seq2seq聊天模型(二)——Scheduled Sampling
使用典型seq2seq模型,得到的结果欠佳,怎么解决
结果欠佳原因在这里
- 在训练阶段的decoder,是将目标样本["吃","兰州","拉面"]作为输入下一个预测分词的输入。
- 而在预测阶段的decoder,是将上一个预测结果,作为下一个预测值的输入。(注意查看预测多的箭头)
这个差异导致了问题的产生,训练和预测的情景不同。
在预测的时候,如果上一个词语预测错误,还后面全部都会跟着错误,蝴蝶效应。

解决办法-Scheduled Sampling
修改训练时decoder的模型
基础模型只会使用真实lable数据作为输入, 现在,train-decoder不再一直都是真实的lable数据作为下一个时刻的输入。
train-decoder时以一个概率P选择模型自身的输出作为下一个预测的输入,以1-p选择真实标记作为下一个预测的输入。
Secheduled sampling(计划采样),即采样率P在训练的过程中是变化的。
一开始训练不充分,先让P小一些,尽量使用真实的label作为输入,随着训练的进行,将P增大,多采用自身的输出作为下一个预测的输入。
随着训练的进行,P越来越大大,train-decoder模型最终变来和inference-decoder预测模型一样,消除了train-decoder与inference-decoder之间的差异
总之:
通过这个scheduled-samping方案,抹平了训练decoder和预测decoder之间的差异!让预测结果和训练时的结果一样。
tensorflow
tensoflow已经完成了这个模型,直接调用,设定参数可以使用
training_helper = tf.contrib.seq2seq.ScheduledEmbeddingTrainingHelper(
inputs=dec_emb_inputs,
sequence_length=self.dec_sequence_length + 2,
embedding=self.dec_Wemb,
sampling_probability=self.sampling_probability,
time_major=False,
name='training_helper')
self.sampling_probability = tf.placeholder(
tf.float32,
shape=[],
name='sampling_probability')
# 下面这个时feed_dic
# 随着epoch的增大,sampling_probability_list逐渐变为1,即全部采用自身输出作为下个输入,
sampling_probability_list = np.linspace(
start=0.0,
stop=1.0,
num=n_epoch,
dtype=np.float32)
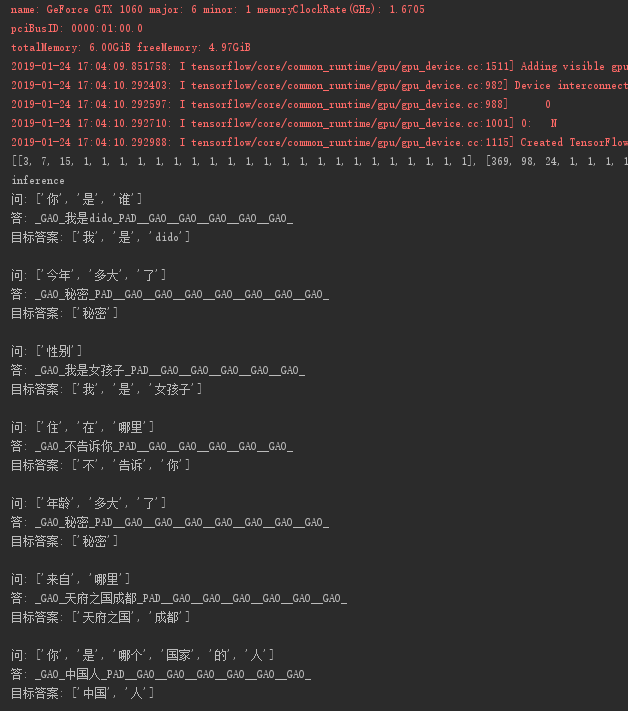
实际结果
效果很好
seq2seq聊天模型(二)——Scheduled Sampling的更多相关文章
- seq2seq聊天模型(一)
原创文章,转载请注明出处 最近完成了sqe2seq聊天模型,磕磕碰碰的遇到不少问题,最终总算是做出来了,并符合自己的预期结果. 本文目的 利用流程图,从理论方面,回顾,总结seq2seq模型, seq ...
- seq2seq聊天模型(三)—— attention 模型
注意力seq2seq模型 大部分的seq2seq模型,对所有的输入,一视同仁,同等处理. 但实际上,输出是由输入的各个重点部分产生的. 比如: (举例使用,实际比重不是这样) 对于输出"晚上 ...
- 深度学习教程 | Seq2Seq序列模型和注意力机制
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/35 本文地址:http://www.showmeai.tech/article-det ...
- django模型二
django模型二 常用模型字段类型 IntegerField → int CharField → varchar TextField → longtext DateFiel ...
- pytorch做seq2seq注意力模型的翻译
以下是对pytorch 1.0版本 的seq2seq+注意力模型做法语--英语翻译的理解(这个代码在pytorch0.4上也可以正常跑): # -*- coding: utf-8 -*- " ...
- socket实现聊天功能(二)
socket实现聊天功能(二) WebSocket协议是建立在HTTP协议之上,因此创建websocket服务时需要调用http模块的createServer方法.将生成的server作为参数传入so ...
- [Beego模型] 二、CRUD 操作
[Beego模型] 一.ORM 使用方法 [Beego模型] 二.CRUD 操作 [Beego模型] 三.高级查询 [Beego模型] 四.使用SQL语句进行查询 [Beego模型] 五.构造查询 [ ...
- {django模型层(二)多表操作}一 创建模型 二 添加表记录 三 基于对象的跨表查询 四 基于双下划线的跨表查询 五 聚合查询、分组查询、F查询和Q查询
Django基础五之django模型层(二)多表操作 本节目录 一 创建模型 二 添加表记录 三 基于对象的跨表查询 四 基于双下划线的跨表查询 五 聚合查询.分组查询.F查询和Q查询 六 xxx 七 ...
- {03--CSS布局设置} 盒模型 二 padding bode margin 标准文档流 块级元素和行内元素 浮动 margin的用法 文本属性和字体属性 超链接导航栏 background 定位 z-index
03--CSS布局设置 本节目录 一 盒模型 二 padding(内边距) 三 boder(边框) 四 简单认识一下margin(外边距) 五 标准文档流 六 块级元素和行内元素 七 浮动 八 mar ...
随机推荐
- Codefroces 1245 F. Daniel and Spring Cleaning
传送门 考虑简单的容斥 设 $F(n,m)$ 表示 $a \in [1,n] , b \in [1,m]$ 的满足 $a+b=a \text{ xor } b$ 的数对的数量 那么答案即为 $F(r, ...
- RabbitMq的环境安装
1.如图第一个是erlang语言的安装包,第二个是rabbitmq的安装包. 2.配置erlang语言环境,因为rabbitmq由erlang语言编写的,所以需要配置erlng语言环境. erlang ...
- IDEA忽略不必要提交的文件
1.在idea中安装插件用来生成和管理 .gitignore 文件,安装成功后重启idea 2.新建.gitignore 文件 3.将不需要提交的文件添加到.gitignore 4.删除缓冲文件 . ...
- Asp.Net Core 轻松学系列-2从安装环境开始
Asp.Net Core 介绍 Asp.Net Core是微软新一代的跨平台开发框架,基于 C# 语言进行开发,该框架的推出,意味着微软从系统层面正式进击 Linux 服务器平台:从更新速度开 ...
- MYSQL编码转换的问题latin1转utf8
1.先导出 mysqldump --default-character-set=latin1 --create-options=false --set-charset=false -u root - ...
- Servlet实现图片文件上传
1.首先要导入以下两个jar包: commons-fileupload-1.2.1.jarcommons-io-1.4.jar 2.jsp文件:index.jsp <%@ page langua ...
- 记录下js几种常见的数组排序和去重的方法
冒泡排序 , , , , , , , ]; function test(){ ; i < arr.length - ; i++){ ; j < arr.length; j++){ var ...
- perl语言的线程使用
参考的教程链接是 https://www.cnblogs.com/migrantworkers/p/6973459.html 1.Perl 多线程的使用,join 和 detach 的区别 ,join ...
- 卷积神经网络(CNN)的训练过程
卷积神经网络的训练过程 卷积神经网络的训练过程分为两个阶段.第一个阶段是数据由低层次向高层次传播的阶段,即前向传播阶段.另外一个阶段是,当前向传播得出的结果与预期不相符时,将误差从高层次向底层次进行传 ...
- 用javafx webview 打造自己的浏览器
背景 项目需要做一个客户端的壳,内置浏览器,访问指定 的url 采用技术 java 1.8 开始吧! java环境配置略 hello world import javafx.application.A ...