【spring cloud】spring cloud Sleuth 和Zipkin 进行分布式链路跟踪
spring cloud 分布式微服务架构下,所有请求都去找网关,对外返回也是统一的结果,或者成功,或者失败。
但是如果失败,那分布式系统之间的服务调用可能非常复杂,那么要定位到发生错误的具体位置,就是一个比较麻烦的问题。
所以定位故障点,就引入了spring cloud Sleuth【Sleuth是猎犬的意思】 和Zipkin 【zipkin是一款开源的分布式数据跟踪系统】。
Spring Cloud Sleuth是对Zipkin的一个封装,对于Span、Trace等信息的生成、接入HTTP Request,以及向Zipkin Server发送采集信息等全部自动完成。
最后,你可以在zipkin的UI上看到一个比较完善的追踪结果和分析。
Zipkin提供了可插拔数据存储方式:In-Memory、MySql、Cassandra以及Elasticsearch。接下来的测试为方便直接采用In-Memory方式进行存储,生产推荐Elasticsearch。
一 、下面开始spring cloud集成步骤
【GitHub源码地址:https://github.com/AngelSXD/springcloud】
版本介绍:
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
<spring-boot.version>2.0.4.RELEASE</spring-boot.version>
<spring-cloud.version>Finchley.SR1</spring-cloud.version>
<lcn.last.version>4.2.1</lcn.last.version>
</properties>
1.创建ms-sleuth-zipkin 子服务,添加pom.xml架包依赖【标红部分,你们可以不需要,我的demo里正好需要才加的】
<!-- zipkin服务端 -->
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
<version>2.10.1</version>
<!--排除-->
<exclusions>
<exclusion>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- zipkin UI展示 -->
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
<version>2.10.1</version>
</dependency>
2.启动类加注解
package com.swapping.springcloud.ms.sleuth.zipkin; import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient;
import zipkin.server.internal.EnableZipkinServer; //启用Zipkin服务
@EnableZipkinServer @EnableEurekaClient
@SpringBootApplication(scanBasePackages = {"com.swapping"})
public class SpringcloudMsSleuthZipkinApp { public static void main(String[] args) {
SpringApplication.run(SpringcloudMsSleuthZipkinApp.class, args);
}
}
3.配置文件中配置基础的配置即可【如果启动zipkin之后,无法访问或者报错,参考:https://www.cnblogs.com/sxdcgaq8080/p/10007735.html】
spring.application.name=springcloud-ms-sleuth-zipkin
server.port=8002
eureka.client.service-url.defaultZone=http://127.0.0.1:8000/eureka/
#zipkin启动报错无法访问的解决方法
management.metrics.web.server.auto-time-requests=false
4.然后依次启动eureka服务,和zipkin服务即可
访问地址:【注意最后需要带上/】
http://localhost:8002/zipkin/
可以看到页面
5.接着,就是需要在zipkin自己服务中,和各个需要开启链路跟踪的服务的配置文件中添加配置 ,并且添加pom依赖
我是加载父级pom中,这样所有子module都可以用
<!-- zipkin 支持 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
配置【注意,spring boot 1.X的采样率配置是spring.sleuth.sampler.percentage=1】
【我在zipkin服务、ms-member服务、ms-gateway服务、ms-integral都做了添加】
#在需要链路的服务 以及 zipkin服务添加配置
spring.zipkin.base-url=http://localhost:8002
#采集率
spring.sleuth.sampler.probability=1.0
关于采样率的解释:
Spring Cloud Sleuth有一个Sampler策略,可以通过这个实现类来控制采样算法。采样器不会阻碍span相关id的产生,但是会对导出以及附加事件标签的相关操作造成影响。 Sleuth默认采样算法的实现是Reservoir sampling,具体的实现类是PercentageBasedSampler,默认的采样比例为: 0.1(即10%)。不过我们可以通过spring.sleuth.sampler.percentage来设置,所设置的值介于0.0到1.0之间,1.0则表示全部采集。
但是如果是全部采集的话,存储的性能需要考虑一下。
6.测试
ms-member有一个save的接口,自己做了save操作,并且feign调用了ms-integral服务做了save操作。【并且在最终ms-member中返回结果之前,抛出一个除零异常】
启动eureka
启动网关ms-gateway
启动ms-zipkin
启动ms-member
启动ms-integral
那么请求的流程就是 网关(ms-gateway)---->ms-member--->ms-integral 【每一个结点采集到的信息会由Sleuth 发送给zipkin服务】
访问地址:
http://localhost:8001/v1/ms-member/member/save?auth=111
访问接口完成后,访问zikpin的UI
http://localhost:8002/zipkin/
然后选择查看ms-gateway服务
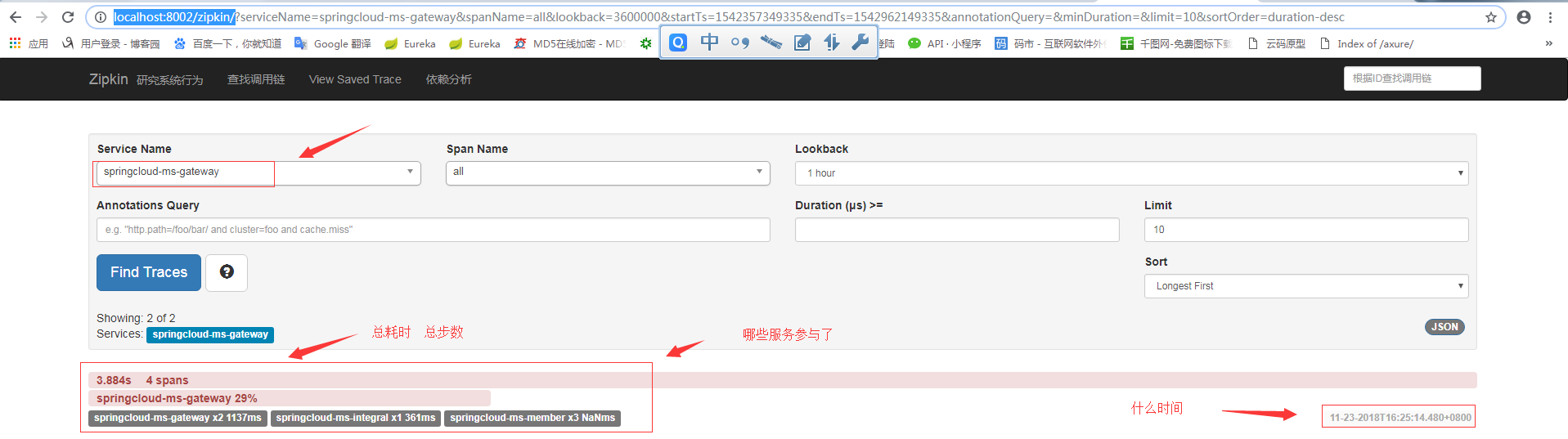
点击进去:
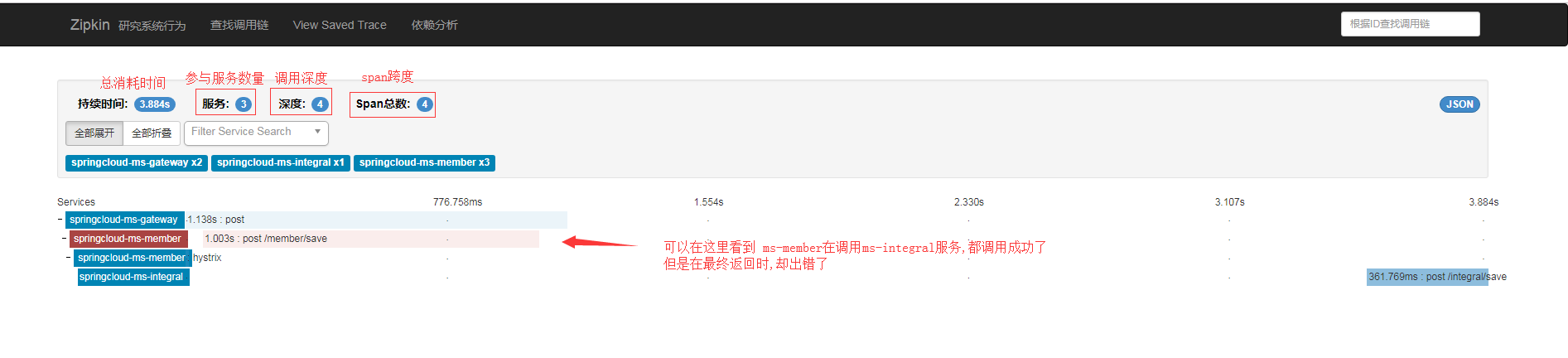
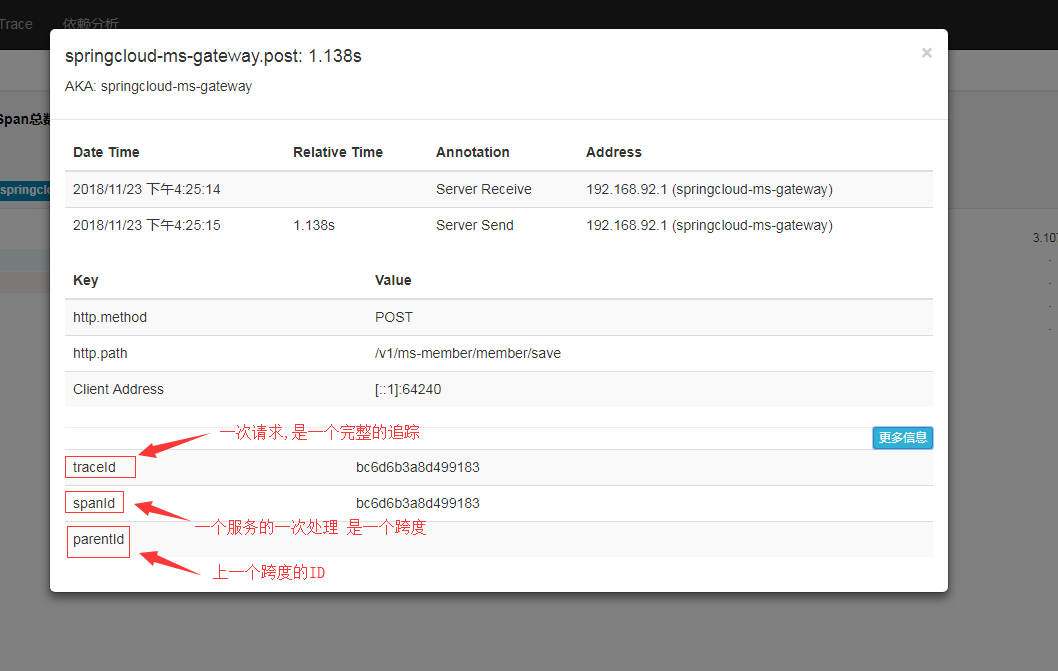
从进入gateway开始看,也就是请求的第一步:
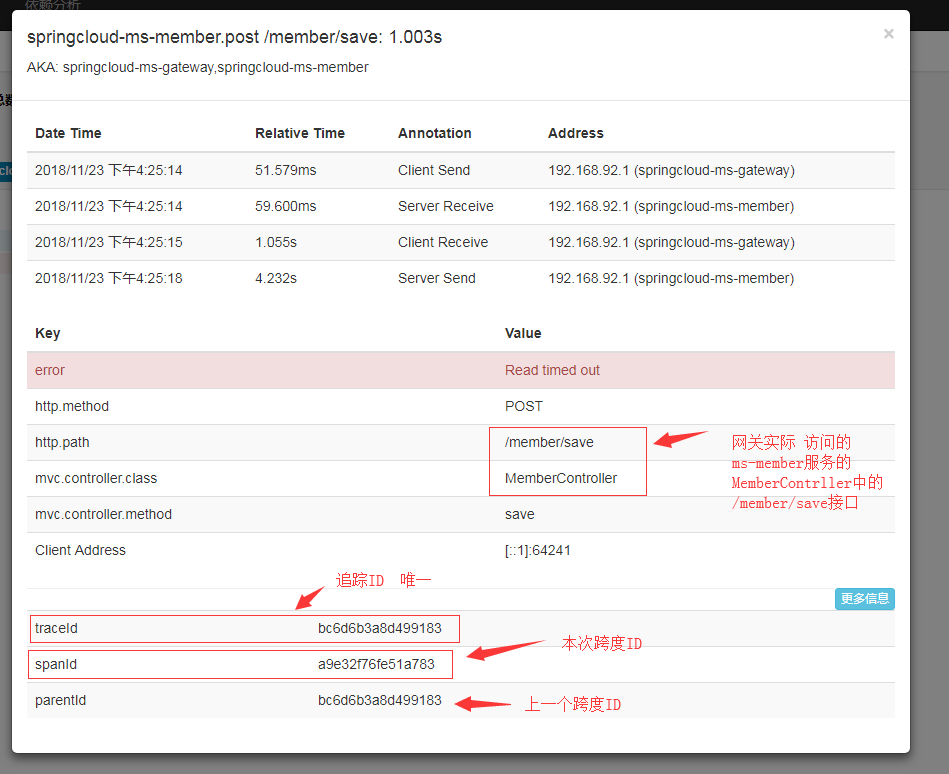
同时还可以看到:
点击依赖分析,还可以看到调用关系

二、Zipkin集成elasticsearch
【spring cloud】spring cloud Sleuth 和Zipkin 进行分布式链路跟踪的更多相关文章
- 跟我学SpringCloud | 第十一篇:使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪
SpringCloud系列教程 | 第十一篇:使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪 Springboot: 2.1.6.RELEASE SpringCloud: ...
- springcloud(十二):使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪
随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请求可能最终需要调用很多次后端服务才能完成,当整个请求变慢或不可用时,我们是无法得知该请求是由某个或某些后端服务引起的,这时就需要解决如何快读定位 ...
- 使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪
原文:http://www.cnblogs.com/ityouknow/p/8403388.html 随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请求可能最终需要调用很多次后端服务才能完成, ...
- spring cloud深入学习(十三)-----使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪
随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请求可能最终需要调用很多次后端服务才能完成,当整个请求变慢或不可用时,我们是无法得知该请求是由某个或某些后端服务引起的,这时就需要解决如何快读定位 ...
- Spring Cloud(十二):分布式链路跟踪 Sleuth 与 Zipkin【Finchley 版】
Spring Cloud(十二):分布式链路跟踪 Sleuth 与 Zipkin[Finchley 版] 发表于 2018-04-24 | 随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请 ...
- spring cloud 入门系列八:使用spring cloud sleuth整合zipkin进行服务链路追踪
好久没有写博客了,主要是最近有些忙,今天忙里偷闲来一篇. =======我是华丽的分割线========== 微服务架构是一种分布式架构,微服务系统按照业务划分服务单元,一个微服务往往会有很多个服务单 ...
- ⑦SpringCloud 实战:引入Sleuth组件,完善服务链路跟踪
这是SpringCloud实战系列中第7篇文章,了解前面第两篇文章更有助于更好理解本文内容: ①SpringCloud 实战:引入Eureka组件,完善服务治理 ②SpringCloud 实战:引入F ...
- 个推基于 Zipkin 的分布式链路追踪实践
作者:个推应用平台基础架构高级研发工程师 阿飞 01业务背景 随着微服务架构的流行,系统变得越来越复杂,单体的系统被拆成很多个模块,各个模块通过轻量级的通信协议进行通讯,相互协作,共同实现系统 ...
- 分布式链路跟踪系统架构SkyWalking和zipkin和pinpoint
Net和Java基于zipkin的全链路追踪 https://www.cnblogs.com/zhangs1986/p/8966051.html 在各大厂分布式链路跟踪系统架构对比 中已经介绍了几大框 ...
随机推荐
- MySQL学习笔记:delete
使用 SQL 的 DELETE FROM 命令来删除 MySQL 数据表中的记录. 语法: DELETE FROM table_name [WHERE Clause] 如果没有指定 WHERE 子句, ...
- 调研助力4S店,解码困境谜团
关键词————4S店.汽车.销售.精准营销.闭环.用户满意度.精细化管理 一.背景 4S店是“四位一体”的汽车销售专卖店,包括了整车销售.零配件供应.售后服务.信息反馈四项功能. 信息化管理 精细化管 ...
- 微信小程序实现左滑删除源码
左滑删除效果在app的交互方式中十分流行,比如全民应用微信 微信左滑删除 再比如曾引起很大反响的效率app Clear Clear左滑删除 从技术上来说,实现这个效果并不困难,响应一下滑动操作,移动一 ...
- 【58沈剑架构系列】为什么说要搞定微服务架构,先搞定RPC框架?
第一章聊了[“为什么要进行服务化,服务化究竟解决什么问题”] 第二章聊了[“微服务的服务粒度选型”] 今天开始聊一些微服务的实践,第一块,RPC框架的原理及实践,为什么说要搞定微服务架构,先搞定RPC ...
- 100+torch的基础操作
官网: torch 各种操作,做个翻译,以后查阅 Tensors torch.is_tensor 如果 obj 是 pytorch 张量,则返回 True. torch.is_storage ...
- 【LOJ】#2291. 「THUSC 2016」补退选
题解 在trie树上开vector记录一下这个前缀出现次数第一次达到某个值的下标,以及记录一下现在这个前缀有多少个 为什么thusc有那么水的题--是为了防我这种cai ji爆零么= = 代码 #in ...
- nodejs 项目,请求返回Invalid Host header问题
今天在linux上安装node,使用node做一个web服务器,在linux上安装各种依赖以后开始运行但是,出现了:Invalid Host header 的样式,在浏览器调试中发现是node返回的错 ...
- WMRouter:美团外卖Android开源路由框架
WMRouter是一款Android路由框架,基于组件化的设计思路,功能灵活,使用也比较简单. WMRouter最初用于解决美团外卖C端App在业务演进过程中的实际问题,之后逐步推广到了美团其他App ...
- sublime text3安装Package Control和Vue Syntax Highlight
一.下载Sublime3 https://www.sublimetext.com/3 二.安装Package Control 在线安装: https://packagecontrol.io/insta ...
- 说一说Servlet的生命周期
servlet有良好的生存期的定义,包括加载和实例化.初始化.处理请求以及服务结束.这个生存期由javax.servlet.Servlet接口的init,service和destroy方法表达. Se ...