莫烦pytorch学习笔记(七)——Optimizer优化器
import torch
import torch.utils.data as Data
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt
# 超参数
LR = 0.01
BATCH_SIZE =
EPOCH =
# 生成假数据
# torch.unsqueeze() 的作用是将一维变二维,torch只能处理二维的数据
x = torch.unsqueeze(torch.linspace(-, , ), dim=) # x data (tensor), shape(, )
# 0.2 * torch.rand(x.size())增加噪点
y = x.pow() + 0.1 * torch.normal(torch.zeros(*x.size()))
# 输出数据图
# plt.scatter(x.numpy(), y.numpy())
# plt.show()
torch_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)
loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=)
class Net(torch.nn.Module):
# 初始化
def __init__(self):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(, )
self.predict = torch.nn.Linear(, )
# 前向传递
def forward(self, x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
net_SGD = Net()
net_Momentum = Net()
net_RMSProp = Net()
net_Adam = Net()
nets = [net_SGD, net_Momentum, net_RMSProp, net_Adam]
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
opt_RMSProp = torch.optim.RMSprop(net_RMSProp.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSProp, opt_Adam]
loss_func = torch.nn.MSELoss()
loss_his = [[], [], [], []] # 记录损失
for epoch in range(EPOCH):
print(epoch)
for step, (batch_x, batch_y) in enumerate(loader):
b_x = Variable(batch_x)
b_y = Variable(batch_y)
for net, opt,l_his in zip(nets, optimizers, loss_his):
output = net(b_x) # get output for every net
loss = loss_func(output, b_y) # compute loss for every net
opt.zero_grad() # clear gradients for next train
loss.backward() # backpropagation, compute gradients
opt.step() # apply gradients
l_his.append(loss.data.numpy()) # loss recoder
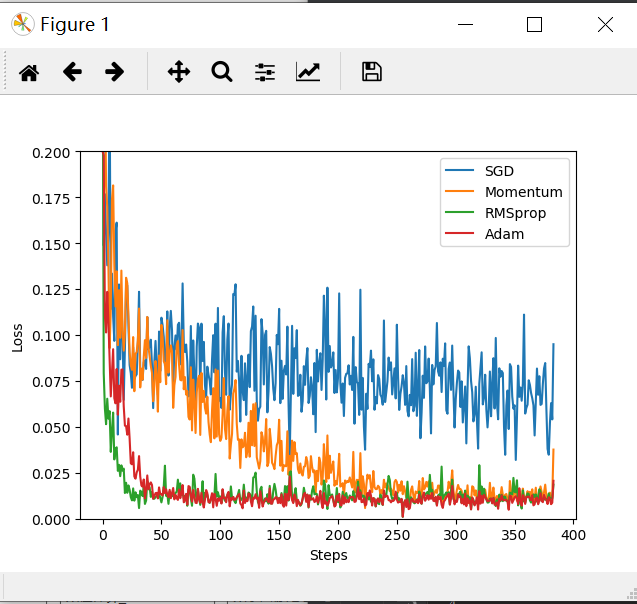
labels = ['SGD', 'Momentum', 'RMSprop', 'Adam']
for i, l_his in enumerate(loss_his):
plt.plot(l_his, label=labels[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim((, 0.2))
plt.show()
莫烦pytorch学习笔记(七)——Optimizer优化器的更多相关文章
- 莫烦 - Pytorch学习笔记 [ 一 ]
1. Numpy VS Torch #相互转换 np_data = torch_data.numpy() torch_data = torch.from_numpy(np_data) #abs dat ...
- 莫烦pytorch学习笔记(八)——卷积神经网络(手写数字识别实现)
莫烦视频网址 这个代码实现了预测和可视化 import os # third-party library import torch import torch.nn as nn import torch ...
- 莫烦PyTorch学习笔记(五)——模型的存取
import torch from torch.autograd import Variable import matplotlib.pyplot as plt torch.manual_seed() ...
- [PyTorch 学习笔记] 4.3 优化器
本章代码: https://github.com/zhangxiann/PyTorch_Practice/blob/master/lesson4/optimizer_methods.py https: ...
- 莫烦PyTorch学习笔记(五)——分类
import torch from torch.autograd import Variable import torch.nn.functional as F import matplotlib.p ...
- 莫烦PyTorch学习笔记(四)——回归
下面的代码说明个整个神经网络模拟回归的过程,代码含有详细注释,直接贴下来了 import torch from torch.autograd import Variable import torch. ...
- 莫烦PyTorch学习笔记(六)——批处理
1.要点 Torch 中提供了一种帮你整理你的数据结构的好东西, 叫做 DataLoader, 我们能用它来包装自己的数据, 进行批训练. 而且批训练可以有很多种途径. 2.DataLoader Da ...
- 莫烦PyTorch学习笔记(三)——激励函数
1. sigmod函数 函数公式和图表如下图 在sigmod函数中我们可以看到,其输出是在(0,1)这个开区间内,这点很有意思,可以联想到概率,但是严格意义上讲,不要当成概率.sigmod函数 ...
- 莫烦pytorch学习笔记(二)——variable
.简介 torch.autograd.Variable是Autograd的核心类,它封装了Tensor,并整合了反向传播的相关实现 Variable和tensor的区别和联系 Variable是篮子, ...
随机推荐
- WriteFile
从R3 ,到磁盘 1:kernel32 WriteFile 1) 挺惊讶的,符号好使了, 前面大概4条判断,根据句柄判断要写到什么地方,一共有4个地方可能要去, stdin stdout s ...
- StringBuilder 和 StringBuffer类
通常在涉及到StringBuilder和StringBuffer时中任何一个时,都应该想到另外一个并且在脑海中问自己是否用另外一个更加合适. 为什么这么说,请继续往下看,当然如果你已经对二者烂熟于胸自 ...
- kafka 入门
李克华 云计算高级群: 292870151 195907286 交流:Hadoop.NoSQL.分布式.lucene.solr.nutch kafka入门:简介.使用场景.设计原理.主要配置及集群搭 ...
- 针对Java集合类的小总结
Java集合类包位于java.util下,有很多常用的数据结构:数组.链表.队列.栈.哈希表等等.了解不同的集合类的特性在开发过程中是比较重要的,感谢@兰亭风雨的专栏分析,这里我也根据自己的理解做轻度 ...
- Django form组件 与 cookie/session
目录 一.form组件 二.cookie.session 返回Django 组件 一.form组件 1.1 以注册功能为例 注册功能 1.渲染前端标签获取用户输入 --> 渲染标签 2.获取用户 ...
- NLP杂点
1.停用词 stop words: 在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词. 停用词都是人工输入.或者由一个停用词表导入. 2.jieba是目前最好的 Python 中文分词组件 ...
- CSS——滑动门技术及应用
先来体会下现实中的滑动门,或者你可以叫做推拉门: 滑动门出现的背景 制作网页时,为了美观,常常需要为网页元素设置特殊形状的背景,比如微信导航栏,有凸起和凹下去的感觉,最大的问题是里面的字数不一样多,咋 ...
- Oracle闪回查询恢复delete删除数据
Flashback query(闪回查询)原理 Oracle根据undo信息,利用undo数据,类似一致性读取方法,可以把表置于一个删除前的时间点(或SCN),从而将数据找回. Flashback q ...
- jquery学习笔记(三):事件和应用
内容来自[汇智网]jquery学习课程 3.1 页面加载事件 在jQuery中页面加载事件是ready().ready()事件类似于就JavaScript中的onLoad()事件,但前者只要页面的DO ...
- linux大神
http://blog.csdn.net/skykingf/article/category/780616