scikit-learn学习笔记-bili莫烦
bilibili莫烦scikit-learn视频学习笔记
1.使用KNN对iris数据分类
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier # 从datasets中导入iris数据,包含150条样本,每条样本4个feature
iris_data = datasets.load_iris()
# 获取feature
iris_x = iris_data.data
# 获取标签
iris_y = iris_data.target
print(iris_x.shape)
print(iris_y)
# 将数据集分为训练集和测试集,比例是70%:30%
train_x, test_x, train_y, test_y = train_test_split(iris_x, iris_y, test_size=0.3)
# 使用knn分类器(n_neighbors表示通过附近的几个邻居来确定分类,一般为单数)
knn = KNeighborsClassifier(n_neighbors = 5)
# 训练
knn.fit(train_x, train_y)
# 测试
print(knn.predict(test_x))
print(test_y)
2.使用线性回归预测Boston房价
from sklearn import datasets
from sklearn.linear_model import LinearRegression # 从datasets中载入Boston房价数据集
loaded_data = datasets.load_boston()
# 包含506条样本,每条样本13个feature
data_x = loaded_data.data
# 标签,即房价(万)
data_y = loaded_data.target # 线性回归器
lr = LinearRegression()
# 训练
lr.fit(data_x, data_y)
# 预测前6条样本的房价
print(lr.predict(data_x[:6, :]))
# 与标签对比,可以看出准确度
print(data_y[:6])
3.如何创建线性数据(实验数据)
from sklearn import datasets
import matplotlib.pyplot as plt # 使用make_regression函数生成线性回归数据集,100个样本,1个feature,noise控制噪声即偏移度
made_data_x, made_data_y = datasets.make_regression(n_samples=100, n_features=1, n_targets=1, noise=30)
# 使用matplotlib画散点图
plt.scatter(made_data_x, made_data_y)
# 显示图像
plt.show() # 使用线性回归器来进行训练和预测
lr = LinearRegression()
lr.fit(made_data_x, made_data_y)
print(lr.predict(made_data_x[:5, :]))
print(made_data_y[:5])
# 打印学习到的参数集,y = wx + b
print(lr.coef_) # output w,w是一个向量,数量和n_features一致
print(lr.intercept_) # output b,b即bias
4.输出模型的一些参数
# 打印学习到的参数集,y = wx + b
print(lr.coef_) # output w,w是一个向量,数量和n_features一致,w = [28.44936087]
print(lr.intercept_) # output b,b即bias = -2.787101732423871
# 打印LinearRegression的参数值,未手工设置则打印默认参数
print(lr.get_params()) # 打印{'copy_X': True, 'fit_intercept': True, 'n_jobs': 1, 'normalize': False}
# 使用数据进行测试,并打分,在回归中使用R^2 coefficient of determination
print(lr.score(test_x, test_y))
5.使用SVC进行分类(数据伸缩)
import numpy as np
import matplotlib.pyplot as plt from sklearn import preprocessing
from sklearn.model_selection import train_test_split
from sklearn.datasets.samples_generator import make_classification
# 从svm模块中导入support vector classifier
from sklearn.svm import SVC # 创建数据集
X, y = make_classification(n_samples=3000, n_features=2, n_redundant=0, n_informative=2, random_state=22,
n_clusters_per_class=1, scale=100)
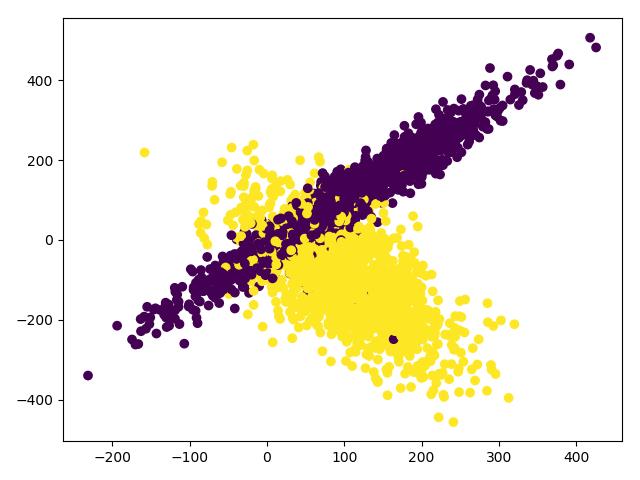
# 画图c=y的意思是颜色根据y来区分
plt.scatter(X[:, 0], X[:, 1], c=y)
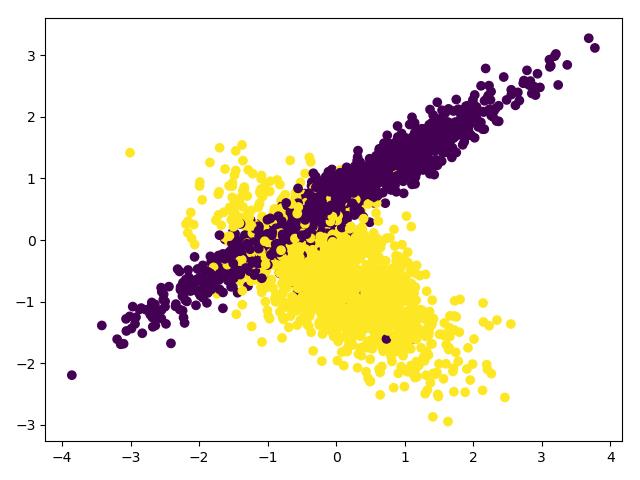
plt.show() # 将数据伸缩为[0,1]
scales_x = preprocessing.scale(X)
# 伸缩后的数据方差为1.0
print(np.std(scales_x)) # 使用SVC分类器分类
train_x, test_x, train_y, test_y = train_test_split(scales_x, y, test_size=0.3)
model = SVC()
model.fit(train_x, train_y)
# 模型分类准确率大概为0.90
print(model.score(test_x, test_y))
6.KNN分类iris,交叉验证,参数选择并可视化
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
# 导入交叉验证
from sklearn.model_selection import cross_val_score # 从datasets中导入iris数据,包含150条样本,每条样本4个feature
iris_data = datasets.load_iris()
iris_x = iris_data.data
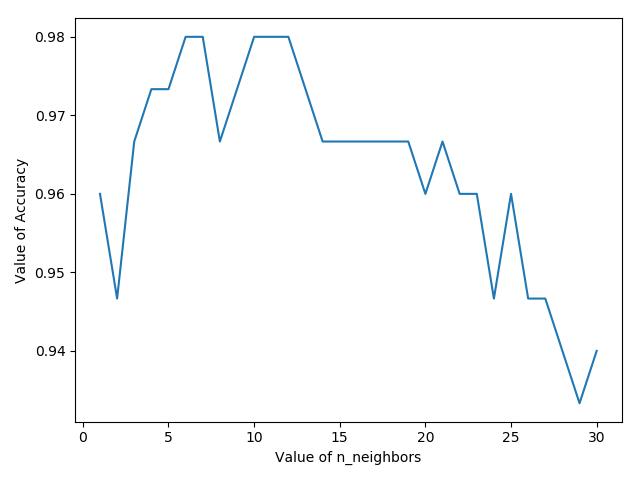
iris_y = iris_data.target # 尝试n_neighbors为不同值时,模型准确度
nb = range(1, 31)
# 保存每次n_neighbors对应准确率,用于plt画图
k_scores = []
for k in nb:
# 使用KNN模型
knn = KNeighborsClassifier(n_neighbors=k)
# 使用交叉验证,不需要自己去切分数据集,也不需要knn.fit()和knn.predict(),cv=5表示交叉验证5组
scores = cross_val_score(knn, iris_x, iris_y, cv=5, scoring='accuracy')
# 取交叉验证集的平均值
k_scores.append(scores.mean()) # 画出n_neighbor于accuracy的关系图
plt.plot(nb,k_scores)
plt.xlabel("Value of n_neighbors")
plt.ylabel("Value of Accuracy")
plt.show()
7.使用交叉验证,并画出学习曲线learning_curve,用于观察模型拟合情况
import numpy as np
import matplotlib.pyplot as plt # 导入sklearn提供的损失曲线
from sklearn.model_selection import learning_curve
from sklearn.datasets import load_digits
from sklearn.svm import SVC # 导入数据
digits = load_digits()
X = digits.data
y = digits.target # 使用学习曲线获取每个阶段的训练损失和交叉测试损失,train_sizes表示各个不同阶段,从10%到100%
train_sizes, train_loss, test_loss = learning_curve(
SVC(gamma=0.001), X, y, cv=10, scoring='neg_mean_squared_error',
train_sizes=np.linspace(0.1, 1, 10)
) # 将每次训练集交叉验证(10个损失值,因为cv=10)取平均值
train_loss_mean = -np.mean(train_loss, axis=1)
print(train_loss_mean)
# 将每次测试集交叉验证取平均值
test_loss_mean = -np.mean(test_loss, axis=1)
print(test_loss_mean)
# 画图,红色是训练平均损失值,绿色是测试平均损失值
plt.plot(train_sizes, train_loss_mean, 'o-', color='r', label='Training')
plt.plot(train_sizes, test_loss_mean, 'o-', color='g', label='Cross_validation')
plt.xlabel('Train sizes')
plt.ylabel('Loss')
plt.show()

8.使用交叉验证,并画出验证曲线validation_curve,用于观察模型参数不同时的准确率
import numpy as np
import matplotlib.pyplot as plt # 导入sklearn提供的验证曲线
from sklearn.model_selection import validation_curve
from sklearn.datasets import load_digits
from sklearn.svm import SVC # 导入数据
digits = load_digits()
X = digits.data
y = digits.target # SVC参数gamma的范围
param_range = np.logspace(-6, -2.3, 5) # 使用validation曲线,指定params的名字和范围
train_loss, test_loss = validation_curve(
SVC(), X, y, param_name='gamma', param_range=param_range, cv=10, scoring='neg_mean_squared_error'
) # 将每次训练集交叉验证(10个损失值,因为cv=10)取平均值
train_loss_mean = -np.mean(train_loss, axis=1)
print(train_loss_mean)
# 将每次测试集交叉验证取平均值
test_loss_mean = -np.mean(test_loss, axis=1)
print(test_loss_mean)
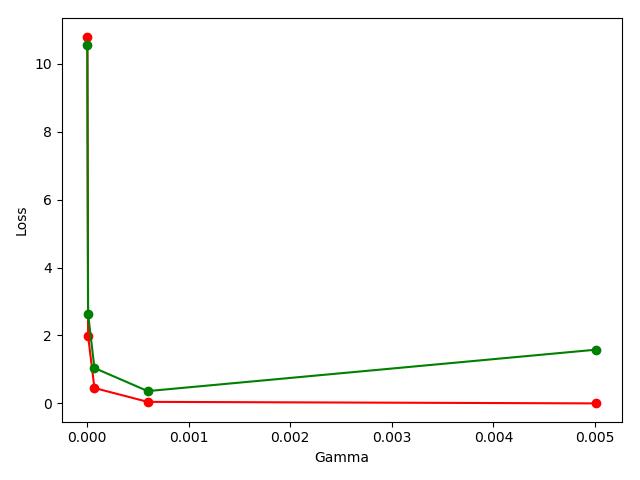
# 画图,红色是训练平均损失值,绿色是测试平均损失值,注意这里的x坐标是param_range
plt.plot(param_range, train_loss_mean, 'o-', color='r', label='Training')
plt.plot(param_range, test_loss_mean, 'o-', color='g', label='Cross_validation')
plt.xlabel('Gamma')
plt.ylabel('Loss')
plt.show()
9.使用pickle保存模型到文件
import pickle
from sklearn.datasets import load_iris
from sklearn.svm import SVC iris = load_iris()
X = iris.data
y = iris.target # # 使用SVC模型
# model = SVC()
# # 训练模型
# model.fit(X,y)
# # 使用pickle保存模型到文件中
# with open('save/model.pickle','wb') as fp:
# pickle.dump(model,fp) # 从文件中load模型
with open('save/model.pickle', 'rb') as fp:
model_read = pickle.load(fp) # 使用load出的模型预测
print(model_read.predict(X[0:1]))
10.使用joblib保存模型到文件
from sklearn.datasets import load_iris
from sklearn.svm import SVC
# 导入外部模块中得joblib用于存储模型
from sklearn.externals import joblib iris = load_iris()
X = iris.data
y = iris.target # # 使用SVC模型
# model = SVC()
# # 训练模型
# model.fit(X,y)
# # 使用joblib存放模型到model.jl中
# joblib.dump(model,'save/model.jl') # 从model.jl中读取模型
model_read = joblib.load('save/model.jl')
# 用load的模型预测
print(model_read.predict(X[0:1]))
scikit-learn学习笔记-bili莫烦的更多相关文章
- tensorflow学习笔记-bili莫烦
bilibili莫烦tensorflow视频教程学习笔记 1.初次使用Tensorflow实现一元线性回归 # 屏蔽警告 import os os.environ[' import numpy as ...
- keras学习笔记-bili莫烦
一.keras的backend设置 有两种方式: 1.修改JSON配置文件 修改~/.keras/keras.json文件内容为: { "iamge_dim_ordering":& ...
- 机器学习-scikit learn学习笔记
scikit-learn官网:http://scikit-learn.org/stable/ 通常情况下,一个学习问题会包含一组学习样本数据,计算机通过对样本数据的学习,尝试对未知数据进行预测. 学习 ...
- Learning How to Learn学习笔记(转)
add by zhj: 工作中提高自己水平的最重要的一点是——快速的学习能力.这篇文章就是探讨这个问题的,掌握了快速学习能力的规律,你自然就有了快速学习能力了. 原文:Learning How to ...
- 【pytorch】学习笔记(二)- Variable
[pytorch]学习笔记(二)- Variable 学习链接自莫烦python 什么是Variable Variable就好像一个篮子,里面装着鸡蛋(Torch 的 Tensor),里面的鸡蛋数不断 ...
- 稍稍乱入的CNN,本文依然是学习周莫烦视频的笔记。
稍稍乱入的CNN,本文依然是学习周莫烦视频的笔记. 还有 google 在 udacity 上的 CNN 教程. CNN(Convolutional Neural Networks) 卷积神经网络简单 ...
- 莫烦大大TensorFlow学习笔记(9)----可视化
一.Matplotlib[结果可视化] #import os #os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' import tensorflow as tf i ...
- 莫烦pytorch学习笔记(八)——卷积神经网络(手写数字识别实现)
莫烦视频网址 这个代码实现了预测和可视化 import os # third-party library import torch import torch.nn as nn import torch ...
- 莫烦pytorch学习笔记(七)——Optimizer优化器
各种优化器的比较 莫烦的对各种优化通俗理解的视频 import torch import torch.utils.data as Data import torch.nn.functional as ...
随机推荐
- Python属性和方法
关键字:Python 属性 方法原文:http://www.cafepy.com/article/python_attributes_and_methods/python_attributes_and ...
- 亲串 (hdu 2203 KMP)
亲串 Time Limit: 3000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total Submiss ...
- WPF - 善用路由事件
原文:WPF - 善用路由事件 在原来的公司中,编写自定义控件是常常遇到的任务.但这些控件常常拥有一个不怎么好的特点:无论是内部还是外部都没有使用路由事件.那我们应该怎样宰自定义控件开发中使用路由事件 ...
- JDK源码阅读——Vector实现
1 继承结构图 Vector同样继承自AbstractList,与ArrayList.LinedList一样,是List的一种实现 2 数据结构 // 与ArrayList一样,也是使用对象数组保存元 ...
- delphi备份恢复剪切板(使用了GlobalLock API函数和CopyMemory)
看了季世平老兄的C++代码后翻译过来的 unit clipbak; interface uses SysUtils, Classes, Clipbrd, Windows, Contnrs; type ...
- c# Unity依赖注入WebService
1.IOC与DI简介 IOC全称是Inversion Of Control(控制反转),不是一种技术,只是一种思想,一个重要的面相对象编程的法则,它能知道我们如何设计出松耦合,更优良的程序.传统应用程 ...
- C# API 获取系统DPI缩放倍数跟分辨率大小
原文:C# API 获取系统DPI缩放倍数跟分辨率大小 using System; using System.Drawing; using System.Runtime.InteropServices ...
- vs2017 js cordova + dotnet core 开发app
原文:vs2017 js cordova + dotnet core 开发app 1.记得在index.html加入 <meta http-equiv="Content-Securit ...
- 【Linux】samba服务
samba是一个实现不同操作系统之间文件共享和打印机共享的一种SMB协议的免费软件. ①Samba软件包的安装 使用源安装,在终端中输入如下命令: #sudo apt-get install samb ...
- 图像滤镜艺术---ZPhotoEngine超级算法库
原文:图像滤镜艺术---ZPhotoEngine超级算法库 一直以来,都有个想法,想要做一个属于自己的图像算法库,这个想法,在经过了几个月的努力之后,终于诞生了,这就是ZPhotoEngine算法库. ...