吴裕雄--天生自然python数据清洗与数据可视化:MYSQL、MongoDB数据库连接与查询、爬取天猫连衣裙数据保存到MongoDB
本博文使用的数据库是MySQL和MongoDB数据库。安装MySQL可以参照我的这篇博文:https://www.cnblogs.com/tszr/p/12112777.html
其中操作Mysql使用到的python模块是pymysql,下面是有关这个模块的使用说明:

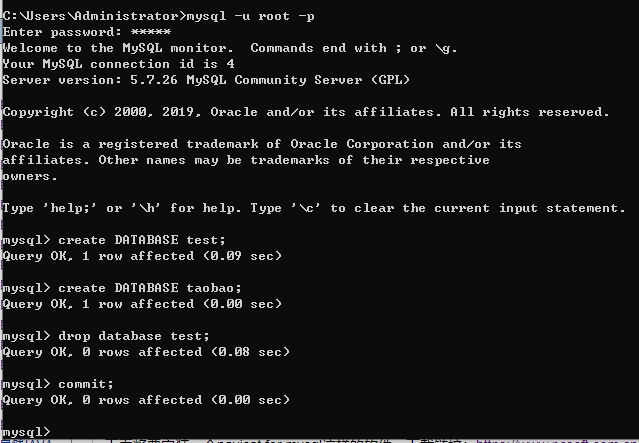
创建一个数据库test
create DATABASE taobao;
下面将要安装一个navicat for mysql这样的软件,下载链接:https://www.pcsoft.com.cn/soft/20832.html?t=1523022368482
Navicat for MySQL功能:
1.Navicat for MySQL支持创建工具或编辑器数据模型工具
2.支持数据传输/导入/导出、数据或结构同步等
3.Navicat for MySQL支持查询参数
4.Navicat for MySQL支持SSH密钥等
5.界面设计直观简洁,兼容性强
6.专业:适合专业人士,也非常适合入门新手使用
下面开始安装这个软件:

Navicat for MySQL使用方法
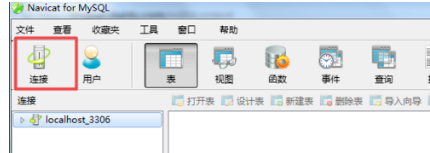
1、打开安装好的Navicat for MySQL,打开软件后,点击【连接】选项
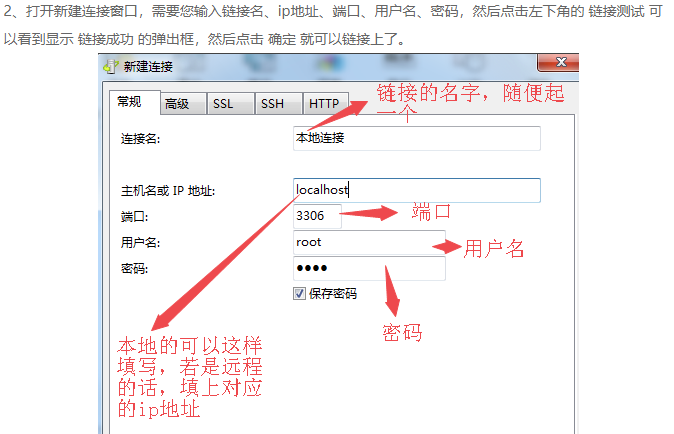
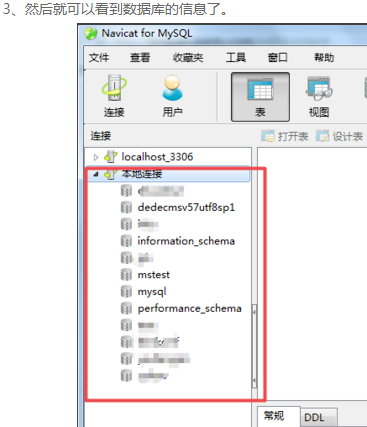
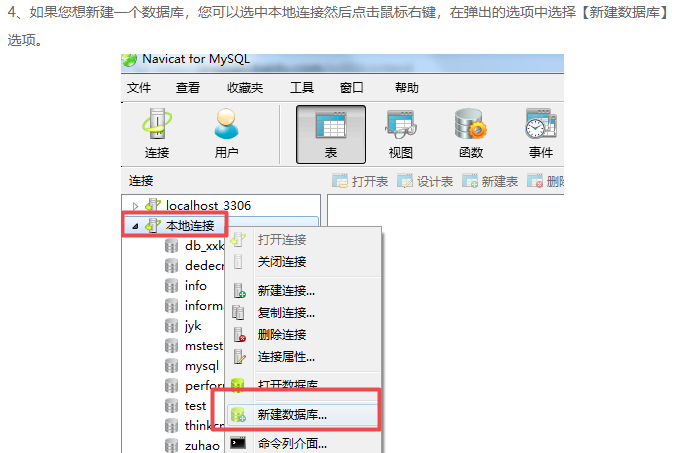




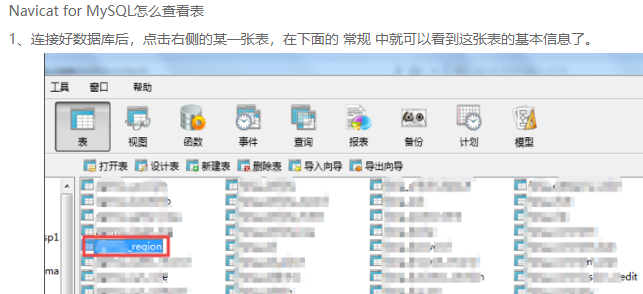
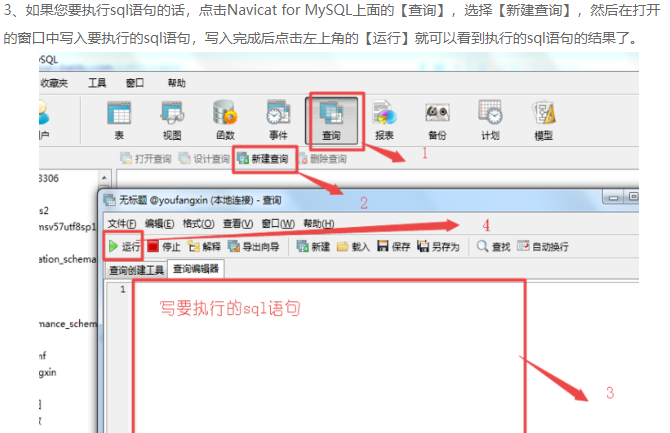
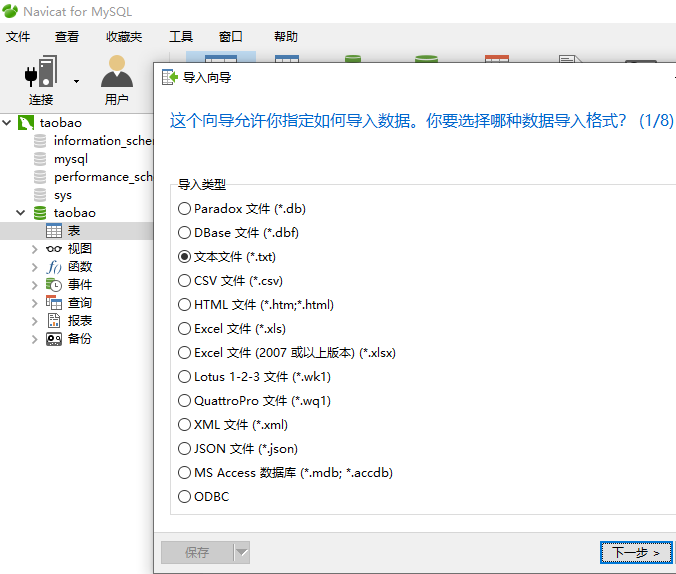
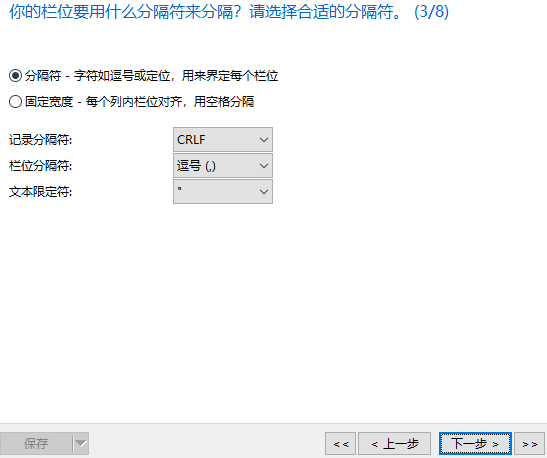
下面是将sale_data.txt这份文件的数据导入到MySQL taobao数据库中



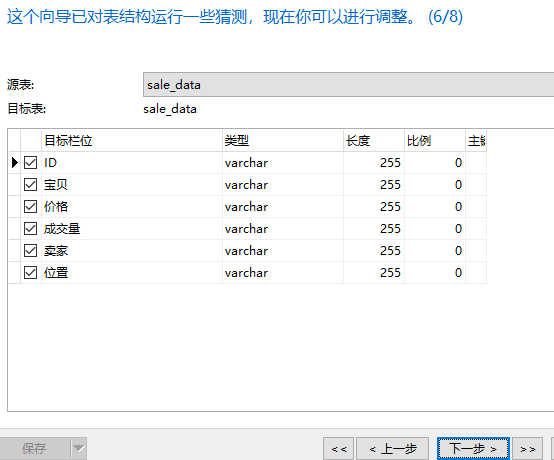


可以看到数据已经成功导入到数据库里面了。
下面修改数据库ID这个字段,修改为可以自动增加的。
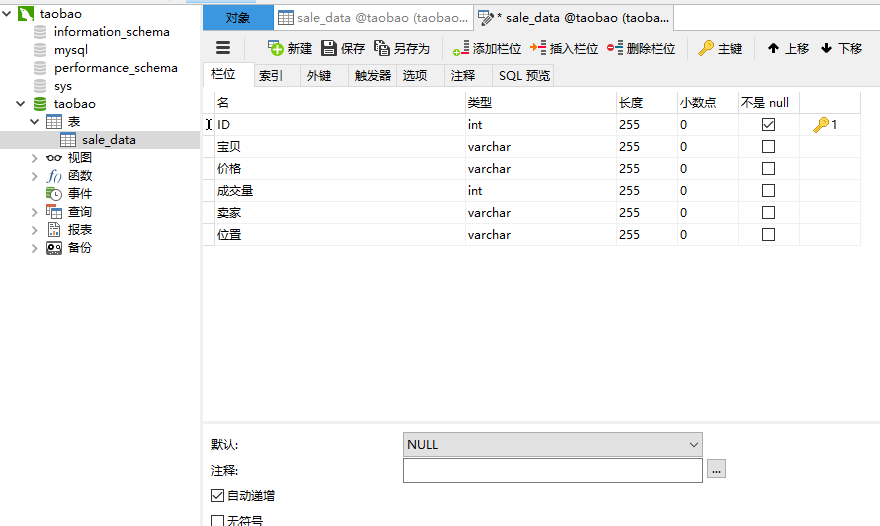
选中左边数据表 鼠标右键选择:设计表就可以出现上面的这个界面了。修改后记得要保存。
接下来就可以使用代码来操作数据库了。
import pymysql #连接数据库
db = pymysql.Connect(host="localhost",port=3306,user="root",password="admin",db="taobao",charset="utf8")
print("连接成功!")

#查询商品在江、浙、沪的销量
#获取游标
cursor = db.cursor()
#执行SQL语句进行查询
sql = "SELECT * FROM sale_data where 位置 IN (%s,%s,%s)"
cursor.execute(sql,("江苏","浙江","上海"))
#获取查询结果
result = cursor.fetchall()
for item in result:
print(item)

#删除价格低于100的商品
sql = "delete from sale_data where 价格<100"
cursor.execute(sql)
#没有设置默认自动提交,所以这里需要主动提交,以保存执行后的结果在数据库
db.commit()
print("删除成功!")

#把位置是江苏、浙江、上海的统一修改为:江浙沪,代码如下:
sql = "update sale_data set 位置 = %s where 位置 in (%s,%s,%s)"
cursor.execute(sql,("江浙沪","江苏","浙江","上海"))
db.commit()
print("修改成功!")

#添加一条新的销售记录
sql = "insert into sale_data(宝贝,价格,成交量,卖家,位置) values (%s,%s,%s,%s,%s)"
cursor.execute(sql,("2017夏季连衣裙",223,1897,"XX天猫","乌鲁木齐"))
db.commit()
print("添加成功!")

#关闭数据库连接
cursor.close()
db.close()
使用SQLAlchemy库





SQLAlchemy的基本语法:
新建一个person表
CREATE TABLE IF NOT EXISTS person (ID int PRIMARY KEY AUTO_INCREMENT,name varchar(10) not null,age int not null);


可以看到person表已经成功创建了。
然后写代码。
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine,Column,Integer,String DIALCT = "mysql"
DRIVER = "pymysql"
USERNAME = "root"
PASSWORD = "admin"
HOST = "127.0.0.1"
PORT = ""
DATABASE = "taobao" DB_URI="{}+{}://{}:{}@{}:{}/{}?charset=utf8".format(DIALCT,DRIVER,USERNAME,PASSWORD,HOST,PORT,DATABASE)
engine = create_engine(DB_URI)
Base = declarative_base(engine)
# 创建session 会话对象
session = sessionmaker(engine)()
class Person(Base):
__tablename__ = "person"
ID = Column(Integer,primary_key=True,autoincrement=True)
name = Column(String(10),nullable=False)
age = Column(Integer,nullable=False)
#定义__repr__方法:将对象的属性方法打印成一个可读字符串
def __repr__(self):
return "ID:%s,name:%s,age:%s," % (self.ID,self.name,self.age)
# 添加数据
def add_data():
# 向表中添加一条数据
person = Person(name="jack",age=20)
session.add(person)
# 添加数据后、数据保存到电脑内存上,并没有添加到数据库中,需使用 session.commit() 方法将数据提交到数据库中。
session.commit()
add_data()
然后运行代码。

可以看到已经成功添加进入这条记录了。
再建立一张Product表:
CREATE TABLE IF NOT EXISTS Product (ID int PRIMARY KEY AUTO_INCREMENT,name varchar(20) not null);


from sqlalchemy.orm import sessionmaker
from sqlalchemy import Column,String,create_engine
from sqlalchemy.ext.declarative import declarative_base #创建对象的基类
Base = declarative_base()
#定义Product对象
class Product(Base):
#表名称
__tablename__ = "Product"
#表结构
ID = Column(String(20),primary_key = True)
name = Column(String(20))
#定义__repr__方法:将对象的属性方法打印成一个可读字符串
def __repr__(self):
return "ID:%s,name:%s,age:%s," % (self.ID,self.name) #初始化数据库连接
engine = create_engine("mysql+pymysql://root:admin@localhost:3306/taobao")
#创建DBSession类型
DBSession = sessionmaker(bind=engine)
#创建session对象,DBSession对象可视为当前数据库的连接
session = DBSession()
#创建新Product对象
new_user = Product(ID="",name="豪华餐厅")
#添加到session
session.add(new_user)
#提交即保存到数据库中
session.commit()

可以看到已经成功把数据添加到数据库了。
#从数据库表中查询数据
#创建Query查询,filter是where条件,最后调用one()返回唯一一行,如果调用all()则返回所有行
student = session.query(Product).filter(Product.ID=='').one()
#打印对象的name,class.name属性
print('name:',student.name)

#在数据库表中更新数据
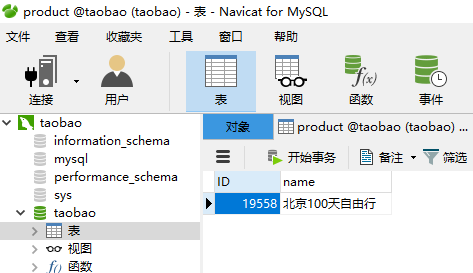
session.query(Product).filter(Product.ID=='').update({Product.name:'北京100天自由行'})
session.commit()
print('修改成功')
#查询并删除数据
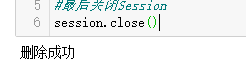
session.query(Product).filter(Product.ID=='').delete()
session.commit()
print('删除成功')
#最后关闭Session
session.close()
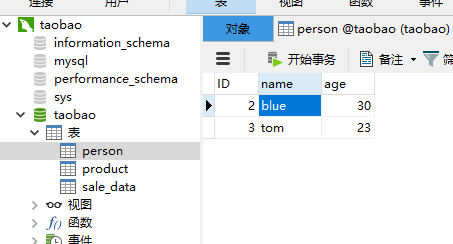
再回到person表的操作:
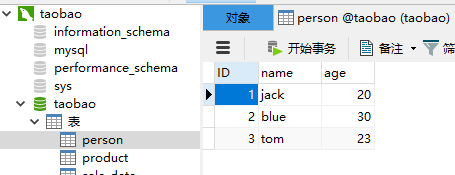
# 向表中添加多条数据(如需添加多条数据、只需使用add_all方法将多条数据添加到一个列表即可)
person1 = Person(name = "blue" , age = 30)
person2 = Person(name = "tom" , age = 23)
session.add_all([person1,person2])
session.commit()
print("添加成功")

#查询数据
def select_data():
# 查询表中所有数据
results = session.query(Person).all()
for r in results:
print(r) select_data()

# 查询表中第一条数据
first = session.query(Person).first()
print(first)

# 查询表中name为tom的第一条数据
result = session.query(Person).filter_by(name = "tom").first()
print(result)

# 查询表中年龄大于20的数据(结果为list,故用for循环遍历)
results = session.query(Person).filter(Person.age > 20).all()
for r in results:
print(r)

# filter: 多用于简单查询,filter_by:用于复杂查询,使用filter_by作为查询过滤条件时,需在前面添加对象名,如Person.age
#修改数据
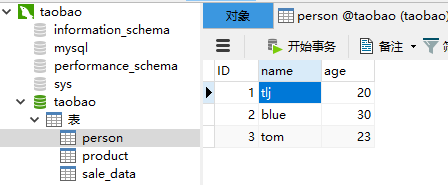
def update_date():
# 查询表中第一条数据,将其姓名修改为 tlj
result = session.query(Person).first()
result.name = "tlj"
session.commit()
print(result) update_date()

#删除数据
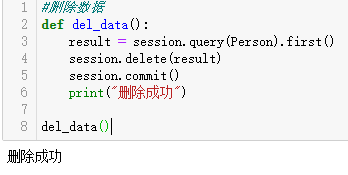
def del_data():
result = session.query(Person).first()
session.delete(result)
session.commit()
print("删除成功") del_data()
下面是有关MongoDB数据库的操作。
相关的安装过程请参考我的这篇博文:https://www.cnblogs.com/tszr/p/12192354.html
下面是基本语法的使用:
#加载库
import pymongo #建立连接
client = pymongo.MongoClient("localhost",27017)
#新建数据库
db = client["db_name"]
#新建表
table = db["table_name"]
#写入数据
table.insert({"key1":"一","key2":"二"})
#删除数据
table.remove({"key1":"一"})
#修改数据
table.update({"key2":"二"},{"$set":{"key2":"二","key5":"五"}})
#查询数据
table.find({"key5":""})
下面是爬取天猫连衣裙数据保存到MongoDB

#在某电商网站搜索连衣裙的商品数据,并把第一页商品数据抓取下来保存到MongoDB中
import pymongo
import requests client = pymongo.MongoClient("localhost",271017)
#新建数据库
taobao = client["taobao"]
#新建表
search_result = taobao["search_result"]
#爬取某电商网站商品数据
url = "https://list.tmall.com/search_product.htm?q=%C1%AC%D2%C2%C8%B9&type=p&vmarket=&spm=a2156.1676643.a2227oh.d100&from=mallfp..pc_1_searchbutton"
strhtml=requests.get(url)
#转变数据类型
strhtm = strhtml.text
#导入re库
import re #查找所有月成交量
ycjl = re.findall('<span>月成交 <em>(.*?)</em></span>',strhtm)
print(ycjl)

#找出所有商品的价格
price = re.findall('<em title="(.*?)"><b>¥</b>(.*?)</em>',strhtm)
list_price = []
for item in price:
list_price.append(item[0])
print(list_price)

#保存所有的商品名称
a = "<a (.*?) >\n(.*?)\n</a>"
b = re.findall(a,strhtm)
c = dict(b)
name = []
for i in c:
name.append(c[i])
numb = min(len(name),len(list_price),len(ycjl))
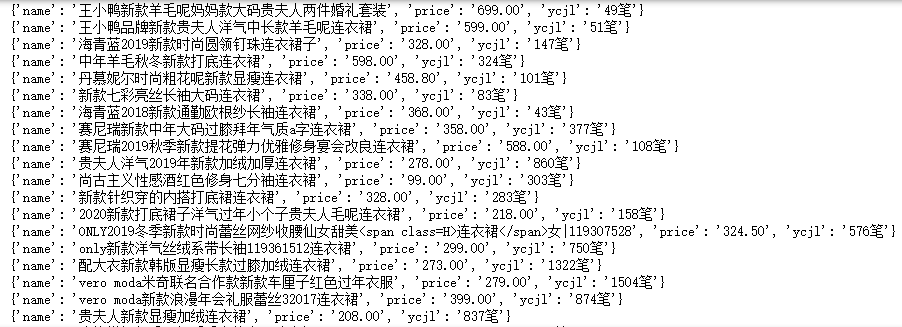
for i in range(0,numb):
json_data = {
'name':name[i],
'price':list_price[i],
'ycjl':ycjl[i]
}
print(json_data)
#写入数据
search_result.insert(json_data)
吴裕雄--天生自然python数据清洗与数据可视化:MYSQL、MongoDB数据库连接与查询、爬取天猫连衣裙数据保存到MongoDB的更多相关文章
- 吴裕雄--天生自然python学习笔记:Python3 MySQL 数据库连接 - PyMySQL 驱动
什么是 PyMySQL? PyMySQL 是在 Python3.x 版本中用于连接 MySQL 服务器的一个库,Python2中则使用mysqldb. PyMySQL 遵循 Python 数据库 AP ...
- 吴裕雄--天生自然PYTHON爬虫:安装配置MongoDBy和爬取天气数据并清洗保存到MongoDB中
1.下载MongoDB 官网下载:https://www.mongodb.com/download-center#community 上面这张图选择第二个按钮 上面这张图直接Next 把bin路径添加 ...
- 吴裕雄--天生自然PYTHON爬虫:使用BeautifulSoup解析中国旅游网页数据
import requests from bs4 import BeautifulSoup url = "http://www.cntour.cn/" strhtml = requ ...
- 吴裕雄--天生自然python学习笔记:python用 Bokeh 模块绘制我国 GDP 数据统计图
现在我们把我国 1990 年到 2017 年的 GDP 数据抓取出 来,井用 Bokeh 绘 出散点统计图 . 由网页爬取所需数据,并用 Bokeh 绘制散点图 . import requests # ...
- 吴裕雄--天生自然python学习笔记:WEB数据抓取与分析
Web 数据抓取技术具有非常巨大的应用需求及价值, 用 Python 在网页上收集数据,不仅抓取数据的操作简单, 而且其数据分析功能也十分强大. 通过 Python 的时lib 组件中的 urlpar ...
- 吴裕雄--天生自然python学习笔记:python通过“任务计划程序”实现定时自动下载或更新运行 PM2.5 数据抓取程序数据
在 Windows 任务计划程序中,设置每隔 30 分钟自动抓取 PM2.5 数据,井保存 在 SQLite 数据库中 . import sqlite3,ast,requests,os from bs ...
- 吴裕雄--天生自然PYTHON爬虫:使用Selenium爬取大型电商网站数据
用python爬取动态网页时,普通的requests,urllib2无法实现.例如有些网站点击下一页时,会加载新的内容,但是网页的URL却没有改变(没有传入页码相关的参数),requests.urll ...
- 吴裕雄--天生自然python学习笔记:爬取我国 1990 年到 2017年 GDP 数据并绘图显示
绘制图形所需的数据源通常是不固定的,比如,有时我们会需要从网页抓取, 也可能需从文件或数据库中获取. 利用抓取网页数据技术,把我国 1990 年到 2016 年的 GDP 数据抓取出来 ,再利用 Ma ...
- 吴裕雄--天生自然python机器学习:决策树算法
我们经常使用决策树处理分类问题’近来的调查表明决策树也是最经常使用的数据挖掘算法. 它之所以如此流行,一个很重要的原因就是使用者基本上不用了解机器学习算法,也不用深究它 是如何工作的. K-近邻算法可 ...
随机推荐
- 【C语言】创建一个函数,利用该函数将两个字符串连接起来
代码: #include<stdio.h> ], ]) { int i, j; ; c[i] != '\0'; i++); ; d[j] != '\0'; j++) { c[i++] = ...
- Centos610-FastDFS系列篇
最近有使用到FastDFS,考虑到实际在Linux上面配置频率比较低(属于一次性配置),所以本文开始记录相关安装过程,以方便后续使用. 1.单机版安装配置 FastDFS单机模式安装配置 2.集群模式 ...
- angular2 单元测试 路由相关
第一步:在html模板中,写路由链接,并保证有路由出口 第二步:写自定义的路由指令和路由出口组件,因为在单元测试中不需要引入真实的路由,此处我们用虚拟的代替即可. 第三步:将自定义的虚拟路由指令和路由 ...
- 树莓派下编译并使用miracl密码库
参考:Linux下编译并使用miracl密码库 MIRACL用户手册:https://wenku.baidu.com/view/d542f2ed0975f46527d3e1dc.html 具体过程. ...
- postgresql数据库利用函数返回查询结果集
- js将相除结果百分比 ,四舍五入函数 toFixed()
function percentNum(num, num2) { return (Math.round(num / num2 * 10000) / 100.00 + "%"); } ...
- Spring boot security权限管理集成cas单点登录
挣扎了两周,Spring security的cas终于搞出来了,废话不多说,开篇! Spring boot集成Spring security本篇是使用spring security集成cas,因此,先 ...
- TakeColor下载及调节鼠标指针不一致的问题
取色器下载链接: 链接:https://pan.baidu.com/s/19TBWZA2ltaLQjzskTipnmg 提取码:2uz3 若出现指针与鼠标不一致: TakeColor v8.0 > ...
- HIS读书笔记
医院的主要信息子系统,包括医院信息管理系统HIMS,放射科信息系统RIS,图像存档与传输系统PACS,检验信息系统LIS,医学信息传输标准与系统集成,以及临床路径和电子病历等. 医院信息系统一般划分为 ...
- 「NOIP2018」赛道修建
传送门 Luogu 解题思路 一眼先二分(上界树的直径,下界最小边权),然后再考虑 \(\text{DP}\). 对于当前节点 \(u\),在它的所有儿子中分别返回一条匹配不完的长度最大的路径 \(M ...