centos7搭建hadoop-2.7.3,zookeeper-3.4.6,hbase-1.2.5(root用户)
环境:【centos7、hadoop-2.7.3、zookeeper-3.4.6、hbase-1.2.5】
两个节点:【主节点,主机名为Master,用户为root;从节点,主机名为Slave,用户为root】

1、设置主机名,实现域名通信(所有节点都要改)
修改hostname主机名
hostnamectl set-hostname 主机名 #修改三种主机名
hostnamectl –static set-hostname 主机名 #只会修改static主机名
ifconfig查看ip
我这里虚拟机是桥接模式,网段改成172.168了,根据自己需求进行更改;
在虚拟机的菜单-编辑->虚拟网络编辑器中能看到信息;
编辑配置文件,sudo vim /etc/sysconfig/network-scripts/ifcfg-ens33,将ip信息添加进去
主节点:172.168.0.223

从节点:172.168.0.222

修改配置文件,sudo vim /etc/hosts(每个主机都要改)

设置dns就可以域名通信了
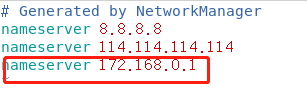
进入到配置文件中sudo vim /etc/resolv.conf
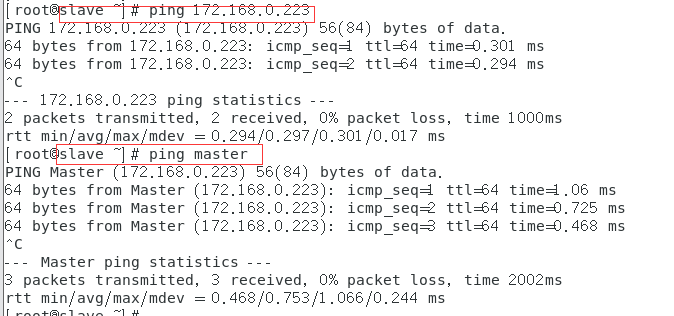
ping一下,看看能不能通(如果不通,检查一下防火墙有没有关)

systemctl status firewalld 检查防火墙状态
systemctl stop firewalld 关闭
systemctl disable firewalld 禁用
2、配置ssh免密登录
① 本机无密钥登录(主节点:Master)
1.进入~/.ssh目录(若无,则执行一次ssh localhost),
2.执行ssh-keygen -t rsa命令(回车即可),
3.再执行cat ./id_rsa.pub >> ./authorized_keys命令,把id_rsa.pub追加到授权的key里面,

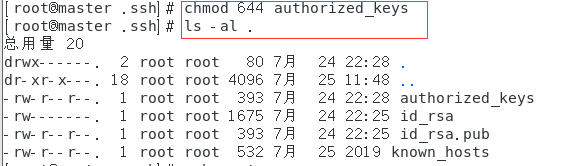
4.给authorized_keys授权chmod 644 authorized_keys, ls -al ~/.ssh命令看权限,
5.重启 sudo service sshd restart
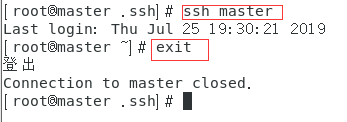
6.连接 ssh localhost(yes/no,手动输入yes)
7.退出 exit
② 与其他节点的无密钥登录
1.从节点一样执行①中1、2,
2.Master把authorized_keys分发到Slave上(会提示输入密码,输入密码即可),scp ./authorized_keys username(用户名)@(ip地址/主机名):/root/.ssh (目录根据自己机子来)

3.在其他机子上执行①中步骤4授权
4.尝试连接其他机子,ssh 用户名@ip地址/域名

免密登录配置完成!!!
3、安装jdk(所有节点都要装)
先删除centos7自带的openjdk
①rpm -qa | grep java
②rpm -e --nodeps Openjdk
(我装的是jdk1.8.0_221)
jdk下载地址
需要登录哦!!!
1.下载完成后解压到/usr/local/java目录下(没有java目录就创建)
tar -xzvf jdk-8u221-linux-x64.tar.gz
2.配置环境变量
sudo vim /etc/profile
JAVA_HOME=/usr/local/java/jdk1.8.0_221
JRE_HOME=$JAVA_HOME/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
source /etc/profile(使文件生效)
3.验证
java -version
4、安装hadoop(主节点安装后,分发给其他节点就好)
1.同样解压,我设的目录是/usr/local/hadoop
2.配置环境变量
sudo vim /etc/profile
HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.3
HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_HOME HADOOP_COMMON_LIB_NATIVE_DIR PATH
source /etc/profile(使文件生效)
3.修改hadoop的配置文件
进入到/usr/local/hadoop/hadoop-2.7.3/etc/hadoop/目录下,在hadoop-env.sh和yarn-env.sh两个文件中添加JAVA_HOME
cd /usr/local/hadoop/hadoop-2.7.3/etc/hadoop
vim hadoop-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_221
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.3
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"(更改hadoop_opts)
source hadoop-env.sh(使文件生效)
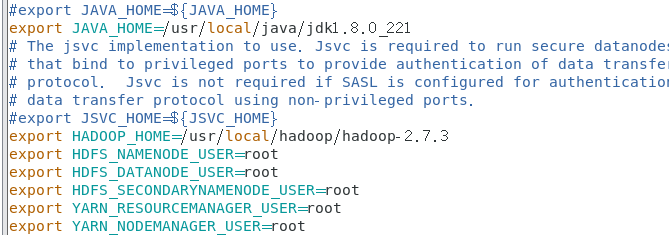

vim yarn-env.sh
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
export JAVA_HOME=/usr/local/java/jdk1.8.0_221
source yarn-env.sh

另外还有四个site.xml的文件需要配置
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://172.168.0.223:9000</value>
<description>HDFS的URI,文件系统://namenode标识:端口号</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
</configuration>

hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>副本个数,配置默认是3,应小于datanode机器数量</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
</configuration>

yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>

mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>master:49001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/usr/local/hadoop/var</value>
</property>
</configuration>

slaves文件中添加你的主机和节点

4.将hadoop分发到其他节点,用scp命令
scp -r /usr/local/hadoop Slave:/usr/local
5.格式化namenode
进入hadoop-2.7.3下的sbin目录下执行 命令
hdfs namenode -format

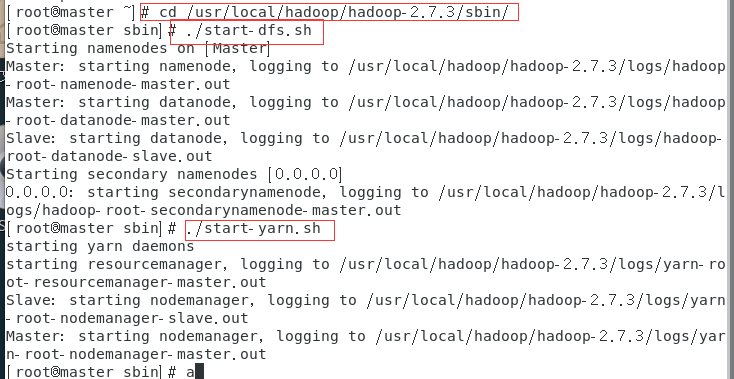
6.启动hadoop
执行这两个命令
./start-dfs.sh
./start-yarn.sh
7.jps查看

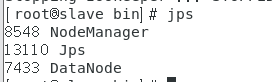
jps命令找不到的解决办法:
yum list *openjdk-devel*
yum install java-1.8.0-openjdk-devel.x86_64
8.访问浏览器
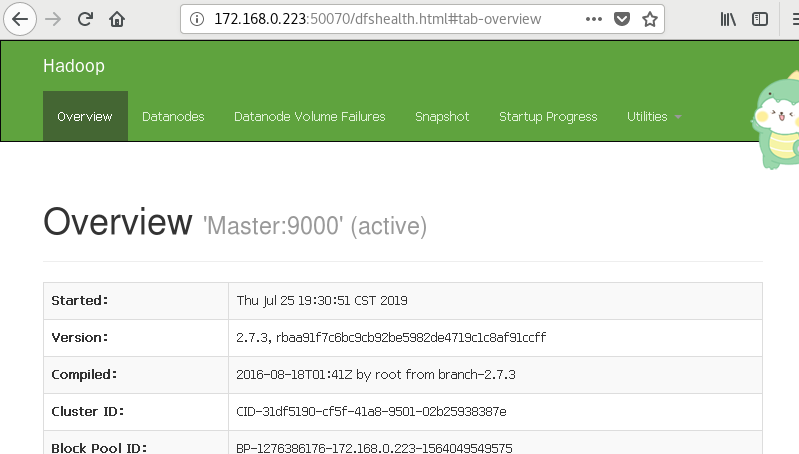
9.访问集群所有应用程序默认8088

5、安装zookeeper(主从节点都要)
1.同上步骤解压到/usr/local/zookeeper下

2.进入到目录conf下,执行cp zoo_sample.cfg zoo.cfg命令,复制 zoo_sample.cfg 到 zoo.cfg文件中

3.编辑zoo.cfg文件 vim zoo.cfg


4.进入到目录data下,创建myid文件并添加对应的数字
Master节点:1;Slave节点:2;

5.编辑配置文件/etc/profile
ZOOKEEPER_HOME=/usr/local/zookeeper/zookeeper-3.4.6

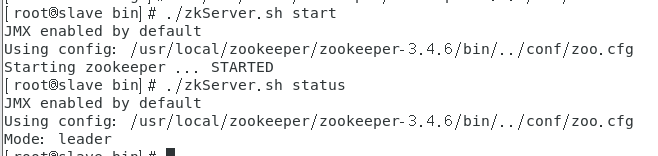
6.进入到bin目录下,执行 ./zkServer.sh start,启动zk服务
【注】:要两台都启动,可查看zookeeper.out日志文件查看错误
查看zookeeper状态,一个是leader,一个是follewer

6、安装hbase(主节点安装)
所有节点时间要同步!!!
【注】:
查看时间命令 timedatectl
调整硬件时间和本地一致 timedatectl set-local-rtc 1
linux同步时间 ntpdate ntp.sjtu.edu.cn
1.解压到/usr/local/hbase目录下
2.修改配置文件 ,到conf目录下
hbase-env.sh


hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://172.168.0.223:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>16010</value>
</property>
<property>
<name>hbase.regionserver.info.port</name>
<value>16030</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>Master,Slave</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/zookeeper/data</value>
</property>
<property>
<name>hbase.coprocessor.abortonerror</name>
<value>false</value>
</property>
</configuration>

regionservers (添加从节点)

/etc/profile
HBASE_HOME=/usr/local/hbase/hbase-2.0.5
最终主节点的/etc/profile文件中的配置

最终从节点的/etc/profile文件中的配置

3.scp拷到另一节点
scp -r /usr/local/hbase Slave:/usr/local
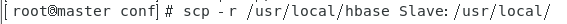
【注】:root用户可直接拷贝至/usr/local/目录下,非root用户可先拷贝至home目录在移动
4.启动hbase
./start-hbase.sh

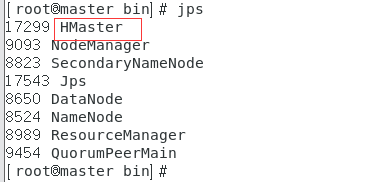
5.jps命令查看
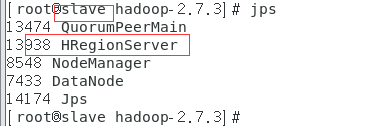
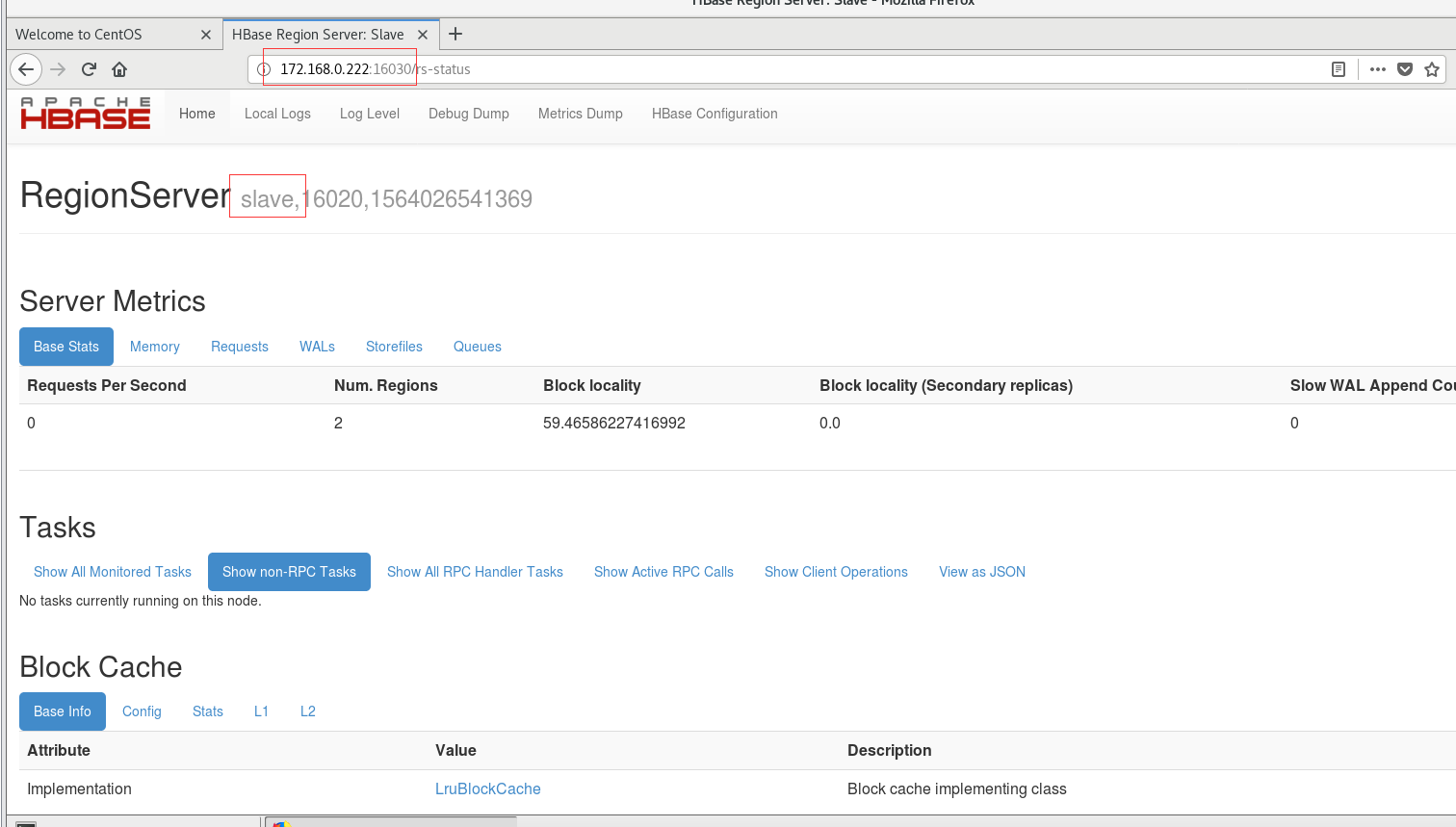
6.浏览器查看

centos7搭建hadoop-2.7.3,zookeeper-3.4.6,hbase-1.2.5(root用户)的更多相关文章
- CentOS7 搭建Kafka(一)zookeeper篇
CentOS7 搭建Kafka(一)zookeeper篇 近几年当红小生Kafka备受各路英雄好汉追捧,一点不比老前辈RabbitMQ和ActiveMQ差,因为流行,所以你就得学啊:我这么懒,肯定是不 ...
- centOS7搭建hadoop,zookeeper,hbase
1.配置ssh免密登录 (本人使用的是centOS7虚拟机) (本人未在root用户下安装,建议使用root用户,不然很麻烦!!) ① 本机无密钥登录 1.进入~/.ssh目录(若无,则执行一次ssh ...
- CentOS7搭建 Hadoop + HBase + Zookeeper集群
摘要: 本文主要介绍搭建Hadoop.HBase.Zookeeper集群环境的搭建 一.基础环境准备 1.下载安装包(均使用当前最新的稳定版本,截止至2017年05月24日) 1)jdk-8u131 ...
- 初学Hadoop:利用VMWare+CentOS7搭建Hadoop集群
一.前言 开始学习数据处理相关的知识了,第一步是搭建一个Hadoop集群.搭建一个分布式集群需要多台电脑,在此我选择采用VMWare+CentOS7搭建一个三台虚拟机组成的Hadoop集群. 注:1 ...
- centos7 搭建hadoop
参考文档:http://blog.csdn.net/xiaoxiangzi222/article/details/52757168 https://waylau.com/centos-7-instal ...
- Centos7搭建hadoop完全分布式
虽然说是完全分布式,但三个节点也都是在一台机器上.拿来练手也只能这样咯,将就下.效果是一样滴.这个我自己都忘了步骤,一起来回顾下吧. 必备知识: Linux基本命令 vim基本命令 准备软件: VMw ...
- 搭建Hadoop完全分布式
Centos7搭建hadoop完全分布式 虽然说是完全分布式,但三个节点也都是在一台机器上.拿来练手也只能这样咯,将就下.效果是一样滴.这个我自己都忘了步骤,一起来回顾下吧. 必备知识: Linux基 ...
- 搭建伪分布式 hadoop3.1.3 + zookeeper 3.5.7 + hbase 2.2.2
安装包 Hadoop 3.1.3 Zookeeper 3.5.7 Hbase 2.2.2 所需工具链接: 链接:https://pan.baidu.com/s/1jcenv7SeGX1gjPT9RnB ...
- 在Centos7下搭建大数据环境,即Zookeeper+Hadoop+HBase
1. 所需软件下载链接(建议直接复制链接到迅雷下载更快): ①hadoop-2.7.6.tar.gz: wget http://mirrors.tuna.tsinghua.edu.cn/apache/ ...
- Hadoop学习笔记—14.ZooKeeper环境搭建
从字面上来看,ZooKeeper表示动物园管理员,这是一个十分奇妙的名字,我们又想起了Hadoop生态系统中,许多项目的Logo都采用了动物,比如Hadoop采用了大象的形象,所以我们可以猜测ZooK ...
随机推荐
- ECMAScript中的原型继承
//ECMAScript中的原型继承//ECMAScript中的继承主要是依靠原型链实现的.(关于原型链的介绍,详见<高三>6.3.1章节 P162) //本文示例主要为了说明SubTyp ...
- Makefile中 -I -L -l区别
我们用gcc编译程序时,可能会用到"-I"(大写i),"-L"(大写l),"-l"(小写l)等参数,下面做个记录: 例: gcc -o he ...
- 调用打码平台api获取验证码 (C#版)
一.打码平台很多,这里选择两个:联众和斐斐 联众开发文档: https://www.jsdati.com/docs/guide 斐斐开发文档: http://docs.fateadm.com/web/ ...
- 09 redis中布隆过滤器的使用
我们在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉那些已经看过的内容.问题来了,新闻客户端推荐系统如何实现推送去重的? 会想到服务器记录了用户看过的所有历史记录,当推 ...
- jquery.serializejson.min.js的妙用
关于这个jquery.serializejson.min.js插件来看,他是转json的一个非常简单好用的插件. 前端在处理含有大量数据提交的表单时,除了使用Form直接提交刷新页面之外,经常碰到的需 ...
- 如何使用cgdb(一)——窗口切换
cgdb是一个轻量级的基于控制台的多窗口gdb调试界面.除了标准的gdb控制台之外,cgdb还提供了一个分屏视图,可以在执行的时候显示具备语法高亮的源代码.键盘控制是仿照vim设计的,所以vim用户使 ...
- ssh-copy-id三步实现SSH无密码登录和ssh常用命令
第一步:在本地机器上使用ssh-keygen产生公钥私钥对 $ ssh-keygen 第二步:用ssh-copy-id将公钥复制到远程机器中 $ ssh-copy-id -i .ssh/id_rsa ...
- android提升
https://blog.csdn.net/lou_liang/article/details/82856531
- scrapy 增量采集
在做新闻或者其它文章采集到时候,只想采集最新发布的信息,之前采集过得就不要再采集了,从而达到增量采集到需求 scrapy-deltafetch,是一个用于解决爬虫去重问题的第三方插件. scrapy- ...
- java——Servlet
类要实现Servlet接口: 主要功能,生成动态网页内容: HttpServlet重写doGet和doPost方法或者重写Service方法,完成对请求的响应: 如:get.post等请求的响应. - ...