使用聚集索引和非聚集索引对MySQL分页查询的优化
内容摘录来源:MSSQL123 ,lujun9972.github.io/blog/2018/03/13/如何编写bash-completion-script/
一、先公布下结论:
1、如果分页排序字段是聚集索引,完全没必要对索引分页再查询数据,因为索引就是数据本身;
2、如果是非聚集索引,先对索引分页,然后再利用索引去查询数据,先分页索引确实可以减少扫描的范围;
3、如果经常按照2中的方式查询,也就是按照非聚集索引排序查询,强烈建议直接在该列上建立聚集索引;
二、MySQL经典的分页“优化”做法:
1、若在id上建立聚集索引,随着m的增大,查询同样多的数据,会越来越慢;
分页查询sql语句:select * from t order by id limit m,n ;
优化后的查询语句: select * from t inner join (select id from t order by id limit m,n)t1 on t1.id = t.id;
查询结果证明,优化后的没有卵用;
分析原因:排序列为聚集索引列的情况下,两者都是按照索引顺序扫描表,来查询符合条件的数据;后者虽然是先驱动一个子查询,然后再用子查询的结果驱动主表,但是子查询并没有改变“顺序扫描表,来查询符合条件的数据的”做法,当前情况下,甚至改写后的做法显得画蛇添足。
解决办法:mysql中也有类似于sqlserver中的正向(forwarded)和反向扫描(backward)的做法。如果对于靠后的数据,采用反向扫描,应该就可以很快找到这个部分数据,然后对找到的数据在再次排序(asc),查询结果是一样的(其实是借鉴了B-tree索引的数据结构)。
查询sql语句:select * from ( select * from test_table1 order by id desc limit 99980,20 ) t order by id;
实时证明,牛车直接变火箭了!换个角度考虑,当我们查字典时,若要查“张”字,肯定是直接翻到“Z”开头的去查,肯定不是从字母“A”开始翻吧。数据库也是人设计的,他们的解决方案,通常都是用现实生活中,小学生都能想明白的方案。
2、我们来了解下B-tree索引的数据结构,作者的这俩张图,灰常流弊:
如下图,当查询的数据“靠后”的时候,实际上是偏离在B树索引的一个方向,如下两个截图所示的目标数据其实平衡树上的数据,没有所谓的“靠前”与“靠后”,“靠前”与“靠后”都是相对于对方来说的,或者说是从扫描的方向上来看的从一个方向上看“靠后的”数据,从一个方向看就是“靠前的”,前后不是绝对的。
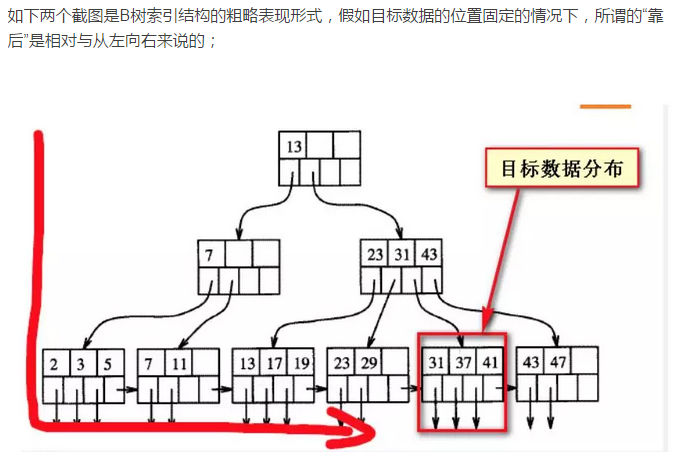
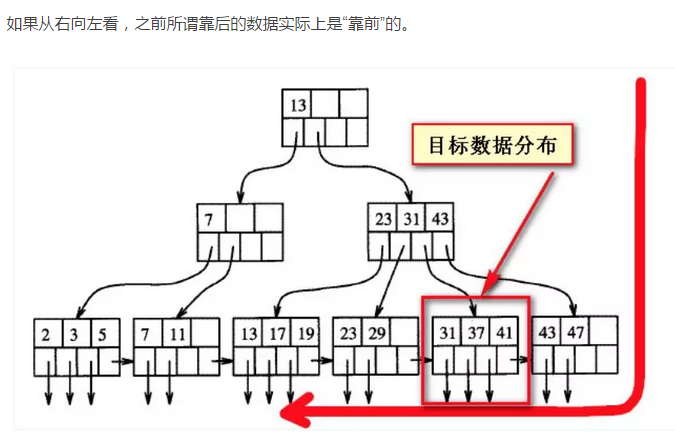
上面的分页优化方案就是根据这俩张图得出来的;
3、当我们以非聚集索引列作为排序字段时:
优化前sql语句:select * from test_table1 order by id_2 asc limit 4900000,20;执行时间为1分钟多一点,暂且认其为60秒;
优化后sql语句:select t1.* from test_table1 t1 inner join (select id from test_table1 order by id_2 limit 4900000,20)t2 on t1.id = t2.id;执行时间1.67秒,查询速度提高了40倍;
分析原因:可以简单理解为优化前的sql执行时做全表扫描之后,然后重新按照id_2排序,最后取最前20条数据;全表扫描就是一个非常耗时的过程,排序也是一个非常大的代价,因此表现为性能非常的低下。优化后的sql 语句的执行计划,是首先在子查询中,按照id_2上的索引顺序扫描,然后用符合条件的主键Id去表中查询数据。这样的话,避免了查询出来大量的数据然后重新排序(Using filesort)。
结论:排序列为非聚集索引列的时候,改写后的sql才能提升分页查询的效率。
使用聚集索引和非聚集索引对MySQL分页查询的优化的更多相关文章
- SQLSERVER聚集索引与非聚集索引的再次研究(上)
SQLSERVER聚集索引与非聚集索引的再次研究(上) 上篇主要说聚集索引 下篇的地址:SQLSERVER聚集索引与非聚集索引的再次研究(下) 由于本人还是SQLSERVER菜鸟一枚,加上一些实验的逻 ...
- SQLSERVER聚集索引与非聚集索引的再次研究(下)
SQLSERVER聚集索引与非聚集索引的再次研究(下) 上篇主要说了聚集索引和简单介绍了一下非聚集索引,相信大家一定对聚集索引和非聚集索引开始有一点了解了. 这篇文章只是作为参考,里面的观点不一定正确 ...
- SQL Server-聚焦聚集索引对非聚集索引的影响(四)
前言 在学习SQL 2012基础教程过程中会时不时穿插其他内容来进行讲解,相信看过SQL Server 2012 T-SQL基础教程的童鞋知道前面写的所有内容并非都是摘抄书上内容,如若是这样那将没有任 ...
- SQL SERVER 索引之聚集索引和非聚集索引的描述
索引是与表或视图关联的磁盘上结构,可以加快从表或视图中检索行的速度. 索引包含由表或视图中的一列或多列生成的键. 这些键存储在一个结构(B 树)中,使 SQL Server 可以快速有效地查找与键值关 ...
- SQL Server中的联合主键、聚集索引、非聚集索引、mysql 联合索引
我们都知道在一个表中当需要2列以上才能确定记录的唯一性的时候,就需要用到联合主键,当建立联合主键以后,在查询数据的时候性能就会有很大的提升,不过并不是对联合主键的任何列单独查询的时候性能都会提升,但我 ...
- SQL Server索引 (原理、存储)聚集索引、非聚集索引、堆 <第一篇>
一.存储结构 在SQL Server中,有许多不同的可用排列规则选项. 二进制:按字符的数字表示形式排序(ASCII码中,用数字32表示空格,用68表示字母"D").因为所有内容都 ...
- SQL Server索引 - 聚集索引、非聚集索引、非聚集唯一索引 <第八篇>
聚集索引.非聚集索引.非聚集唯一索引 我们都知道建立适当的索引能够提高查询速度,优化查询.先说明一下,无论是聚集索引还是非聚集索引都是B树结构. 聚集索引默认与主键相匹配,在设置主键时,SQL Ser ...
- 聚集索引VS非聚集索引
聚集索引VS非聚集索引 SQL Server 2014 发布日期: 2016年12月 索引是与表或视图关联的磁盘上结构,可以加快从表或视图中检索行的速度. 索引包含由表或视图中的一列或多列生成的键. ...
- MySQL聚集索引和非聚集索引
索引分为聚集索引和非聚集索引,mysql中不同的存储引擎对索引的底层实现可能会不同,这里只关注mysql的默认存储引擎InnoDB. 利用下面的命令可以查看默认的存储引擎 show variables ...
随机推荐
- Apache开启.htaccess 支持
(1) <Directory "${SRVROOT}/htdocs"> # # Possible values for the Options directive ar ...
- 阿里云=>RHSA-2019:1884-中危: libssh2 安全更新
由于项目构建时间比较长,近期安全检查发现openssh有漏洞.所以要升级openssh到7.9p1版本.由于ssh用于远程连接,所以要谨慎操作. 建议生成环境要先做测试,之后再在生产环境升级. 1 前 ...
- Introduction to Deep Learning Algorithms
Introduction to Deep Learning Algorithms See the following article for a recent survey of deep learn ...
- 充值css样式
@charset "utf-8"; /*reset CSS*/ body,ul,ol,dl,dd,h1,h2,h3,h4,h5,h6,figure,form,fieldset,le ...
- github 提交和更新代码
…or create a new repository on the command line echo "# flutterPluginsWorks" >> RE ...
- CHD-5.3.6集群上sqoop安装
Sqoop(发音:skup)是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql.postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ...
- shiro系列二、身份验证和授权
一.身份验证 先来看看身份验证的流程 流程如下: 1.首先调用Subject.login(token)进行登录,其会自动委托给Security Manager,调用之前必须通过SecurityUtil ...
- wampserver apache 500 Internal Server Error解决办法
Internal Server ErrorThe server encountered an internal error or misconfiguration and was unable to ...
- pip安装tesserocr时报错
在Xubuntu上的python2虚拟环境中, 使用pip安装tesserocr时报错error: command 'x86_64-linux-gnu-gcc' failed with exit st ...
- CSS效果篇--纯CSS+HTML实现checkbox的思路与实例
checkbox应该是一个比较常用的html功能了,不过浏览器自带的checkbox往往样式不怎么好看,而且不同浏览器效果也不一样.出于美化和统一视觉效果的需求,checkbox的自定义就被提出来了. ...