springboot中实现kafa指定offset消费
kafka消费过程难免会遇到需要重新消费的场景,例如我们消费到kafka数据之后需要进行存库操作,若某一时刻数据库down了,导致kafka消费的数据无法入库,为了弥补数据库down期间的数据损失,有一种做法我们可以指定kafka消费者的offset到之前某一时间的数值,然后重新进行消费。
首先创建kafka消费服务
@Service
@Slf4j
//实现CommandLineRunner接口,在springboot启动时自动运行其run方法。
public class TspLogbookAnalysisService implements CommandLineRunner {
@Override
public void run(String... args) {
//do something
}
}
kafka消费模型建立
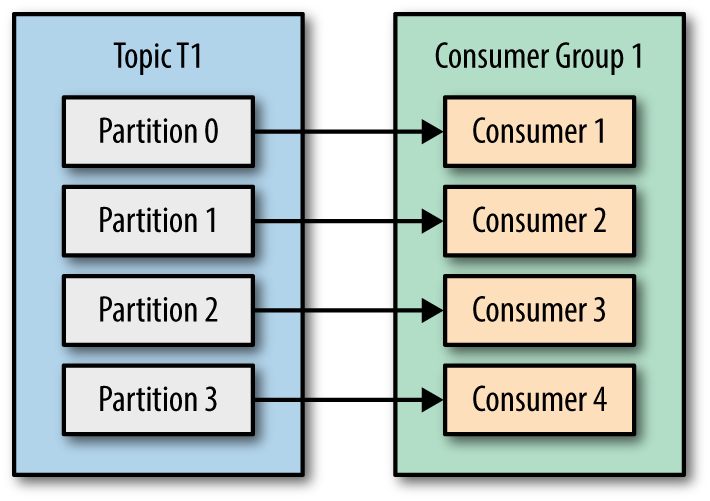
kafka server中每个主题存在多个分区(partition),每个分区自己维护一个偏移量(offset),我们的目标是实现kafka consumer指定offset消费。
在这里使用consumer-->partition一对一的消费模型,每个consumer各自管理自己的partition。
@Service
@Slf4j
public class TspLogbookAnalysisService implements CommandLineRunner {
//声明kafka分区数相等的消费线程数,一个分区对应一个消费线程
private static final int consumeThreadNum = 9;
//特殊指定每个分区开始消费的offset
private List<Long> partitionOffsets = Lists.newArrayList(1111,1112,1113,1114,1115,1116,1117,1118,1119);
private ExecutorService executorService = Executors.newFixedThreadPool(consumeThreadNum);
@Override
public void run(String... args) {
//循环遍历创建消费线程
IntStream.range(0, consumeThreadNum)
.forEach(partitionIndex -> executorService.submit(() -> startConsume(partitionIndex)));
}
}
kafka consumer对offset的处理
声明kafka consumer的配置类
private Properties buildKafkaConfig() {
Properties kafkaConfiguration = new Properties();
kafkaConfiguration.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "");
kafkaConfiguration.put(ConsumerConfig.GROUP_ID_CONFIG, "");
kafkaConfiguration.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, "");
kafkaConfiguration.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "");
kafkaConfiguration.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "");
kafkaConfiguration.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "");
kafkaConfiguration.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"");
kafkaConfiguration.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "");
...更多配置项
return kafkaConfiguration;
}
创建kafka consumer,处理offset,开始消费数据任务
private void startConsume(int partitionIndex) {
//创建kafka consumer
KafkaConsumer<String, byte[]> consumer = new KafkaConsumer<>(buildKafkaConfig());
try {
//指定该consumer对应的消费分区
TopicPartition partition = new TopicPartition(kafkaProperties.getKafkaTopic(), partitionIndex);
consumer.assign(Lists.newArrayList(partition));
//consumer的offset处理
if (collectionUtils.isNotEmpty(partitionOffsets) && partitionOffsets.size() == consumeThreadNum) {
Long seekOffset = partitionOffsets.get(partitionIndex);
log.info("partition:{} , offset seek from {}", partition, seekOffset);
consumer.seek(partition, seekOffset);
}
//开始消费数据任务
kafkaRecordConsume(consumer, partition);
} catch (Exception e) {
log.error("kafka consume error:{}", ExceptionUtils.getFullStackTrace(e));
} finally {
try {
consumer.commitSync();
} finally {
consumer.close();
}
}
}
消费数据逻辑,offset操作
private void kafkaRecordConsume(KafkaConsumer<String, byte[]> consumer, TopicPartition partition) {
while (true) {
try {
ConsumerRecords<String, byte[]> records = consumer.poll(TspLogbookConstants.POLL_TIMEOUT);
//具体的处理流程
records.forEach((k) -> handleKafkaInput(k.key(), k.value()));
//
springboot中实现kafa指定offset消费的更多相关文章
- spark streaming从指定offset处消费Kafka数据
spark streaming从指定offset处消费Kafka数据 -- : 770人阅读 评论() 收藏 举报 分类: spark() 原文地址:http://blog.csdn.net/high ...
- springboot中RedisTemplate的使用
springboot中RedisTemplate的使用 参考 了解 Redis 并在 Spring Boot 项目中使用 Redis--以IBM为学习模板 springboot之使用redistemp ...
- javascript中常用坐标属性offset、scroll、client
原文:javascript中常用坐标属性offset.scroll.client 今天在学习js的时候觉得这个问题比较容易搞混,所以自己画了一个简单的图,并且用js控制台里面输出测试了下,便于理解. ...
- SpringBoot(四)SpringBoot中lombok使用
lombok概述 lombok简介 Lombok想要解决了的是在我们实体Bean中大量的Getter/Setter方法,以及toString, hashCode等可能不会用到,但是某些时候仍然需要复写 ...
- SpringBoot 中常用注解@PathVaribale/@RequestParam/@GetMapping介绍
SpringBoot 中常用注解@PathVaribale/@RequestParam/@GetMapping介绍 本篇博文将介绍几种如何处理url中的参数的注解@PathVaribale/@Requ ...
- SpringBoot中对于异常处理的提供的五种处理方式
1.自定义错误页面 SpringBoot 默认的处理异常机制:SpringBoot默认的已经提供了一套处理异常的机制.一旦程序中出现了异常,SpringBoot会向/error的url发送请求.在Sp ...
- Spring-boot中@ConfigurationProperties,@Value,@PropertySource
1.利用@ConfigurationProperties获取配置的值,@ConfigurationProperties是springboot提供的基于安全类型的配置放置. application.pr ...
- Springboot中使用Xstream进行XML与Bean 相互转换
在现今的项目开发中,虽然数据的传输大部分都是用json格式来进行传输,但是xml毕竟也会有一些老的项目在进行使用,正常的老式方法是通过获取节点来进行一系列操作,个人感觉太过于复杂.繁琐.推荐一套简单的 ...
- springBoot中实现自定义属性配置、实现异步调用、多环境配置
springBoot中其他相关: 1:springBoot中自定义参数: 1-1.自定义属性配置: 在application.properties中除了可以修改默认配置,我们还可以在这配置自定义的属性 ...
随机推荐
- [高效工作软件] Capslock+的使用笔记 (快捷键)
1.下载https://cjkis.me/capslock+/#%E4%B8%8B%E8%BD%BD,双击即可安装,中文路径也可: 2.这个软件的代码开源了的,以后java学成之后,可以去看看源码: ...
- [剑指offer]第1题,二维数组中的查找
①题目 在一个二维数组中(每个一维数组的长度相同),每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序.请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数. ...
- [软件使用][matlab]最近经常用到的一些函数的意思,和用法
① cat(dim,A,B)按指定的维度,将A和B串联,dim是维度,比如1,2.1指列,2指行: ②numel(A),返回数组中,元素的个数 ③gpuArray(A),在gpu中产生一个数组A,一般 ...
- nyoj 305 表达式求值 (递归)
表达式求值 时间限制:3000 ms | 内存限制:65535 KB 难度:3 描述 Dr.Kong设计的机器人卡多掌握了加减法运算以后,最近又学会了一些简单的函数求值,比如,它知道函数min ...
- root权限后,不要忘了还有selinux
下面的例子运行在中兴android 5.0手机上. 当我们使用root权限的python去创建socket监听端口8088时,selinux向kmsg输出了下面的记录 python-android5 ...
- static declaration follows non-static declaration
前段时间工作中要为android编译跨平台的第三方库,遇到了arc4random有关函数的“static declaration follows non-static declaration”问题,那 ...
- 如何利用快照( snapshot )功能快速定位性能问题
我们常常会遇到这样的困惑,收到用户或者客服的反馈,平台使用有问题,但是测试人员搭建环境后又没办法复现故障,最后导致问题没法解决,眼睁睁地看着用户流失. 这是因为线上生产环境非常复杂.很多时候是偶发性 ...
- Oracle10g安装步骤(一)
本例使用安装程序:10201_database_win32 首先将所有文件提取解压出来后,执行setup.exe 安装步骤如下:
- axios 请求二次封装
/** * 封装get方法 * @param url * @param data * @returns {Promise} */ export function get(url, params) { ...
- Singletone 析构函数调不到
<设计模式>定义一个单例类,使用类的私有静态指针变量指向类的唯一实例,并用一个公有的静态方法获取该实例. 关键字:指向自己的静态指针私有,创建对象并赋值私有静态指针函数->公有, 构 ...