Selenium2+python自动化37-爬页面源码(page_source)
前言
有时候通过元素的属性的查找页面上的某个元素,可能不太好找,这时候可以从源码中爬出想要的信息。selenium的page_source方法可以获取到页面源码。
selenium的page_source方法很少有人用到,小编最近看api不小心发现这个方法,于是突发奇想,这里结合python的re模块用正则表达式爬出页面上所有的url地址,可以批量请求页面url地址,看是否存在404等异常
一、page_source
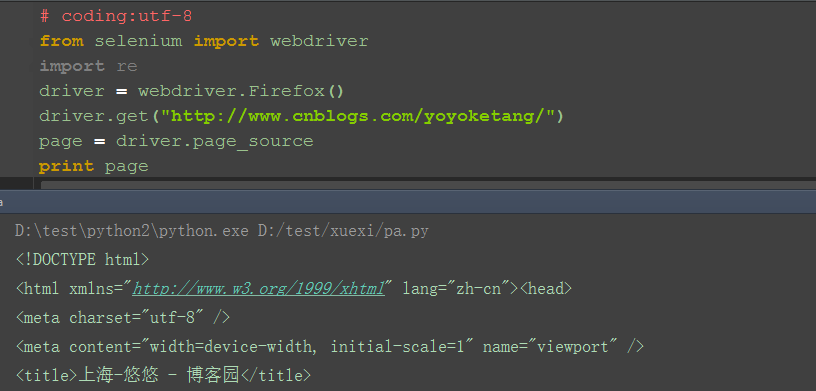
1.selenium的page_source方法可以直接返回页面源码
2.重新赋值后打印出来
二、re非贪婪模式
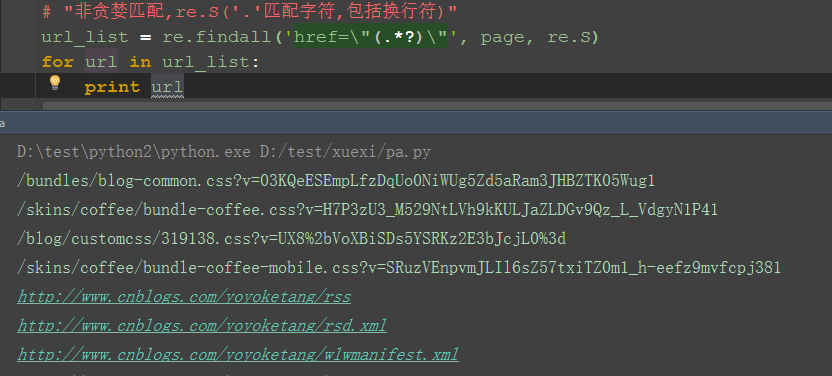
1.这里需导入re模块
2.用re的正则匹配:非贪婪模式
3.findall方法返回的是一个list集合
4.匹配出来之后发现有一些不是url链接,可以删选下
三、删选url地址出来
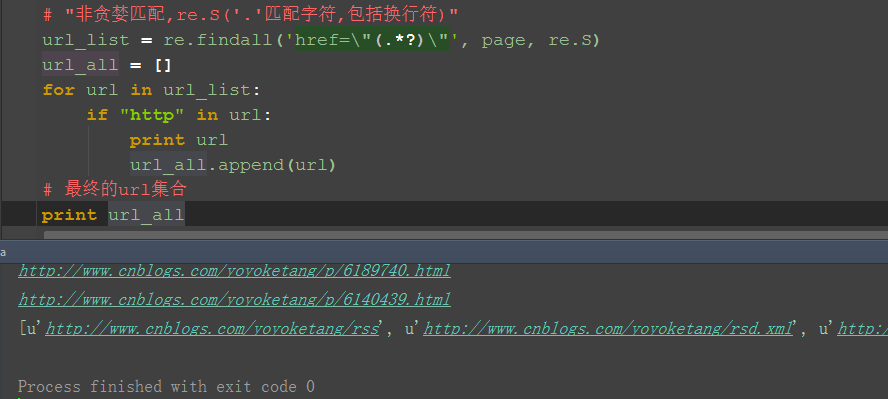
1.加个if语句判断,‘http’在url里面说明是正常的url地址了
2.把所有的url地址放到一个集合,就是我们想要的结果啦
四、参考代码
# coding:utf-8
from selenium import webdriver
import re
driver = webdriver.Firefox()
driver.get("http://www.cnblogs.com/yoyoketang/")
page = driver.page_source
# print page
# "非贪婪匹配,re.S('.'匹配字符,包括换行符)"
url_list = re.findall('href=\"(.*?)\"', page, re.S)
url_all = []
for url in url_list:
if "http" in url:
print url
url_all.append(url)
# 最终的url集合
print url_all
学习过程中有遇到疑问的,可以加selenium(python+java) QQ群交流:646645429
selenium+python高级教程》已出书:selenium webdriver基于Python源码案例
(购买此书送对应PDF版本)

Selenium2+python自动化37-爬页面源码(page_source)的更多相关文章
- selenium3+python3.6爬页面源码的代码
from selenium import webdriver import unittest,time class my_test(unittest.TestCase): def setUp(self ...
- 2.18 爬页面源码(page_source)
2.18 爬页面源码(page_source) 前言有时候通过元素的属性的查找页面上的某个元素,可能不太好找,这时候可以从源码中爬出想要的信息.selenium的page_source方法可以获取到页 ...
- Selenium2+python自动化13-Alert
不是所有的弹出框都叫alert,在使用alert方法前,先要识别出它到底是不是alert.先认清楚alert长什么样子,下次碰到了,就可以用对应方法解决.alert\confirm\prompt弹出框 ...
- Selenium2+python自动化64-100(大结局)[已出书]
前言 小编曾经说过要写100篇关于selenium的博客文章,前面的64篇已经免费放到博客园供小伙伴们学习,后面的内容就不放出来了,高阶内容直接更新到百度阅读了. 一.百度阅读地址: 1.本书是在线阅 ...
- Selenium2+python自动化37-爬页面源码(page_source)【转载】
前言 有时候通过元素的属性的查找页面上的某个元素,可能不太好找,这时候可以从源码中爬出想要的信息.selenium的page_source方法可以获取到页面源码. selenium的page_sour ...
- UI自动化之特殊处理四(获取元素属性\爬取页面源码\常用断言)
获取元素属性\爬取页面源码\常用断言,最终目的都是为了验证我们实际结果是否等于预期结果 目录 1.获取元素属性 2.爬取页面源码 3.常用断言 1.获取元素属性 获取title:driver.titl ...
- selenium3 + python - page_source页面源码
前言: 有时候通过元素的属性的查找页面上的某个元素,可能不太好找,这时候可以从源码中爬出想要的信息.selenium的page_source方法可以获取到页面源码. 本次以博客园为例,先爬取页面源码, ...
- Selenium2+python自动化39-关于面试的题
前言 最近看到群里有小伙伴贴出一组面试题,最近又是跳槽黄金季节,小编忍不住抽出一点时间总结了下, 回答不妥的地方欢迎各位高手拍砖指点. 一.selenium中如何判断元素是否存在? 首先selen ...
- Selenium2+python自动化39-关于面试的题【转载】
前言 最近看到群里有小伙伴贴出一组面试题,最近又是跳槽黄金季节,小编忍不住抽出一点时间总结了下, 回答不妥的地方欢迎各位高手拍砖指点. 一.selenium中如何判断元素是否存在? 首先selen ...
随机推荐
- 定制Eclipse
转载自http://chriszz.sinaapp.com 一般从Eclipse官网eclipse.org下载的,都是打包好的版本,比如标准版.jee版.java版.c++版.php版.测试版等.有时 ...
- Ubuntu 使用命令更新 Ubuntu 系统
我们都知道 Ubuntu 是一款 Linux 系统,是开源的系统,随时都在更新,所以人们都说 Linux 系统要比 Windows 系统安全.那么为了我们的电脑安全,我们如何利用 Ubuntu 命令来 ...
- Docker网络和存储
本节内容: Docker网络访问 端口映射 数据管理 一.Docker网络访问 1. docker自带的网络 docker network ls:列出当前docker中已有的网络 docker net ...
- 聊一聊FE面试那些事【原创】
最近公司由于业务的扩展.技术的延伸需要招一批有能力的小伙伴加入,而我有幸担任"技术面试官"的角色前前后后面试了不下50多位候选人,如同见证了50多位前端开发者的经历一样,在面试的过 ...
- ajax传递的参数服务器端接受不到的原因
最常见的就是组织的json数据格式有问题,尝试把单引号改为双引号试试,如下: $datares = {"uname":$uname.val(),"phone": ...
- 同步VDP时间
使用yast 进入蓝屏界面,修改system—date and time,取消hardware clock set to utc,时区设置为上海或者北京,然后sntp -r 时间服务器地址 敲击syn ...
- 解决python2.x文件读写编码问题
转自: https://xrlin.github.io/%E8%A7%A3%E5%86%B3python2.x%E6%96%87%E4%BB%B6%E8%AF%BB%E5%86%99%E7%BC%96 ...
- grunt自动化
1.安装模块 npm install grunt -g npm install grunt-cli -g #! --save-dev 既会把模块安装到项目node_modules下,也会安装到依赖文件 ...
- 社会主义核心价值观js代码
效果如下: 代码如下: <!DOCTYPE html> <html lang="en"> <head> <meta charset=&qu ...
- [BZOJ1815&BZOJ1488]有色图/图的同构(Polya定理)
由于有很多本质相同的重复置换,我们先枚举各种长度的点循环分别有多少个,这个暴搜的复杂度不大,n=53时也只有3e5左右.对于每种搜索方案可以轻易求出它所代表的置换具体有多少个. 但我们搜索的是点置换组 ...