随机梯度下降法:(大数据集合情况下) 并不会精确的收敛到全局最小值。会在最小值周围徘徊,得到近似的全局最小值。
Batch Gradient Descent ——批量梯度下降算法,每次迭代都会遍历整个训练集;不适于数据集很大。 stochastic gradient descent——随机梯度下降算法,每次迭代只会使用训练集的一个样本,比较快,不会精确的收敛到全局的最小值,在最小值附近徘徊。
gradient descent梯度下降 batch gradient descent 批梯度下降 stochastic gradient descent随机梯度下降(incremental gradient descent增量梯度下降):是对批梯度下降的一种改进,可以不必遍历所有的样本而得出收敛量,速度较快;缺点是无法得出精确的全局最小值;但是得出的收敛值很接近全局最小值,这对我们而言已经足够。
如何检测收敛,一种是检验两次迭代,看两次迭代中是否改变了很多。更多的是检验的值,如果视图最小化的量,不再发生大的改变,就可以认为收敛了。
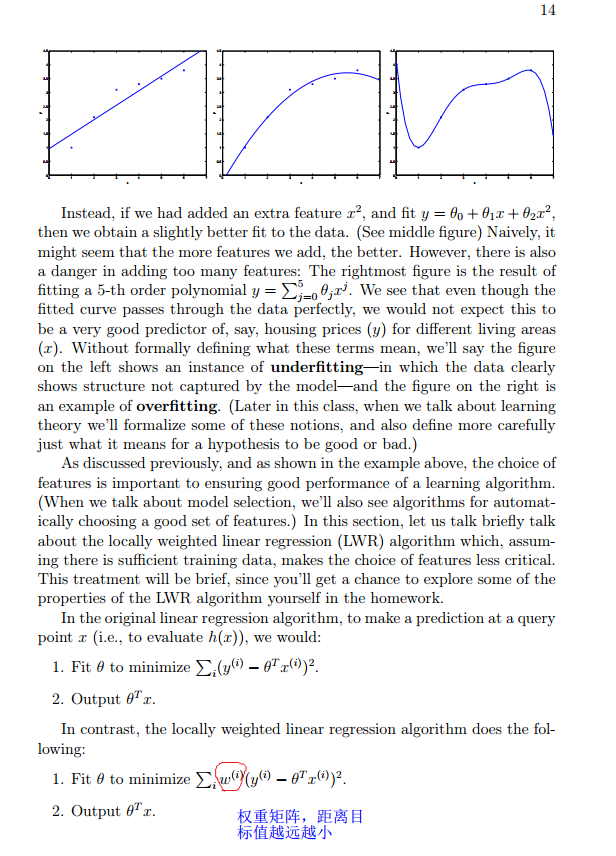
局部线性回归:
回忆一下高斯滤波比均值滤波的好处?第一:局部性。第二:空间性。局部性在于距离太远就等于没有权重W=0,空间性在于不同的距离权重不一样。
这篇博文讲的很清楚:http://blog.csdn.net/allenalex/article/details/16370245

中心极限定理:
设随机变量X1,X2,......Xn,......独立同分布,并且具有有限的数学期望和方差:E(Xi)=μ,D(Xi)=σ20(k=1,2....),则对任意x,分布函数都符合正太分布。
该定理说明,当n很大时,随机变量

近似地服从标准正态分布N(0,1)。
这里的作用是判断一个模型是否可以符合正太分布,下面课程的房价是一个不固定的因素受到天气、人的心情、道路等。。。因素影响,且这些特征都是独立的,所以可以把房价模型假设为正太分布,同时房价-预测=误差,那么误差也就是满足正太N(0,1)分布了。
似然函数:
应用在概率函数中,其实和概率函数差不多,就是一个数产生的概率函数,比如:

引申到“最大似然函数”:就是求最大概率下的参数。
知乎上这个解释感觉很完美:













StanFord ML 笔记 第一部分的更多相关文章
- StanFord ML 笔记 第三部分
第三部分: 1.指数分布族 2.高斯分布--->>>最小二乘法 3.泊松分布--->>>线性回归 4.Softmax回归 指数分布族: 结合Ng的课程,在看这篇博文 ...
- StanFord ML 笔记 第九部分
第九部分: 1.高斯混合模型 2.EM算法的认知 1.高斯混合模型 之前博文已经说明:http://www.cnblogs.com/wjy-lulu/p/7009038.html 2.EM算法的认知 ...
- StanFord ML 笔记 第八部分
第八部分内容: 1.正则化Regularization 2.在线学习(Online Learning) 3.ML 经验 1.正则化Regularization 1.1通俗解释 引用知乎作者:刑无刀 ...
- StanFord ML 笔记 第六部分&&第七部分
第六部分内容: 1.偏差/方差(Bias/variance) 2.经验风险最小化(Empirical Risk Minization,ERM) 3.联合界(Union bound) 4.一致收敛(Un ...
- StanFord ML 笔记 第五部分
1.朴素贝叶斯的多项式事件模型: 趁热打铁,直接看图理解模型的意思:具体求解可见下面大神给的例子,我这个是流程图. 在上篇笔记中,那个最基本的NB模型被称为多元伯努利事件模型(Multivariate ...
- StanFord ML 笔记 第十部分
第十部分: 1.PCA降维 2.LDA 注释:一直看理论感觉坚持不了,现在进行<机器学习实战>的边写代码边看理论
- StanFord ML 笔记 第四部分
第四部分: 1.生成学习法 generate learning algorithm 2.高斯判别分析 Gaussian Discriminant Analysis 3.朴素贝叶斯 Navie Baye ...
- StanFord ML 笔记 第二部分
本章内容: 1.逻辑分类与回归 sigmoid函数概率证明---->>>回归 2.感知机的学习策略 3.牛顿法优化 4.Hessian矩阵 牛顿法优化求解: 这个我就不记录了,看到一 ...
- 《javascript权威指南》读书笔记——第一篇
<javascript权威指南>读书笔记——第一篇 金刚 javascript js javascript权威指南 由于最近想系统学习下javascript,所以开始在kindle上看这本 ...
随机推荐
- C# 控件
.ascx:Web窗体用户控件.用来存放独立的用户控件,可提供众多页面使用: <%@ Control Language="C#" AutoEventWireup=" ...
- Hadoop的单机模式、伪分布式模式和完全分布式模式
1.单机(非分布式)模式 这种模式在一台单机上运行,没有分布式文件系统,而是直接读写本地操作系统的文件系统. 2.伪分布式运行模式 这种模式也是在一台单机上运行,但用不同的Java进程模仿分布式运行中 ...
- Elasticsearch的数据导出和导入操作(elasticdump工具),以及删除指定type的数据(delete-by-query插件)
Elasticseach目前作为查询搜索平台,的确非常实用方便.我们今天在这里要讨论的是如何做数据备份和type删除.我的ES的版本是2.4.1. ES的备份,可不像MySQL的mysqldump这么 ...
- DataGridView之编码列重绘
实现方式如下: private void dgvRelation_RowPostPaint(object sender, DataGridViewRowPostPaintEventArgs e) { ...
- 通过Word 2016 发布的内容
从Word 2007 开始就支持的功能的,第一次使用. 在cnBlogs.com的个人设置中允许使用客户端发布:https://i.cnblogs.com/Configure.aspx Word中配置 ...
- Java自定义数据验证注解Annotation
本文转载自:https://www.jianshu.com/p/616924cd07e6 Java注解Annotation用起来很方便,也越来越流行,由于其简单.简练且易于使用等特点,很多开发工具都提 ...
- Android 引用库项目,Debug 库项目
转自:http://www.cnblogs.com/xitang/p/3615768.html#commentform 使用引用项目,无法追到源代码,无法Debug库项目The JAR of this ...
- Svn过滤
http://blog.csdn.net/hemingwang0902/article/details/6904205
- 发现TCP的一种错误----客户端连接失败(10055错误号)
在客户端连接7302TCP端口失败,关闭程序,启动sockettool也不行,出现错误号为 10055(发现队列满了或者空间不足).通过查网上资料,发现有两个方法:设置 ( TcpTimedWaitD ...
- react路由传值
在上一篇总结了react中路由的基本用法,实现了基本的页面跳转,但这肯定是不够用的,比如说在新闻列表页面,点击某一条新闻,希望页面能跳转到新闻详情页,又该如何实现呢? 首先继续上一篇的项目,添加一个新 ...