ng-深度学习-课程笔记-15: 循环序列模型(Week1)
1 数学符号(Notation)
$ x^{<1>}, x^{<2>}, ..., x^{<t>}, ..., x^{<q>} $ 表示一段输入序列x,比如一句文字
$ y^{<1>}, y^{<2>}, ..., y^{<t>}, ..., y^{<q>} $ 表示输出序列y
$ T_{x} = T_{y} = q, $ 表示长度,x和y在长度可以不相等
$ x^{(i)<t>}, y^{(i)<t>}$ 表示第i个样本的第t个元素
$ T_{x}^{(i)}, T_{y}^{(i)} $ 表示第i个样本的x长度和y长度
构建一个表示单词的词典,对一般规模的商业应用来说3万到5万的大小比较常见,也有10万的,而大型互联网公司会用百万级甚至更大的词典。
例子中词典以1万词为例,统计常用的1万个词,使用one-hot来表示每个单词,由此来表示整段文字。对于不存在于词典的单词可以构建一个unknown词来表示。
2 循环神经网络模型(Recurrent Neural Network Model)
为什么不使用标准的神经网络呢?主要有两个问题。
首先时序问题中输入和输出都可以是不同长度的,你当然可以用填充来使输入输出单元数最大,但仍然不是很好的表示方式。
其次,单纯的神经网络并不能共享从文本的不同位置学到的特征,具体表现为,如果能学到了位置1出现的harry为人名的概率,当harry出现在其它位置时,也能自动识别为人名,这样就很棒了。
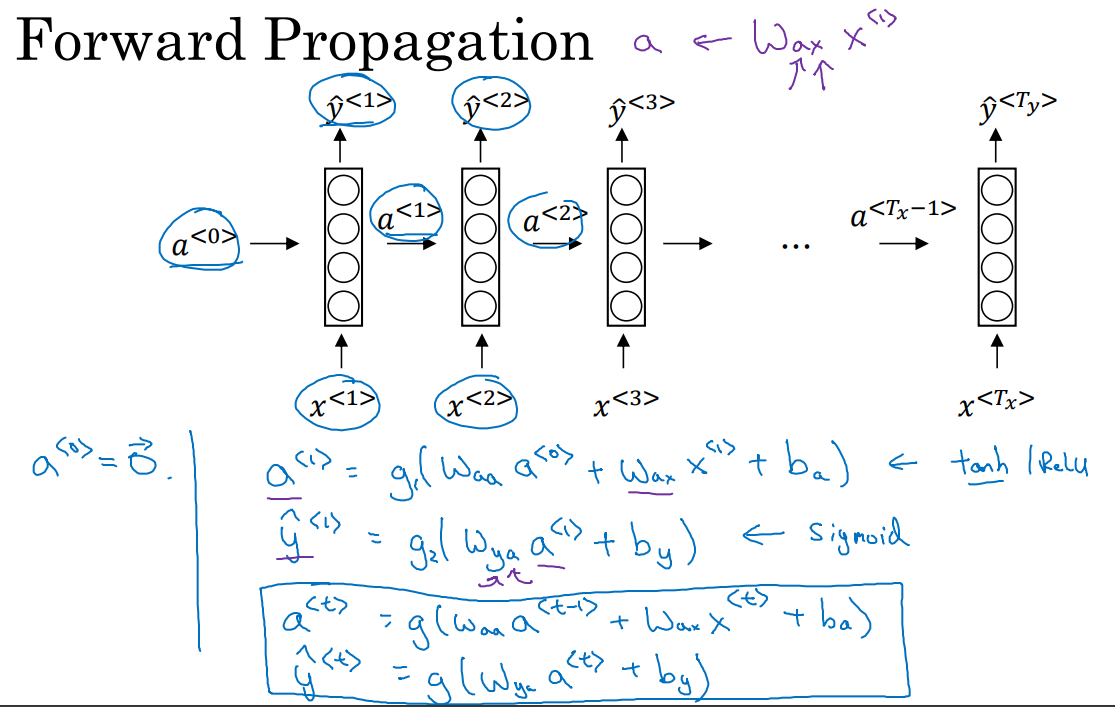
如下图所示,循环神经网络做的就是,在第一个时间步用$ x^{<1>} $ 来预测 $ y^{<1>} $
但是在第二个时间步的不仅接收$ x^{<1>} $ ,还接收来自第一个时间步的信息,以此类推。
要开始整个步骤,需要在第一个时间步接收一个默认的$ a^{<0>} $ 表示“来自第0个时间步的信息”,0向量是常见的选择,也可以随机初始化。
每个时间步的参数是共享的,记为$ W_{ax} $,下标ax中的x表示和x相乘,a表示计算a
水平激活值的参数记为 $ W_{aa} $,下标aa中的a表示和a相乘,计算a
输出激活值的参数记为 $ W_{ya} $,下表ya中的a表示和a相乘,y表示计算y
这个例子中,对序列的扫描是从左到右的,只使用了之前的信息来做出预测。使用BRNN则可以使用之前和之后的信息来预测。
输出a的激活函数g通常使用tanh,然后可以使用另外的方法来避免梯度消失。
输出y的激活函数决定于你的问题,如果是二分类则可能使用sigmoid
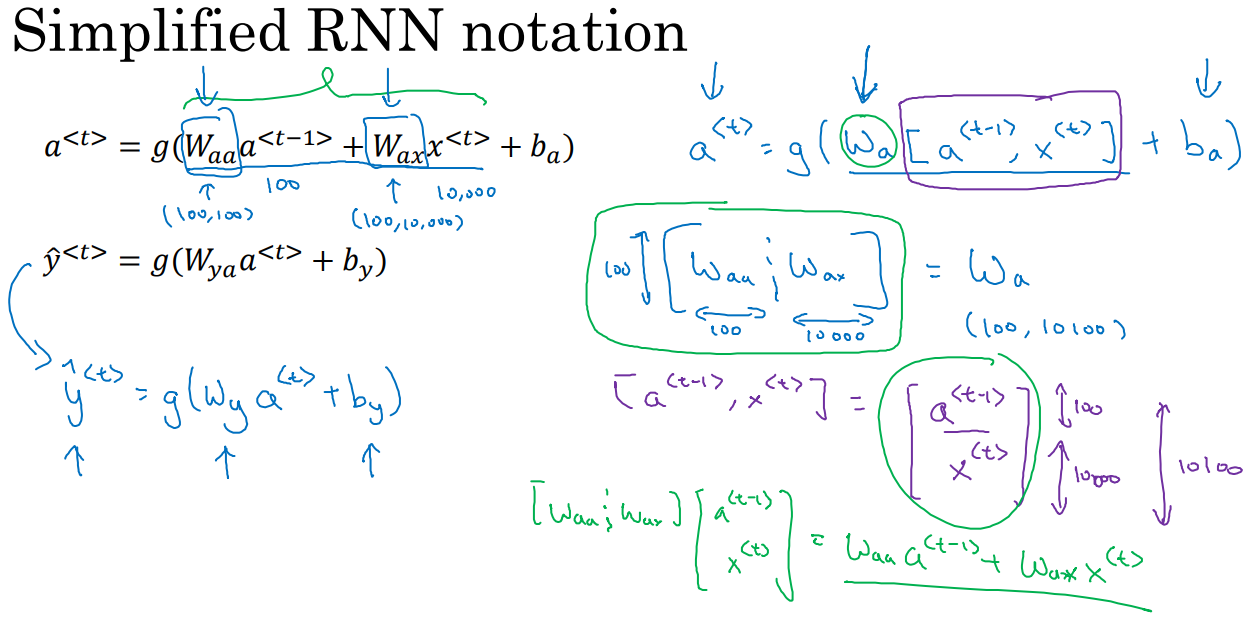
为了简化符号,$ W_{ya} = W_{y} $
为了简化符号,可以将两个W合并: $ [ W_{aa} | W_{ax} ] = W_{a} $
3 不同类型的循环神经网络(Different types of RNNs )
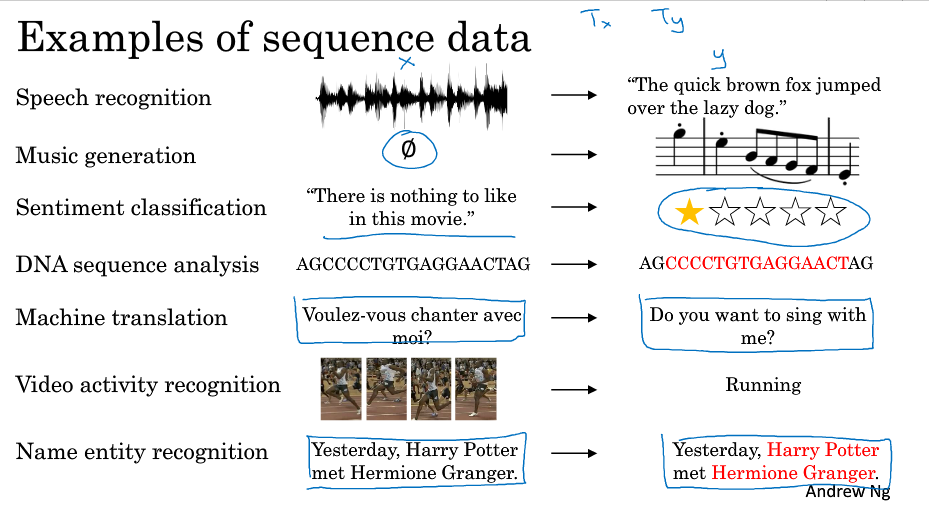
$ T_{x}, T_{y} $ 不一定相同,比如下图的几个例子中,音乐生成的输入可以为长度为1或空集而输出是一段序列;感情分类的输出可以是1到5的整数而输入是一个序列;命名实体识别中,输入和输出长度相同;机器翻译中输入和输出的序列长度不同。
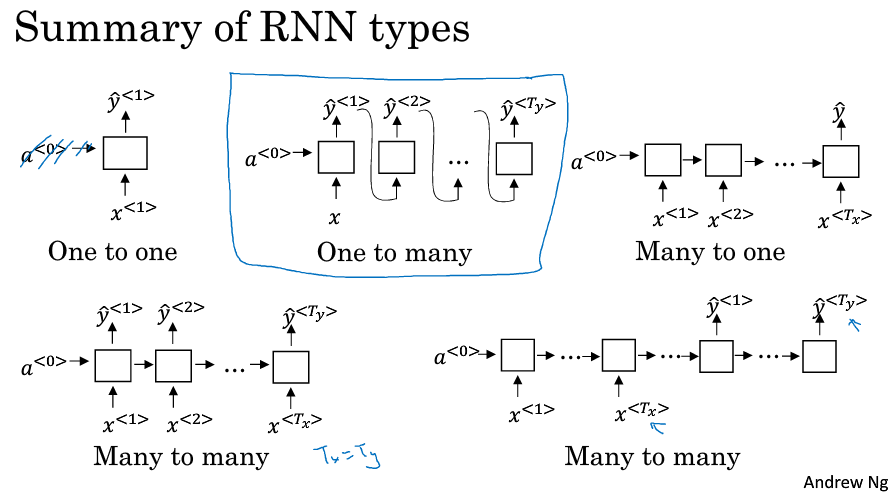
基于此,可以分为几种不同的结构:
One-to-one(标准的神经网络,不需要RNN)
One-to-many (比如音乐生成)
Many-to-one(比如评论的情感分类)
Many-to-many(又分为输入和输出长度相同的和不同的,比如命名实体识别和机器翻译)
4 语言模型和序列生成(Language model and sequence generation)
如何用RNN来构建一个语言模型呢?
首先需要一个很大的文本语料库作为训练集,语料库由数量众多的句子组成。
假如你在语料库中得到一句话,你需要将它们切分标记(tokenize)为一个个one-hot向量,在这个过程可以自行决定要不要忽略标点
在某些应用中需要用额外的标记<EOS> 来定义句子的结尾
对于在字典中未出现的单词可以标记为<UNK>来统一处理
$ \hat{y}^{<1>} $ 是表示第一个位置出现的词的概率,根据softmax输出整个词典上的10002个词的概率,包括结束词和未知词,最后得到Cats的概率最大
预测 $ \hat{y}^{<2>} $ 的时候输入为y<1>,这个情况预测的是在第一个词为cats的情况下,为其它词的概率:P(词 | cats)
后面的时间步以此类推,最后得到P(EOS | ...)的概率。
定义每个时间步的softmax损失函数,求和得到最终的损失函数,然后优化。
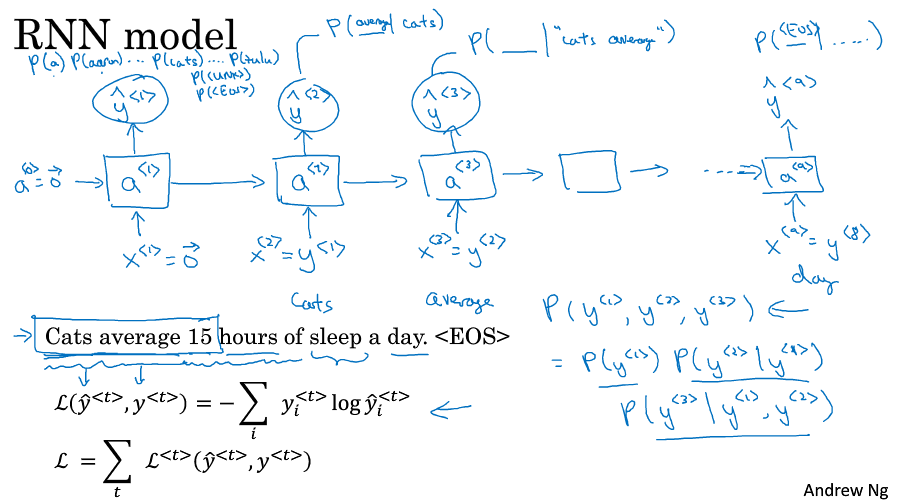
5 RNN的梯度消失(Vanishing gradients with RNNs)
RNN和标准NN一样,随着网络层数的增加,导数有可能呈指数型减小或增加,容易发生梯度消失和梯度爆炸的问题。
对于梯度爆炸的问题很容易发现,你会发现很多NaN和非数字的情况,意味着神经计算出现了数值溢出,可以使用梯度裁剪(gradient clipping),观察某个梯度,当它大于某个阈值的时候,缩放梯度向量保证它不会太大。
然而梯度消失更难解决,接下来几节将介绍解决方法。
6 GRU单元(Gated Recurrent Unit)
标准的RNN利用上一时间步的激活值a和这一时间步的输入x计算出这一时间步的激活a $ a^{<t>} = g( W_a [a^{<t-1>}, x^{t}] + b_a) $
然后用激活a计算这一时间步的输出y: $ \hat{y}^{<t>} = g( W_y a^{t} + b_y ) $
GRU,为了句子能在猫吃了很多东西之后,仍然能对be动词形式做出正确判断(was还是were),用了细胞单元来记忆信息。
在GRU这里,记忆单元c会输出激活值a,二者是一样的,在LSTM中这两者代表的是不同值。
在每个时间步计算一个候选值 $ \tilde{c}^{<t>} = tanh( W_c [ c^{<t-1>}, x^{<t>} ] + b_c ) $
GRU重要的思想是使用一个更新门 $ \Gamma_u = \sigma ( W_u [ c^{<t-1>}, x^{<t>} ] + b_u ) $ ,它的输出在0到1之间,大部分的输出是在非常接近0或非常接近1。
由更新门来决定是否更新记忆单元的值,这样在扫描整句话的时间,在每个时间步就会决定是要更新还是不更新记忆信息,比如例子中的cat的相关信息就会被一直保存,直到遇到要选择was/were的时候,就根据记忆单元里的cat信息来做出判断,随后就可以不再保存记忆单元中的cat信息
$ c^{<t>} = \Gamma_u * \tilde{c}^{<t>} + (1 - \Gamma_u) * c^{<t-1>}$
更新/保存的c会传到下一时间步,另外可以根据更新/保存的c计算出这一时间步的输出y
更新门的作用就是保存记忆信息,然后一直不更新,直到需要使用的时候。
由于更新门很容易取到一个很接近0的数,那么c的值被保留下来了,这样就可以缓解梯度消失的问题了,因为即使经过很多很多时间步,历史信息依然被保存下来了,因此允许神经网络训练有着非常庞大依赖范围的序列,比如例子中的cat和was被很多句子分割开。
更新门不只能保存cat和was的关系信息,比如它们维度是100,那么就可以保存100种类型的记忆信息,决定是否更新,你可以决定一些比特更新而另一些比特不更新。
现实中的更新门比特不是确切的0/1,只是接近的值。
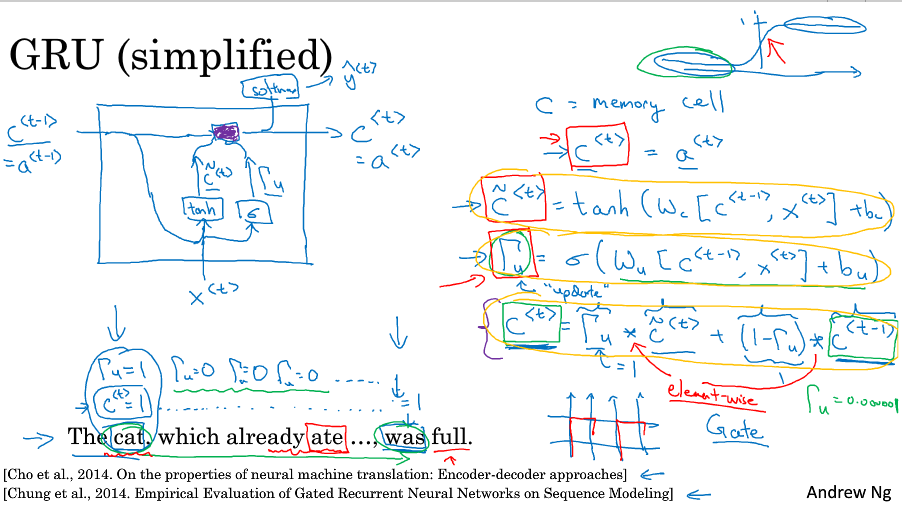
上述说的是一个简化后的GRU,完整的GRU会增加一个相关门,如下图所示。
有很多设计使得网络的类型多种多样,多年来科研人员做了很多实验来设计这些单元,尝试让深度网络产生更大范围的影响,还有解决梯度消失的问题,GRU就是研究者们常用的一个版本,也被发现在很多不同问题上也是非常健壮和实用的。研究者们也尝试了很多其它版本,类似的但是不完全一样(similar but exactly not the same)
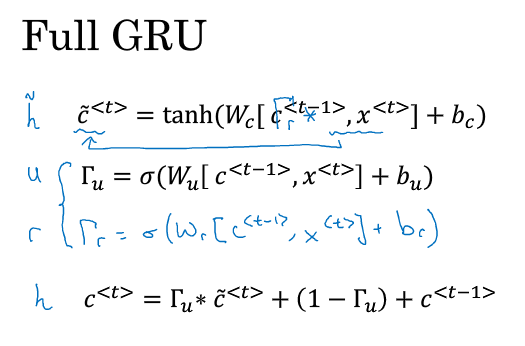
7 LSTM(long short term memory )unit
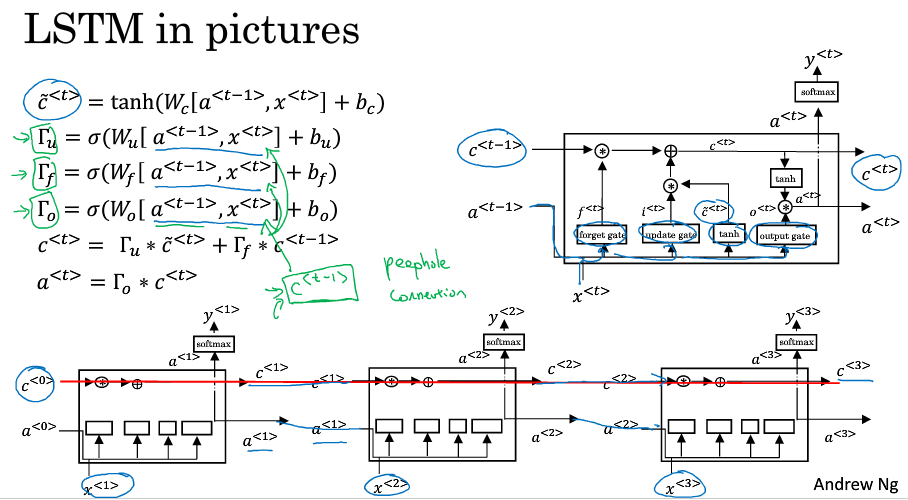
LSTM中细胞单元c不再等于激活值a,计算候选值使用的是激活值a,$ \tilde{c}^{<t>} = tanh( W_c [ a^{<t-1>}, x^{<t>} ] + b_c ) $
LSTM中使用三个门,更新门,遗忘门和输出门。
$ \Gamma_u = \sigma ( W_u [ a^{<t-1>}, x^{<t>} ] + b_u ) $
$ \Gamma_f = \sigma ( W_f [ a^{<t-1>}, x^{<t>} ] + b_f ) $
$ \Gamma_o = \sigma ( W_o [ a^{<t-1>}, x^{<t>} ] + b_o ) $
细胞的更新不再像GRU一样用单独的更新门控制,而是用更新门和遗忘门来控制
$ c^{<t>} = \Gamma_u * \tilde{c}^{<t>} + \Gamma_f * c^{<t-1>}$
最后的激活值由输出门来控制 $ a^{<t>} = \Gamma_o * c^{<t>}$

如下图所示,再c更新的那条连着的横线中可以看出,只要合理地设置三个门,c的值是可以一直往下一个时间步传递下去的。
此外还有另外的版本,在计算三个门的时候不只用到a和x,还加入了上一个细胞的信息$ c^{<t-1>} $ ,这叫作窥视孔连接(peephole connection)
对于使用GRU还是LSTM,没有统一的准则,LSTM通常是默认的选择,但是GRU也获得了很多的支持因为它简单而且效果还不错。
GRU是在LSTM的基础上进行的简化,他的优点是更加简单,更容易创建一个更大的网络,而且它只有两个门,运行得更快。
但LSTM更加强大和灵活,因为它有三个门而不是两个。
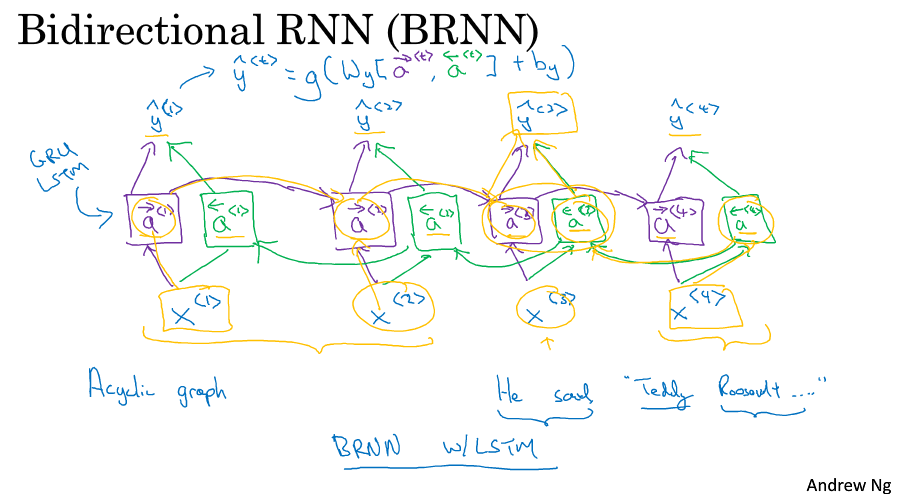
8 双向RNN(Bidirectional RNN)
双向RNN可以让你在序列的某点既能获取之前的信息,也能获取未来的信息。
如图所示,就是反向连接一下,这样就有两个输出a,接在一起来决定最后的输出y。
每个模块可以是传统RNN也可以是LSTM也可以是GRU。
事实,上对于很多包含大量文本的NLP问题,带LSTM的双向RNN模型是最常用的。
双向RNN的一个缺点就是你需要完整的数据序列,你才能预测任意位置。
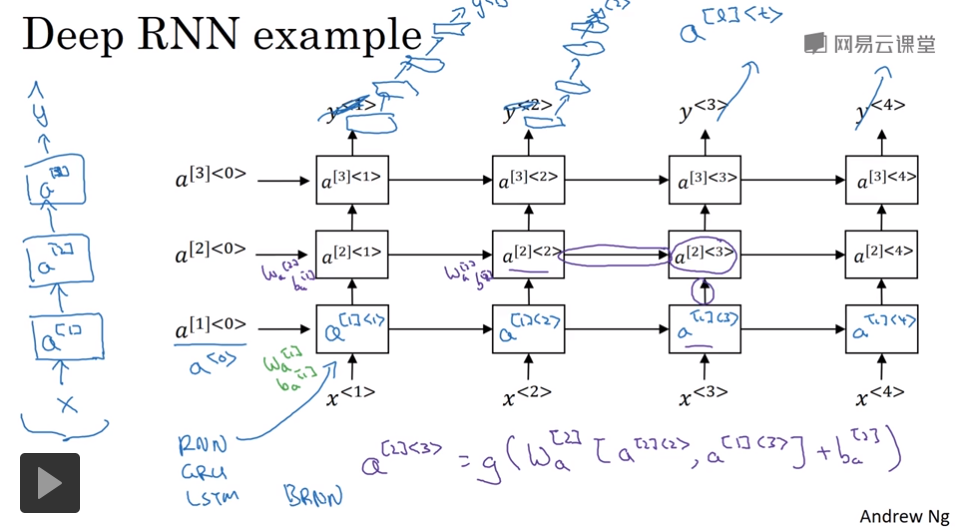
9 深层循环神经网络(Deep RNNs)
通常会把多个RNN叠起来构建更深的模型,如下图所示,是一个三隐层的RNN。
ng-深度学习-课程笔记-15: 循环序列模型(Week1)的更多相关文章
- 深度学习课程笔记(八)GAN 公式推导
深度学习课程笔记(八)GAN 公式推导 2018-07-10 16:15:07
- 深度学习课程笔记(十一)初探 Capsule Network
深度学习课程笔记(十一)初探 Capsule Network 2018-02-01 15:58:52 一.先列出几个不错的 reference: 1. https://medium.com/ai% ...
- 深度学习课程笔记(十八)Deep Reinforcement Learning - Part 1 (17/11/27) Lectured by Yun-Nung Chen @ NTU CSIE
深度学习课程笔记(十八)Deep Reinforcement Learning - Part 1 (17/11/27) Lectured by Yun-Nung Chen @ NTU CSIE 201 ...
- 深度学习课程笔记(十七)Meta-learning (Model Agnostic Meta Learning)
深度学习课程笔记(十七)Meta-learning (Model Agnostic Meta Learning) 2018-08-09 12:21:33 The video tutorial can ...
- 深度学习课程笔记(十六)Recursive Neural Network
深度学习课程笔记(十六)Recursive Neural Network 2018-08-07 22:47:14 This video tutorial is adopted from: Youtu ...
- 深度学习课程笔记(十五)Recurrent Neural Network
深度学习课程笔记(十五)Recurrent Neural Network 2018-08-07 18:55:12 This video tutorial can be found from: Yout ...
- 深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO)
深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO) 2018-07-17 16:54:51 Reference: https://b ...
- 深度学习课程笔记(十三)深度强化学习 --- 策略梯度方法(Policy Gradient Methods)
深度学习课程笔记(十三)深度强化学习 --- 策略梯度方法(Policy Gradient Methods) 2018-07-17 16:50:12 Reference:https://www.you ...
- 深度学习课程笔记(十)Q-learning (Continuous Action)
深度学习课程笔记(十)Q-learning (Continuous Action) 2018-07-10 22:40:28 reference:https://www.youtube.com/watc ...
随机推荐
- angularjs基础——变量绑定
1)弄一个ng-app(angularjs 应用) 2)在里面用ng-model(angularjs 模型)就可以定义一个模型变量 3)使用模版方法就可以输出变量了(例如:{{name}}) 示例: ...
- 查看系统负载:uptime
uptime命令用于查看系统负载,跟 w 命令的输出内容一致 [root@localhost ~]$ uptime :: up days, :, users, load average: 0.03, ...
- MFC-TCP连接代码片段(支援大富的)
BOOL CClientSocketTestDlg::OnInitDialog() { CDialogEx::OnInitDialog(); ........................ // T ...
- IntersectRect、wcsrchr、CComPtr、GetFileAttributes
IntersectRect 两矩形相交形成的新矩形 The IntersectRect function calculates the intersection of two source re ...
- 谷歌Volley网络框架讲解——Network及其实现类
我们看到Network接口只有一个实现类BasicNetwork,而HttpStack有两个实现类. BasicNetwork这个类是toolbox工具箱包里的,实现了Network接口. 先来看下N ...
- MyBatis——Mapper XML 文件
Mapper XML 文件 MyBatis 的真正强大在于它的映射语句,也是它的魔力所在.由于它的异常强大,映射器的 XML 文件就显得相对简单.如果拿它跟具有相同功能的 JDBC 代码进行对比,你会 ...
- CentOS下安装cvechecker并进行主机基线安全检查
一.cvechecker的安装 1.首先下载cvechecker并解压该文件: cd /home/username mkdir cve wget https://raw.githubuserconte ...
- 《FPGA那些事儿》原创教程总结
经过我们黑金工程师多年的不断努力,黑金原创教程已经达到了14部,包括: 第一部:[黑金原创教程]NIOSII那些事儿 http://www.heijin.org/forum.php?mod=viewt ...
- Android中textView自动识别电话号码,电子邮件,网址(自动加连接)
extends:http://blog.csdn.net/wx_962464/article/details/8471195 其实这个是很简单的,在android中已经为我们实现了,但是我估计很多人都 ...
- Javaweb程序打包或exe执行文件
java程序的打包与发布 这里主要是讲解一下怎样将 Java程序打包成独立运行的exe程序包,以下这种方法应该是最佳的解决方案了.NetDuke的EXE程序包了是使用这种方案制作的.在操作步骤上还是比 ...