Hadoop分布式远程Debug方式
1、进入目录修改配置文件
cd /cloud/hadoop-2.2.0/etc/hadoop
vim hadoop-env.sh
2、加入内容(文本最后):
#远程调试NameNode
export HADOOP_NAMENODE_OPTS="-agentlib:jdwp=transport=dt_socket,address=8888,server=y,suspend=y"
#远程调试DataNode
export HADOOP_DataNode_OPTS="-agentlib:jdwp=transport=dt_socket,address=9888,server=y,suspend=y"
注意其他可配置的参数:
hadoop远程debug配置
在/cloud/hadoop-2.2.0/etc/hadoop/hadoop-env.sh的最后面添加如下内容(可根据情况选择一个或多个)
#远程调试NameNode
export HADOOP_NAMENODE_OPTS="-agentlib:jdwp=transport=dt_socket,address=8888,server=y,suspend=y"
#远程调试DataNode
export HADOOP_DataNode_OPTS="-agentlib:jdwp=transport=dt_socket,address=9888,server=y,suspend=y"
#远程调试ResourceManager
export YARN_RESOURCEMANAGER_OPTS="-agentlib:jdwp=transport=dt_socket,address=10888,server=y,suspend=y"
#远程调试NodeManager
export YARN_NODEMANAGER_OPTS="-agentlib:jdwp=transport=dt_socket,address=11888,server=y,suspend=y"
3、退出到/root/cloud/hadoop-2.2.0/sbin目录下
A、cd sbin/ 目录下执行启动
B、启动方式:
(1)NameNode的启动命令
./hadoop-daemon.sh start namenode
成功返回:
starting namenode, logging to /root/cloud/hadoop-2.2.0/logs/hadoop-root-namenode-northbigpenguin.out
Listening for transport dt_socket at address: 8888
(2)DataNode的启动方式
./hadoop-daemon.sh start datanode
成功返回:
starting datanode, logging to /root/cloud/hadoop-2.2.0/logs/hadoop-root-datanode-northbigpenguin.out
Listening for transport dt_socket at address: 9888
C、关闭方式:
./hadoop-daemon.sh stop namenode
./hadoop-daemon.sh stop datanode
(1)设置断点 ,双击行号位置
(2)选择项目,找到需要调试的类,然后选择debug----->Debug Congratulation
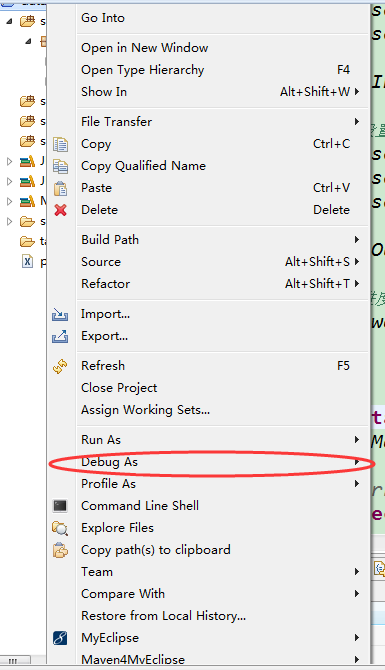

(3)进入如图位置,然后按照如图的参数进行配置,然后选择Apply----->Debug,就可以开始Debug了

Hadoop分布式远程Debug方式的更多相关文章
- hadoop分布式安装教程(转)
from:http://www.cnblogs.com/xia520pi/archive/2012/05/16/2503949.html 1.集群部署介绍 1.1 Hadoop简介 Hadoop是Ap ...
- Hadoop分布式HA的安装部署
Hadoop分布式HA的安装部署 前言 单机版的Hadoop环境只有一个namenode,一般namenode出现问题,整个系统也就无法使用,所以高可用主要指的是namenode的高可用,即存在两个n ...
- 第3章:Hadoop分布式文件系统(1)
当数据量增大到超出了单个物理计算机存储容量时,有必要把它分开存储在多个不同的计算机中.那些管理存储在多个网络互连的计算机中的文件系统被称为"分布式文件系统".由于这些计算机是基于网 ...
- 分布式计算(一)Ubuntu搭建Hadoop分布式集群
最近准备接触分布式计算,学习分布式计算的技术栈和架构知识.目前的分布式计算方式大致分为两种:离线计算和实时计算.在大数据全家桶中,离线计算的优秀工具当属Hadoop和Spark,而实时计算的杰出代表非 ...
- [大数据学习研究] 3. hadoop分布式环境搭建
1. Java安装与环境配置 Hadoop是基于Java的,所以首先需要安装配置好java环境.从官网下载JDK,我用的是1.8版本. 在Mac下可以在终端下使用scp命令远程拷贝到虚拟机linux中 ...
- HBase二次开发之搭建HBase调试环境,如何远程debug HBase源代码
版本 HDP:3.0.1.0 HBase:2.0.0 一.前言 之前的文章也提到过,最近工作中需要对HBase进行二次开发(参照HBase的AES加密方法,为HBase增加SMS4数据加密类型).研究 ...
- 【Java远程debug】
转自 http://blog.csdn.net/hongchangfirst/article/details/44191925 一.远程debug原理 Java远程调试的原理是两个JVM之间通过deb ...
- 攻城狮在路上(陆)-- hadoop分布式环境搭建(HA模式)
一.环境说明: 操作系统:Centos6.5 Linux node1 2.6.32-431.el6.x86_64 #1 SMP Fri Nov 22 03:15:09 UTC 2013 x86_64 ...
- 远程debug调试java代码
远程debug调试java代码 日常环境和预发环境遇到问题时,可以用远程调试的方法本地打断点,在本地调试.生产环境由于网络隔离和系统稳定性考虑,不能进行远程代码调试. 整体过程是通过修改远程服务JAV ...
随机推荐
- MySQL优化order by导致的 using filesort
using filesort 一般出现在 使用了 order by 语句当中. using filesort不一定引起mysql的性能问题.但是如果查询次数非常多,那么每次在mysql中进行排序,还是 ...
- vue基础——vue实例
创建一个vue实例 每个vue应用都是通过Vue函数创建一个新的Vue实例开始的 var vm = new Vue({ //选项 }) 一个Vue应用由一个通过new Vue创建的根Vue实例,以及可 ...
- PL/SQL Developer安装教程以及汉化包安装教程
一.安装PL/SQL 1.百度下载plsql破解版软件,官网只能使用30天 2.双击plsqldev906.exe进行安装,点击 iagree 3.默认是安装在c盘,可以根据自己需要更改安装目录 4. ...
- import 语句用于导入从外部模块,另一个脚本等导出的函数,对象或原语。
import 语句用于导入从外部模块,另一个脚本等导出的函数,对象或原语. 注意:此功能目前无法在任何浏览器中实现.它在许多转换器中实现,例如 Traceur Compiler , Babel , R ...
- redis数据迁移
redis的备份和还原,借助了第三方的工具---redis-dump, redis中使用redis-dump导出.导入.还原数据实例 1.安装redis-dump # yum install rub ...
- PHP与apache配置
在apache 的安装路径中找到 \conf\httpd.conf文件 在 LoadModule最后面添加如下代码: PHPIniDir "D:\PHP"LoadModule ph ...
- 获取iframe内的元素
$("#iframeID").contents().find("#index_p") 2获取父窗体的值 $('#father', parent.document ...
- linux安装本地blast
1)wget ftp://ftp.ncbi.nlm.nih.gov/blast/executables/blast+/2.8.0alpha/ncbi-blast-2.8.0-alpha+-x64-li ...
- mysql优化连接数
很多开发人员都会遇见”MySQL: ERROR 1040: Too many connections”的异常情况,造成这种情况的一种原因是访问量过高,MySQL服务器抗不住,这个时候就要考虑增加从服务 ...
- function方法控制是否隐藏部分内容
$(document).ready(function() { $('input[type=radio][name=IE]').change(function() { if (this.value == ...