泰坦尼克(Titanic)生存因素可视化
- 数据来源: kaggle
- 分析工具:Python 3.6 & jupyter notebook
- 附上数据:链接: https://pan.baidu.com/s/1D7JNvHmqTIw0OoPXBWzWHA 提取码: hdtt
- 本篇分析比较基础,集中于清洗和可视化,欢迎各路大神指正
#设置jupyter可以打印多条结果
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
#导入包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#导入数据
df=pd.read_csv('titanic_data.csv')
df.head()
# passengerId:旅客 id;survived:0 代表遇难,1 代表存活;pclass:舱位,1-3 分别代表一二三等舱;
# name:旅客姓名;sex:旅客性别;age:年龄;
# sibsp:船上的同代亲属人数,如兄弟姐妹;parch:船上的非同代亲属人数,如父母子女;
# ticket:船票编号;fare:船票价格;cabin:客舱号;embarked:登船港口

猜测生存率跟以下因素有关
1.pclass:客舱等级,一等舱可能有大部分权贵
2.sex:性别,lady first
3.age:年龄,尊老爱幼,通用的道德规范
4.sibsp:同代亲属,可能亲属多的获救概率更大
5.parch:非同代亲属,可能会让父母子女先得救
6.fare:船票价格,反应经济能力和社会地位,跟客舱等级存在关联
# 数据量以及大小,缺失值
df.info()
df.shape

- 结论:数据总量 891 条,12 列,age 列缺失 177 条数据,因为尊老爱幼也是一个通用的道德规范,因此考虑 age 对生存率会有影响,后续可能需要填充; cabin 舱号对生存考虑无影响,缺失影响不大
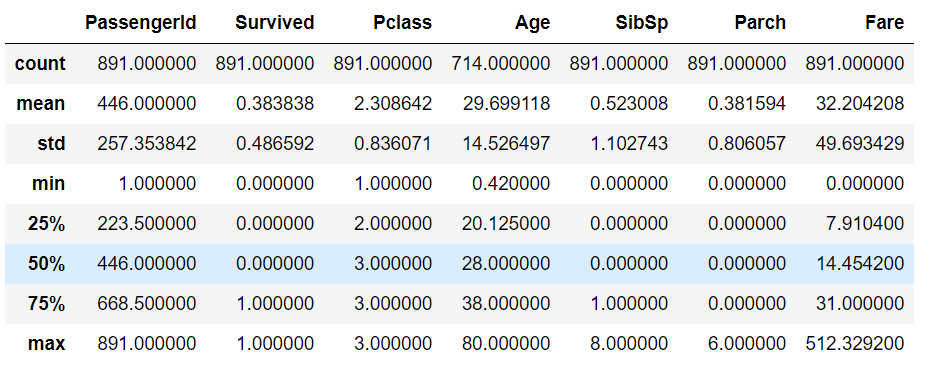
# 数据汇总统计
df.describe()
# 整体生存情况
survived=df['Survived'].value_counts()
survived

# 可以看到,891 人中,只有342人存活
# 计算生存比例
survived_perc=survived / survived.sum()
survived_perc
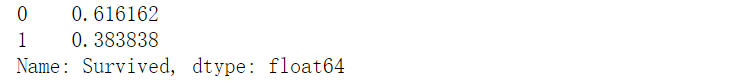
# 绘制饼图
plt.rc('font',family='Arial Unicode MS',size=15) #设置字体
fig=plt.figure(1,figsize=(7,7)) #设置画布
ax1=fig.add_subplot(1,1,1) #生成子图
label=['遇难','存活']
color=['#C0C0C0','#F5DEB3']
explode=0.05,0.05 #扇区间隔
ax1.pie(survived_perc,labels=label,colors=color,startangle=90,autopct='%3.2f%%',explode=explode,shadow=True)
ax1.set_title('整体生存情况')

# 性别与生存情况
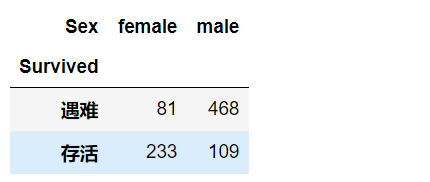
sex=df.groupby(['Survived','Sex']).size()
sex

# 转换为 dataframe
sex=sex.unstack('Sex')
sex=sex.rename(index={0:'遇难',1:'存活'})
sex
# 计算生存比例
sex_perc=sex / sex.sum()
sex_perc

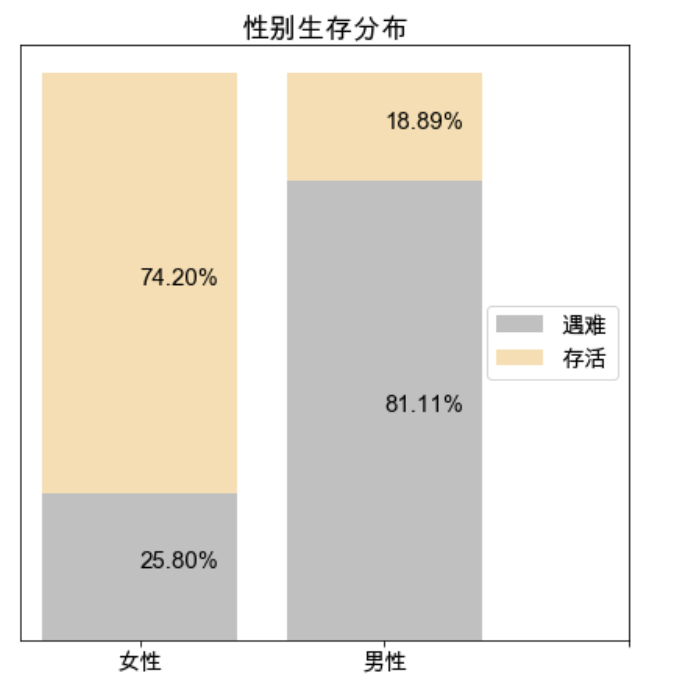
- 从结果看,女性遇难 81 人,存活率约 75%,男性存活 109人,存活率不到 20%
# 绘制条形堆叠图
plt.rc('font',family='Arial Unicode MS',size=15) #设置字体
fig=plt.figure(1,figsize=(7,7)) #设置画布
ax1=fig.add_subplot(1,1,1) #生成子图
x=range(2)
a=sex_perc.loc['遇难',:]
b=sex_perc.loc['存活',:]
ax1.bar(x,a,label='遇难',color='#C0C0C0')
ax1.bar(x,b,bottom=a,label='存活',color='#F5DEB3') #通过bottom参数绘制堆积柱状图
ax1.set_xticks(range(3)) #设置x轴刻度,之所以设置为3,是为了让图例显示在空白处
ax1.set_xticklabels(['女性','男性']) #设置x轴刻度标签名称
ax1.set_yticks([])
ax1.legend(['遇难','存活'],loc='center right') #设置图例名称及位置
ax1.set_title('性别生存分布') #设置标题
#添加数据标签
for x,y,z in zip(range(2),a,b):
ax1.text(x,y/2,'{:.2%}'.format(y))
ax1.text(x,y+z/2,'{:.2%}'.format(z))
# 年龄分布
age_df=df.loc[:,['Survived','Age']]
age_df.head()

#对年龄分组,从前面的描述性统计可以看到,年龄的最小值是0.42岁,最大值是80岁
bins=[0,20,40,60,100]
labels=['20岁及以下','21-40岁','41-60岁','60岁以上']
age_df['levels']=pd.cut(age_df['Age'],bins=bins,labels=labels)
age_df.head()

# 遇难/存活人员的年龄分布
age_level=age_df.groupby(['Survived','levels']).size()
age_level

# 可以看到在遇难和存活的人中,都是21-40岁的人巨多
# 转为 dataframe
age_level=age_level.unstack()
age_level=age_level.rename(index={0:'遇难',1:'存活'})
age_level
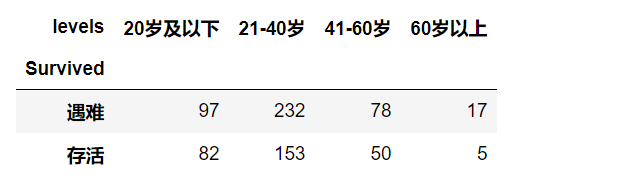
# 计算比例
age_perc=age_level/age_level.sum()
age_perc
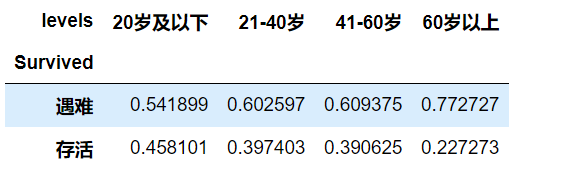
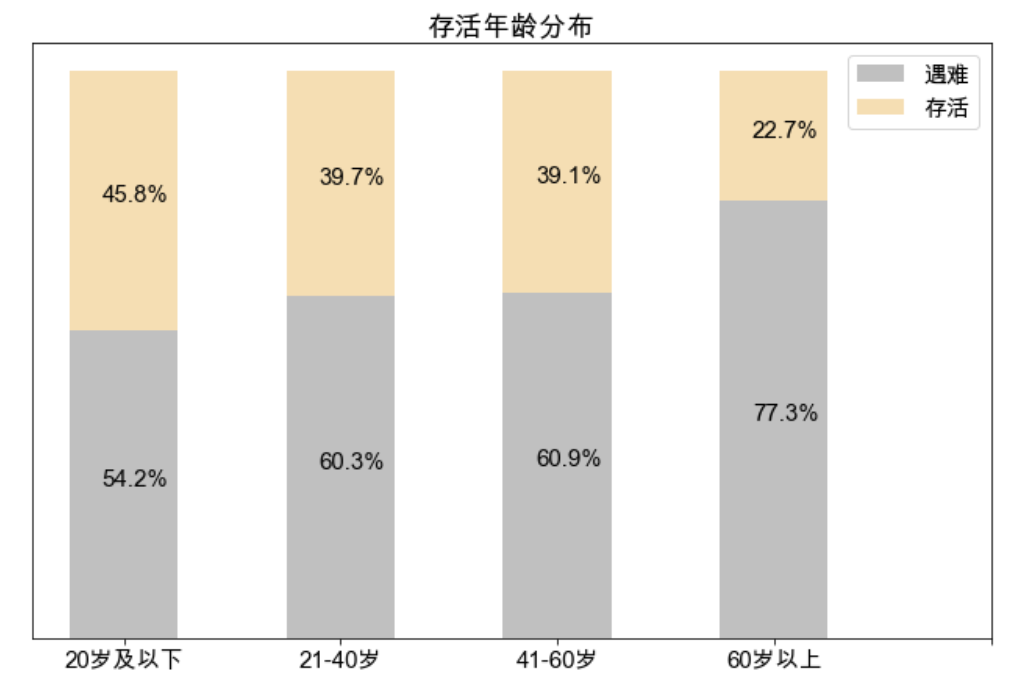
- 可以看到随着年龄的增加,存活比例逐渐降低,在天灾面前,大家还是会把生的希望更多的让给年轻人
plt.rc('font',family='Arial Unicode MS',size=15) #设置字体
fig=plt.figure(1,figsize=(11,7)) #设置画布
ax1=fig.add_subplot(1,1,1) #添加子图
x=range(4)
a=age_perc.loc['遇难',:]
b=age_perc.loc['存活',:]
ax1.bar(x,a,label='遇难',width=0.5,color='#C0C0C0')
ax1.bar(x,b,bottom=a,label='存活',width=0.5,color='#F5DEB3')
ax1.set_xticks(range(5)) # x轴刻度
ax1.set_xticklabels(['20岁及以下','21-40岁','41-60岁','60岁以上'])
ax1.set_yticks([])
ax1.legend(['遇难','存活'],loc='upper right')
ax1.set_title('存活年龄分布')
for x,y,z in zip(range(4),a,b):
ax1.text(x-0.1,y/2,'{:,.1%}'.format(y))
ax1.text(x-0.1,y+z/2,'{:,.1%}'.format(z))
# 家庭人数分布
df['familysize']=df['SibSp']+df['Parch']+1
family_df=df.loc[:,['Survived','familysize']]
family_df.head()
# 按人数分箱
bins=[0,1,3,12]
labels=['small','medium','large']
family_df['family_level']=pd.cut(family_df['familysize'],bins=bins,labels=labels) #左开右闭
family_df.head()

family_df=family_df.groupby(['Survived','family_level']).size()
family_df
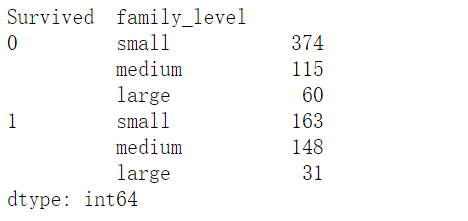
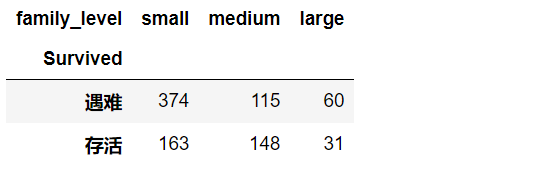
family_df=family_df.unstack()
family_df=family_df.rename(index={0:'遇难',1:'存活'})
family_df
family_perc=family_df/family_df.sum()
family_perc

plt.rc('font',family='Arial Unicode MS',size=15)
fig=plt.figure(figsize=(8,5))
ax1=fig.add_subplot(1,1,1)
y=range(3)
a=family_perc.loc['遇难',:]
b=family_perc.loc['存活',:]
ax1.barh(y,a,label='遇难',height=0.5,color='#C0C0C0')
ax1.barh(y,b,left=a,label='存活',height=0.5,color='#F5DEB3')
ax1.set_yticks(range(4))
ax1.set_yticklabels(['small','medium','large'])
ax1.set_xticks([])
ax1.legend(['遇难','存活'],loc='upper right')
ax1.set_title('不同家庭规模存活分布')
for x,y,z in zip(range(4),a,b):
ax1.text(y/2,x,'{:.1%}'.format(y))
ax1.text(y+z/2,x,'{:.1%}'.format(x))
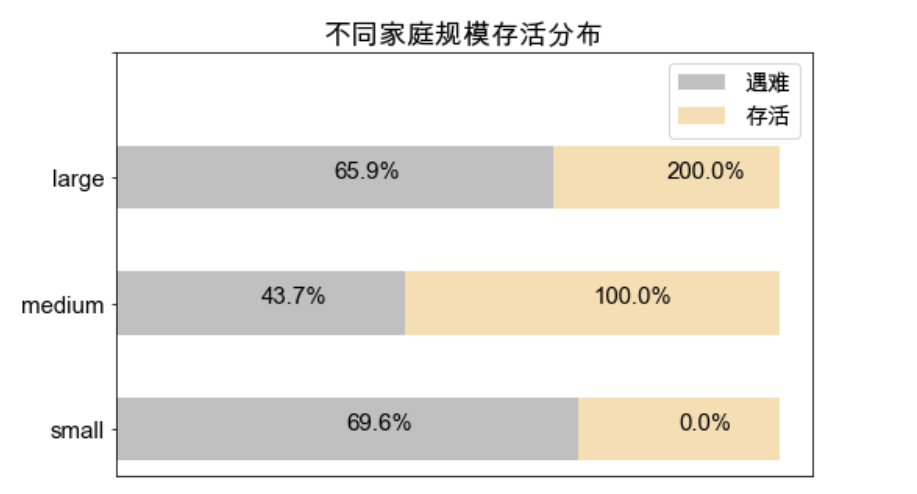
- 可以看到,船上亲属只有一个人,无其他亲属时,存活率最高,将近 70%
# 舱位等级分布
pclass_df=df.loc[:,['Survived','Pclass']]
pclass_df.head()
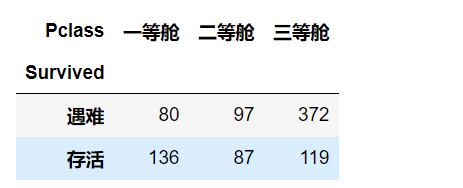
pclass_df=pclass_df.groupby(['Survived','Pclass']).size()
pclass_df

pclass_df=pclass_df.unstack()
pclass_df=pclass_df.rename({0:'遇难',1:'存活'},columns={1:'一等舱',2:'二等舱',3:'三等舱'})
pclass_df
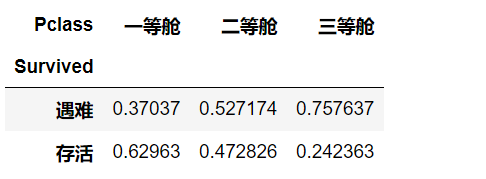
pclass_perc=pclass_df/pclass_df.sum()
pclass_perc
plt.rc('font',family='Arial Unicode MS',size=15)
fig=plt.figure(figsize=(8,5))
ax1=fig.add_subplot(1,1,1)
y=range(3)
a=pclass_perc.loc['遇难',:]
b=pclass_perc.loc['存活',:]
ax1.barh(y,a,label='遇难',height=0.5,color='#C0C0C0')
ax1.barh(y,b,left=a,label='存活',height=0.5,color='#F5DEB3')
ax1.set_yticks(range(4))
ax1.set_yticklabels(['一等舱','二等舱','三等舱'])
ax1.set_xticks([])
ax1.legend(['遇难','存活'],loc='upper right')
ax1.set_title('不同舱位等级存活分布')
for x,y,z in zip(range(4),a,b):
ax1.text(y/2,x,'{:.1%}'.format(y))
ax1.text(y+z/2,x,'{:.1%}'.format(z))

- 可以看到,舱位等级与存活率还是有很显著的关系,一等舱存活率63%,远大于三等舱存活率
# 船票价格存活分布,预计与舱位等级结果相似,不过注意到描述性统计里,价格最大为 512,最小为 0,存在很明显的异常值,还是做一下异常值处理
# 提取价格不为 0 的记录
fare_df=df.loc[df['Fare']>0,['Survived','Fare']]
fare_df.head()

# 平均票价
fare_df.groupby('Survived')['Fare'].mean()

# 票价分箱
bins=[0,10,30,50,100,513]
labels=['≤10','10-30','30-50','50-100','100以上']
fare_df['level']=pd.cut(fare_df['Fare'],bins=bins,labels=labels)
fare_df.head()
# 存活与否与票价分组
fare_df=fare_df.groupby(['Survived','level']).size()
fare_df

# 转 dataframe
fare_df=fare_df.unstack()
fare_df=fare_df.rename(index={0:'遇难',1:'存活'})
fare_df

# 计算比例
fare_perc=fare_df/fare_df.sum()
fare_perc

plt.rc('font',family='Arial Unicode MS',size=15)
fig=plt.figure(figsize=(11,8)) #画布大小
ax1=fig.add_subplot(1,1,1) #添加子图
y=range(5)
a=fare_perc.loc['遇难',:]
b=fare_perc.loc['存活',:]
ax1.barh(y,a,label='遇难',height=0.5,color='#C0C0C0')
ax1.barh(y,b,left=a,label='存活',height=0.5,color='#F5DEB3') #left:柱状堆积图
ax1.set_yticks(range(6))
ax1.set_yticklabels(['≤10','10-30','30-50','50-100','100以上']) #y轴刻度标签
ax1.set_xticks([]) #x轴刻度为空
ax1.legend(['遇难','存活'],loc='upper right') #图例名称及位置(upper/center/lower,left/center/right)
ax1.set_title('不同票价等级存活分布')
#添加标签
for x,y,z in zip(range(5),a,b):
ax1.text(y/2,x,'{:.1%}'.format(y))
ax1.text(y+z/2,x,'{:.1%}'.format(z))
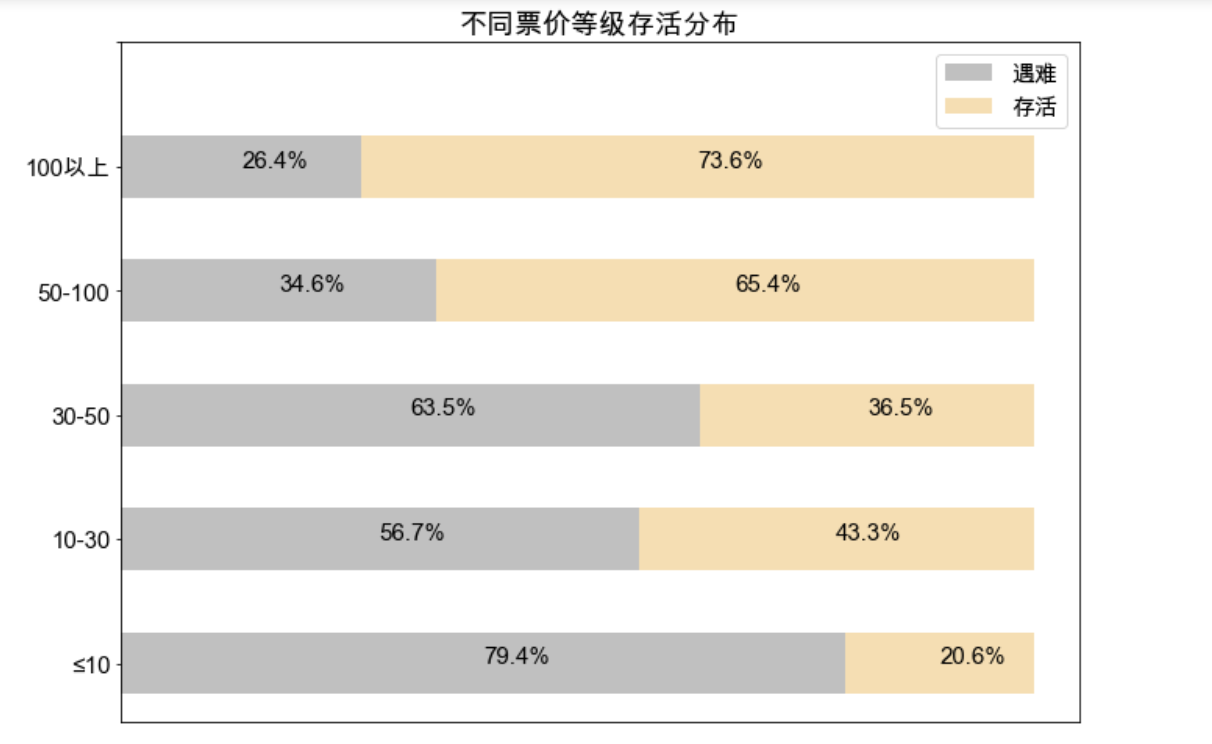
- 可以看到,票价在 50 以上存活率超过65%,与前面舱位等级结果基本一致
# 从各个舱位等级的平均票价来看,一等舱存活率最高,其平均票价也是最高的,为 84
df.groupby('Pclass')['Fare'].mean()

泰坦尼克(Titanic)生存因素可视化的更多相关文章
- 利用python进行泰坦尼克生存预测——数据探索分析
最近一直断断续续的做这个泰坦尼克生存预测模型的练习,这个kaggle的竞赛题,网上有很多人都分享过,而且都很成熟,也有些写的非常详细,我主要是在牛人们的基础上,按照数据挖掘流程梳理思路,然后通过练习每 ...
- Kaggle 泰坦尼克
入门kaggle,开始机器学习应用之旅. 参看一些入门的博客,感觉pandas,sklearn需要熟练掌握,同时也学到了一些很有用的tricks,包括数据分析和机器学习的知识点.下面记录一些有趣的数据 ...
- Kaggle泰坦尼克数据科学解决方案
原文地址如下: https://www.kaggle.com/startupsci/titanic-data-science-solutions --------------------------- ...
- kaggle之泰坦尼克的沉没
Titanic 沉没 参见:https://github.com/lijingpeng/kaggle 这是一个分类任务,特征包含离散特征和连续特征,数据如下:Kaggle地址.目标是根据数据特征预测一 ...
- Kaggle_泰坦尼克乘客存活预测
转载 逻辑回归应用之Kaggle泰坦尼克之灾 此转载只为保存!!! ————————————————版权声明:本文为CSDN博主「寒小阳」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附 ...
- pytorch kaggle 泰坦尼克生存预测
也不知道对不对,就凭着自己的思路写了一个 数据集:https://www.kaggle.com/c/titanic/data import torch import torch.nn as nn im ...
- Forest plot(森林图) | Cox生存分析可视化
本文首发于“生信补给站”微信公众号,https://mp.weixin.qq.com/s/2W1W-8JKTM4S4nml3VF51w 更多关于R语言,ggplot2绘图,生信分析的内容,敬请关注小号 ...
- Kaggle试水之泰坦尼克灾难
比赛地址:https://www.kaggle.com/c/titanic 再次想吐槽CSDN,编辑界面经常卡死,各种按钮不能点,注释的颜色不能改,很难看清.写了很多卡死要崩溃. 我也是第一次参加这个 ...
- Kaggle泰坦尼克-Python(建模完整流程,小白学习用)
参考Kernels里面评论较高的一篇文章,整理作者解决整个问题的过程,梳理该篇是用以了解到整个完整的建模过程,如何思考问题,处理问题,过程中又为何下那样或者这样的结论等! 最后得分并不是特别高,只是到 ...
随机推荐
- Eclipse创建第一个Servlet(Dynamic Web Project方式)、第一个Web Fragment Project(web容器向jar中寻找class文件)
创建第一个Servlet(Dynamic Web Project方式) 注意:无论是以注解的方式还是xml的方式配置一个servlet,servlet的url-pattern一定要以一个"/ ...
- logback.xml配置示例
需要的jar如下: <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api< ...
- 第六章 函数、谓词、CASE表达式 6-1 各种各样的函数
一.函数的种类 算术函数 字符串函数 日期函数 转换函数 聚合函数 二.算术函数 + - * / 1.ABS——绝对值 ABS(数值) 绝对值 absolute value ,不考虑数值的符号 ...
- JavaScript运行机制的学习
今天在偶然在网上看到一个JavaScript的面试题,尝试着看了一下,很正常的就做错了,然后给我们前端做,哈哈,他居然也顺理成章做的错了,代码大概是这样的 /*1 下面代码会怎样执行?执行结果是什么* ...
- SQL 中Count()的问题
假如一张表中有如下的数据: 当使用select Count(*) from TableName表示获取表中数据记录的条数: 有时候可以通过select Count(列名) from TableName ...
- CompletionService和ExecutorCompletionService
CompletionService用于提交一组Callable任务,其take方法返回已完成的一个Callable任务对应的Future对象. 如果你向Executor提交了一个批处理任务,并且希 ...
- sudo实例--企业生产环境用户权限集中管理方案实例
根据角色的不同,给不同的用户分配不同的角色1.创建初级工程师3个,网络工程师1个,中级工程师1个,经理1个 # 批量创建用户 for user in chuji{01..03} net01 ...
- Linux wget命令详解
wget是一个下载文件的工具,它用在命令行下.对于Linux用户是必不可少的工具,我们经常要下载一些软件或从远程服务器恢复备份到本地服务器. wget支持HTTP,HTTPS和FTP协议,可以使用HT ...
- Linux /dev/null详解
常用的命令展示 /dev/null 和 /dev/zero的区别 1./dev/null:表示 的是一个黑洞,通常用于丢弃不需要的数据输出, 或者用于输入流的空文件 ...
- 【原创】由于python的导入方式引起的深坑
目录结构: test/ sacc/ __init__.py app.py logger.py /views __init__.py main.py 事情是这样的,logger里面是一个类LoggerF ...