利用python进行泰坦尼克生存预测——数据探索分析
最近一直断断续续的做这个泰坦尼克生存预测模型的练习,这个kaggle的竞赛题,网上有很多人都分享过,而且都很成熟,也有些写的非常详细,我主要是在牛人们的基础上,按照数据挖掘流程梳理思路,然后通过练习每一步来熟悉应用python进行数据挖掘的方式。
数据挖掘的一般过程是:数据预览——>数据预处理(缺失值、离散值等)——>变量转换(构造新的衍生变量)——>数据探索(提取特征)——>训练——>调优——>验证
1 数据预览
1.1 head()
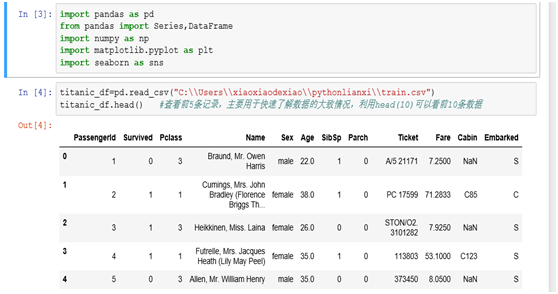
预览数据集的前面几条数据可以大致看看每个字段的值究竟长什么样。
1.2 info()
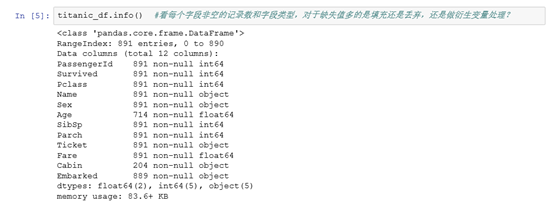
可以看每个字段有多少非空值,字段的类型是什么样的
1.3 describe()
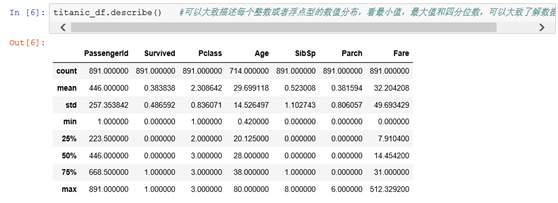
可以大致描述每个整数或者浮点型的数值分布,看最小值,最大值和四分位数,可以大致了解数据的偏移情况。
2.数据预处理
从前面数据预览中发现年龄(age)、船舱号(Cabin)、登岸口(Embarked)有数据的缺失。
登岸口通过后面的数据探索可以发现只有3个值,而且缺失的数量也不大,因此这里填充为众数。
船舱号只有204个有值,一般来说,缺失比例较大的特征可以考虑舍弃,而这里联想到缺失是否表示乘客的票本身就没有船舱号,就像我们买的无座票一样,本身就没有座位号,因此这里先填充为0

年龄字段也存在缺失,一般来说,老弱病残幼是要受到特殊照顾的,因此年龄应该会是一个比较重要的特征,并且因为它是连续值,这里采用算法预测的方式来进行填充。

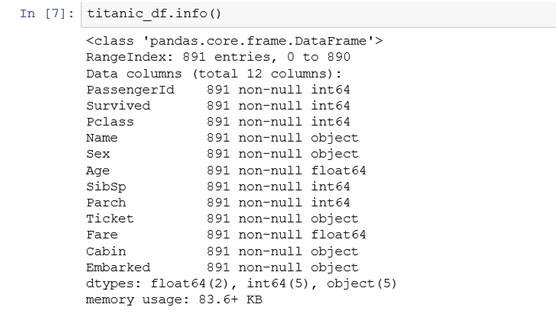
最后我们来看一下填充后的数据情况
3.数据探索
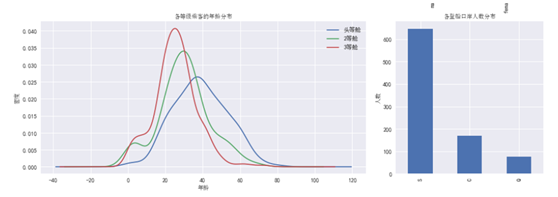
3.1 各个字段值的分布情况
先看代码:
以上是画布相关设置
subplots_adjust()是用来调整画布内子图的间隔大小的。


以上是在画布相应位置画各个子图的代码。图形如下:
3.2 探索各字段与是否生存的关系,寻找对模型有用的特征
3.2.1 不同乘客等级与是否生存的关系

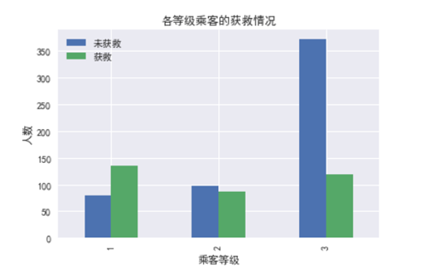
舱位越高级的,生存的比例越大。3等舱里面未获救的比例明显增大。说明舱位与是否生存有关系。
3.2.2 性别与是否生存的关系

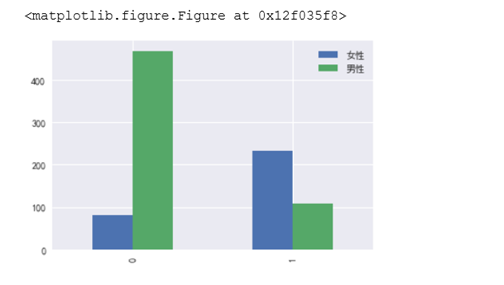
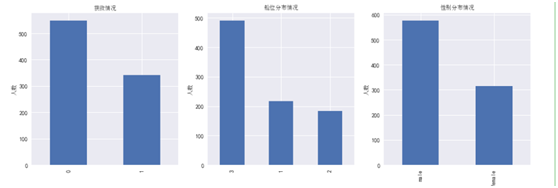
从数据上看,获救的女性比例很高,电影里面也说了女士优先,因此性别与是否生存也有较大关系。
3.2.3 年龄与是否生存的关系
首先看一下年龄的分布情况和值的离散情况

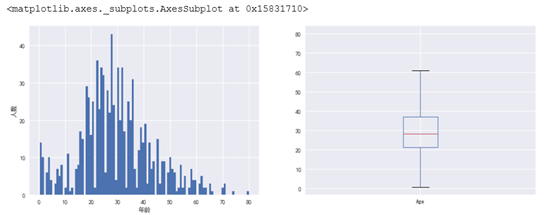
从图中可以发现大部分都是集中在20-50岁之间的,从箱线图看平均年龄接近30岁。
因为年龄是连续值,因此我们考虑把年龄分段后,进行分段统计展示看年龄与是否生存的关系。

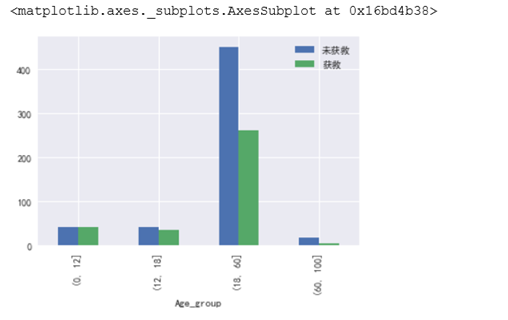
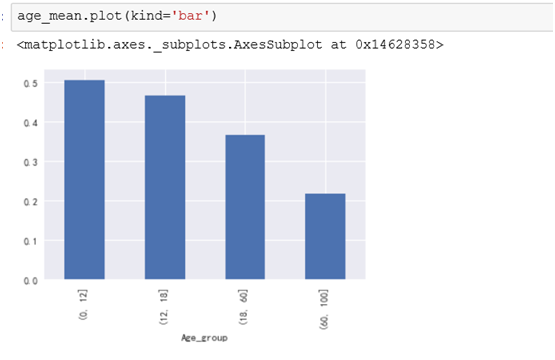
从数据上年纪小的生存的几率要大些。不同年龄段的生存率明显有差别,说明年龄与是否生存是有关系的。
3.2.4 有无兄弟姐妹与是否生存的关系

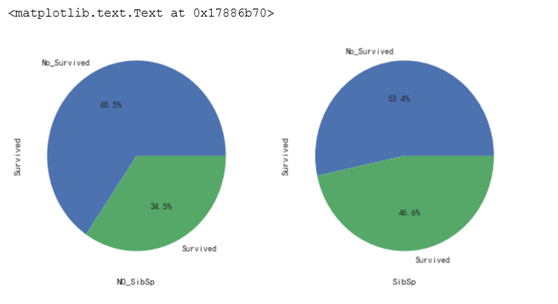
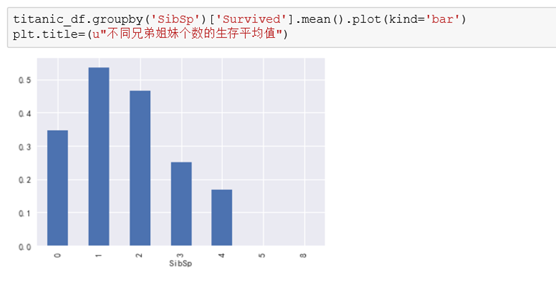
从数据上看兄弟姐妹在1-2个的生存率最高
3.2.5是否有父母子女与是否生存的关系

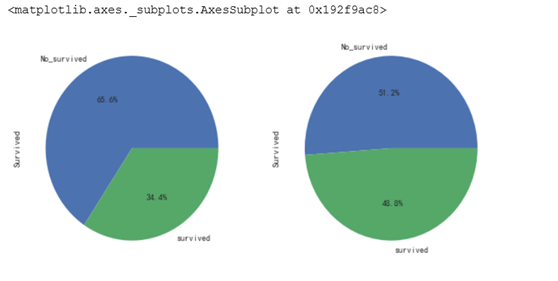
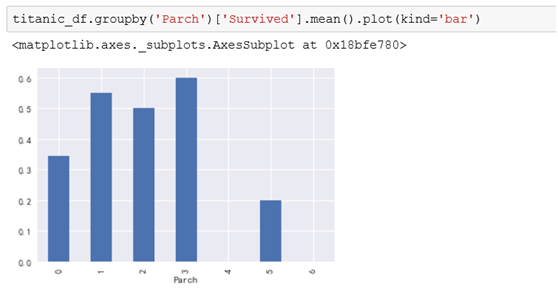
数据显示父母子女个数在1-3个的生存率最高,个数越多反倒生存率下降。
3.2.6 港口与是否生存的关系
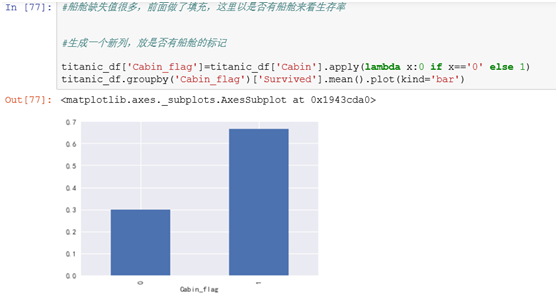
数据显示有港口的生存率明显高很多。可能是船中间有停靠到一些港口,有部分乘客下船了。
本文参考:大树先生的博客
利用python进行泰坦尼克生存预测——数据探索分析的更多相关文章
- pytorch kaggle 泰坦尼克生存预测
也不知道对不对,就凭着自己的思路写了一个 数据集:https://www.kaggle.com/c/titanic/data import torch import torch.nn as nn im ...
- Kaggle初体验之泰坦尼特生存预测
Kaggle初体验之泰坦尼特生存预测 学习完了决策树的ID3.C4.5.CART算法,找一个试手的地方,Kaggle的练习赛泰坦尼特很不错,记录下 流程 首先注册一个账号,然后在顶部菜单栏Co ...
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 利用python爬取58同城简历数据
利用python爬取58同城简历数据 利用python爬取58同城简历数据 最近接到一个工作,需要获取58同城上面的简历信息(http://gz.58.com/qzyewu/).最开始想到是用pyth ...
- 利用Python进行数据分析_Pandas_处理缺失数据
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 1 读取excel数据 import pandas as pd import ...
- python数据处理(七)之数据探索和分析
1.探索数据 1.1 安装agate库 1.2 导入数据 1.3 探索表函数 a.排序 b.最值,均值 c.清除缺失值 d.过滤 e.百分比 1.4 连结多个数据集 a.捕捉异常 b.去重 c.缺失数 ...
- 利用Python进行数据分析 第8章 数据规整:聚合、合并和重塑.md
学习时间:2019/11/03 周日晚上23点半开始,计划1110学完 学习目标:Page218-249,共32页:目标6天学完(按每页20min.每天1小时/每天3页,需10天) 实际反馈:实际XX ...
- 利用Python进行数据分析 第6章 数据加载、存储与文件格式(2)
6.2 二进制数据格式 实现数据的高效二进制格式存储最简单的办法之一,是使用Python内置的pickle序列化. pandas对象都有一个用于将数据以pickle格式保存到磁盘上的to_pickle ...
- Spark学习笔记——泰坦尼克生还预测
package kaggle import org.apache.spark.SparkContext import org.apache.spark.SparkConf import org.apa ...
随机推荐
- 【左偏树+延迟标记+拓扑排序】BZOJ4003-城池攻占
[题目大意] 有n个城市构成一棵树,除1号城市外每个城市均有防御值h和战斗变化参量a和v. 现在有m个骑士各自来刷副本,每个其实有一个战斗力s和起始位置c.如果一个骑士的战斗力s大于当前城市的防御值h ...
- [NOIp2016提高组]天天爱跑步
题目大意: 有一棵n个点的树,每个点上有一个摄像头会在第w[i]秒拍照. 有m个人再树上跑,第i个人沿着s[i]到t[i]的路径跑,每秒钟跑一条边. 跑到t[i]的下一秒,人就会消失. 问每个摄像头会 ...
- lightoj 1244 - Tiles 状态DP
思路:状态DP dp[i]=2*dp[i-1]+dp[i-3] 代码如下: 求出循环节部分 1 #include<stdio.h> 2 #define m 10007 3 int p[m] ...
- [转]基于全注解的Spring3.1 mvc、myBatis3.1、Mysql的轻量级项目
摘要 对于现在主流的j2ee企业级开发而言,ssh(struts+hibernate+spring)依然是一个事实的标准.由struts充当的mvc调度控制:hibernate的orm持久化映射:sp ...
- Codeforces Round #344 (Div. 2) C. Report 其他
C. Report 题目连接: http://www.codeforces.com/contest/631/problem/C Description Each month Blake gets th ...
- <摘录>GCC 中文手
GCC 中文手册 作者:徐明 GCC Section: GNU Tools (1) Updated: 2003/12/05 Index Return to Main Contents -------- ...
- openwrt web管理luci界面修改
转自:http://blog.csdn.net/user_920/article/details/8504979 以前都没听过openwrt和luci,只接触过简单的php语言.由于工作原因,要修改下 ...
- 版本控制SVN的使用笔记
安装 客户端和服务端下载地址,打开网址,根据自己的操作系统下载对应的版本,window用户服务端一般安装的是VisualSVN,客户端安装TortoiseSVN,在实际工作中,我们一般只需要安装Tor ...
- java常用命令行
1.javac(编译java源文件) javac是用来编译.java文件的. 例子: package com.fjassa.domain; public class Human.public cla ...
- 初入android驱动开发之字符设备(一)
大学毕业,初入公司,招进去的是android驱动开发工程师的岗位,那时候刚进去,首先学到的就是如何搭建kernel.android的编译环境,然后就是了解如何刷设备以及一些最基本的工具.如adb.fa ...