python Pandas Profiling 一行代码EDA 探索性数据分析
1. 探索性数据分析
数据的筛选、重组、结构化、预处理等都属于探索性数据分析的范畴,探索性数据分析是帮助数据分析师掌握数据结构的重要工具,也是奠定后续工作的成功基石。
在数据的分析项目中,数据的收集和预处理往往占据整个项目工作量的十之八九,正式这些简单的工作决定了整个项目的成败。
Generates profile reports from a pandas DataFrame. The pandas df.describe() function is great but a little basic for serious exploratory data analysis. pandas_profiling extends the pandas DataFrame with df.profile_report() for quick data analysis.
For each column the following statistics - if relevant for the column type - are presented in an interactive HTML report:
Essentials: type, unique values, missing values
Quantile statistics like minimum value, Q1, median, Q3, maximum, range, interquartile range
Descriptive statistics like mean, mode, standard deviation, sum, median absolute deviation, coefficient of variation, kurtosis, skewness
Most frequent values
Histogram
Correlations highlighting of highly correlated variables, Spearman, Pearson and Kendall matrices
Missing values matrix, count, heatmap and dendrogram of missing values
官网:https://github.com/pandas-profiling/pandas-profiling
代码样例
一个完整的样例:
https://nbviewer.jupyter.org/github/lksfr/TowardsDataScience/blob/master/pandas-profiling.ipynb
# importing required packages
import pandas as pd
import pandas_profiling
import numpy as np
# importing the data
df = pd.read_csv('/Users/lukas/Downloads/titanic/train.csv')
profile = pandas_profiling.ProfileReport(tijian_pdf)
profile.to_file("output_tijian_chinese.html")
效果
样例链接:https://pandas-profiling.github.io/pandas-profiling/examples/meteorites/meteorites_report.html
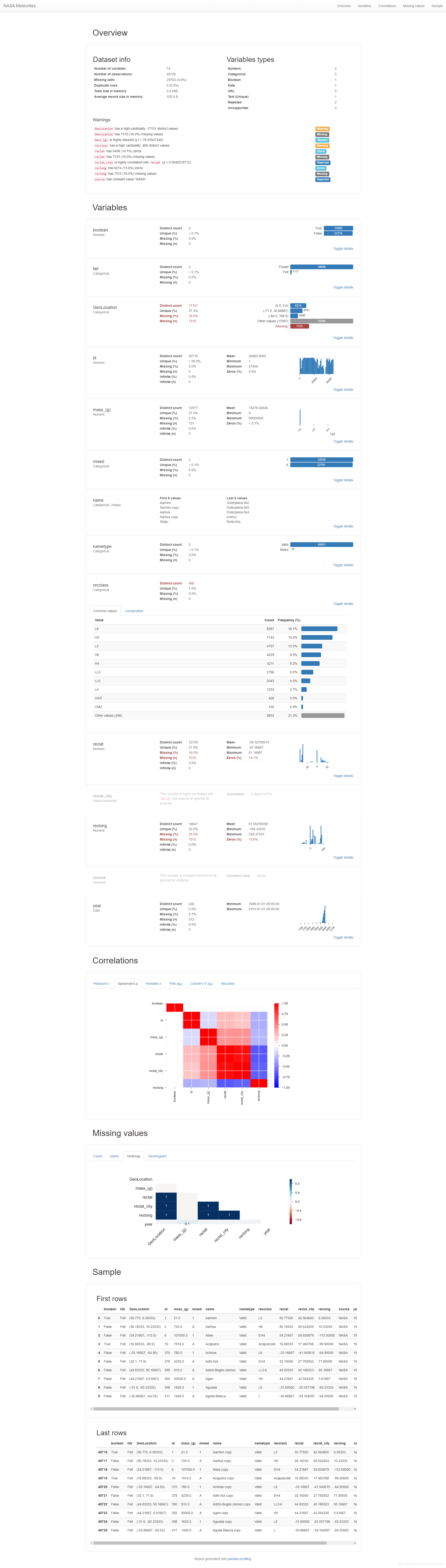
在使用过程中发现,中文显示有问题,下面这块应该是调用seaborn 完成的。我们从源码配置文件可以看到
解决pandas profile 中文显示的问题
我们找到 pandas porfile 的配置文件,在conda 的环境中:
路径为:
D:\ProgramData\Anaconda3\envs\DATABASE\Lib\site-packages\pandas_profiling\view
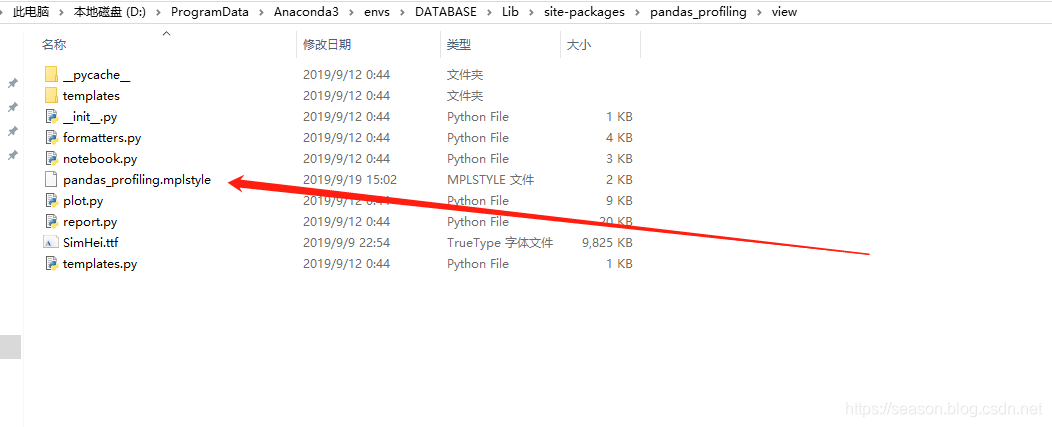
打开文件看到:
## Credits for this style go to the ggplot and seaborn packages.
## I copied the style file to remove dependencies on the Seaborn package.
## Check it out, it's an awesome library for plotting!
其实设置是参照seaborn ,但是pandas profile 的绘图设置是独立于seaborn 的。
所以在字体设置(篮筐处),加上一个汉语字体,其他的字体干掉,注意前后空格,ok。
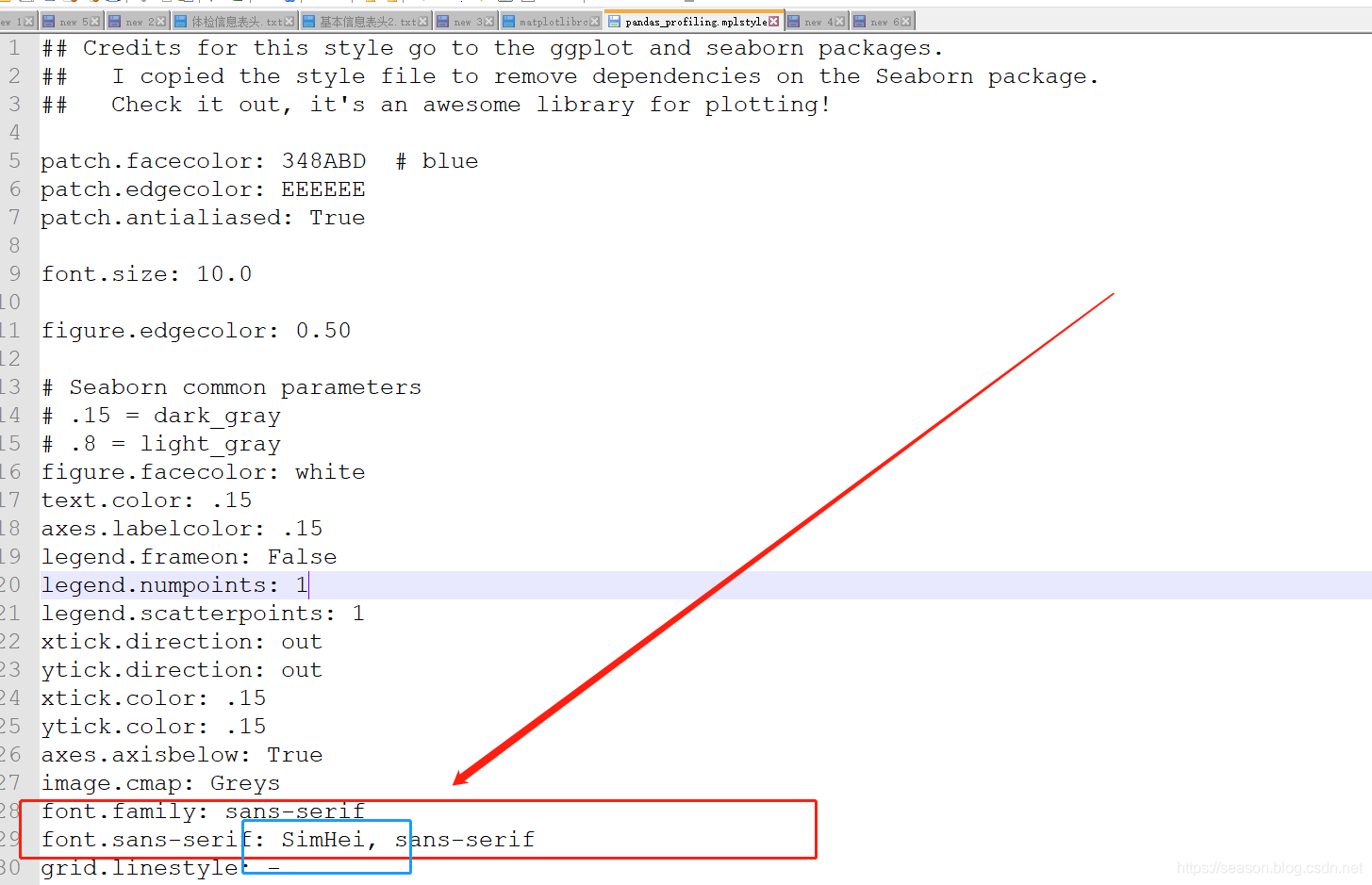
以防万一,把字体文件在这个目录再放一份
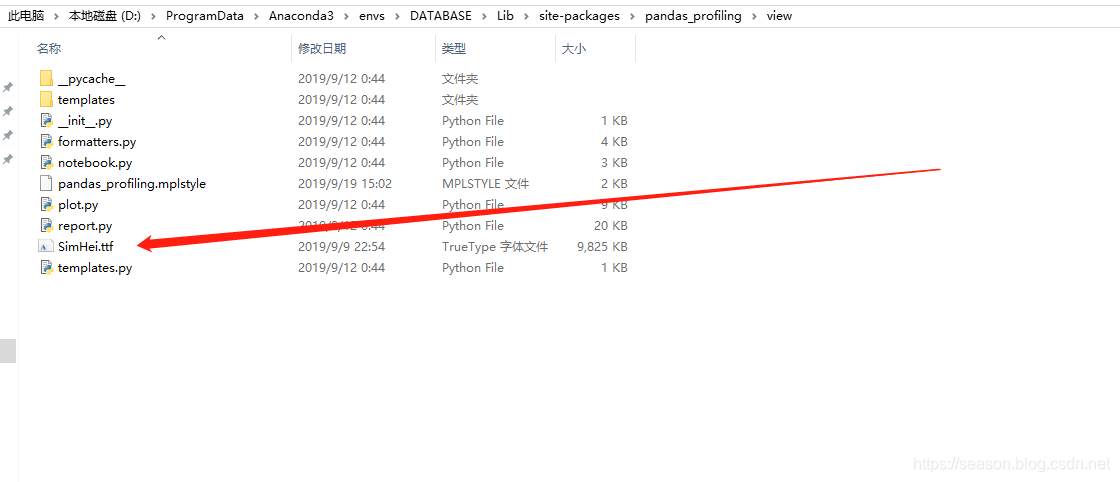
打完收工!
思路参考:
以 matplotlib 为基础的库的可视化库的中文显示问题,都可以这么设置
python Pandas Profiling 一行代码EDA 探索性数据分析的更多相关文章
- python进行EDA探索性数据分析
1.查看数据的类型概况 cols = [c for c in train.columns] #返回数据的列名到列表里 print('Number of features: {}'.format(l ...
- 简单机器学习人脸识别工具face-recognition python小试,一行代码实现人脸识别
摘要: 1行代码实现人脸识别,1. 首先你需要提供一个文件夹,里面是所有你希望系统认识的人的图片.其中每个人一张图片,图片以人的名字命名.2. 接下来,你需要准备另一个文件夹,里面是你要识别的图片.3 ...
- 在Python中,如何用一行代码去判定整数二进制中的连续 1
利用字节位操作如何判断一个整数的二进制是否含有至少两个连续的1 的方法有多种,大家第一反应应该想到的是以下的第一种方法. 方法一:从头到尾遍历一遍每一位即可找出是否有连续的1存在 这个方法是最普遍的. ...
- 探索性数据分析(Exploratory Data Analysis,EDA)
探索性数据分析(Exploratory Data Analysis,EDA)主要的工作是:对数据进行清洗,对数据进行描述(描述统计量,图表),查看数据的分布,比较数据之间的关系,培养对数据的直觉,对数 ...
- Python一行代码
1:Python一行代码画出爱心 print]+(y*-)**-(x**(y*<= ,)]),-,-)]) 2:终端路径切换到某文件夹下,键入: python -m SimpleHTTPServ ...
- Python:如何用一行代码获取上个月是几月
现在转一篇志军100发于公众号 Python之禅的文章: Python:如何用一行代码获取上个月是几月 抱歉我用了个有点标题党的标题,因为担心你错过了本文,但内容绝对干货,本文介绍的关于Python时 ...
- 只需一行代码!Python中9大时间序列预测模型
在时间序列问题上,机器学习被广泛应用于分类和预测问题.当有预测模型来预测未知变量时,在时间充当独立变量和目标因变量的情况下,时间序列预测就出现了. 预测值可以是潜在雇员的工资或银行账户持有人的信用评分 ...
- Python高级技巧:用一行代码减少一半内存占用
我想与大家分享一些我和我的团队在一个项目中经历的一些问题.在这个项目中,我们必须要存储和处理一个相当大的动态列表.测试人员在测试过程中,抱怨内存不足.下面介绍一个简单的方法,通过添加一行代码来解决这个 ...
- Python人工智能之图片识别,Python3一行代码实现图片文字识别
1.Python人工智能之图片识别,Python3一行代码实现图片文字识别 2.tesseract-ocr安装包和中文语言包 注意:
随机推荐
- ansible下载文件的多种方式
对于ansible来说,下载文件是一个很重要的课题,这是build或者deploy的第一步,通常来讲由于不同项目的差异,可能我们的代码包或者资源文件保存在于http,github,nexus,ftp, ...
- 51nod 1421:最大MOD值
1421 最大MOD值 题目来源: CodeForces 基准时间限制:1 秒 空间限制:131072 KB 分值: 80 难度:5级算法题 有一个a数组,里面有n个整数.现在要从中找到两个数字(可以 ...
- 洛谷 P2341 [HAOI2006]受欢迎的牛|【模板】强连通分量
题目传送门 解题思路: 先求强联通分量,缩点,然后统计新图中有几个点出度为0,如果大于1个,则说明这不是一个连通图,答案即为0.否则入度为0的那个强连通分量的点数即为答案 AC代码: #include ...
- javascript的自定义对象/取消事件/事件兼容性/取消冒泡
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- Cavace 自定义View绘制
一.开发资料与实例教程1.跟囧猫学之Canvas.Matrix 倒影实例教程 http://www.eoeandroid.com/thread-158506-1-1.html 2.Gridview 控 ...
- 用PyQt5来即时显示pandas Dataframe的数据,附qdarkstyle黑夜主题样式(美美哒的黑夜主题)
import sys from qdarkstyle import load_stylesheet_pyqt5 from PyQt5.QtWidgets import QApplication, QT ...
- Spring Cloud Alibaba 教程 | 前世今生
Spring Cloud Alibaba是什么 先来看一下官方是怎么定义Spring Cloud Alibaba的: Spring Cloud Alibaba 致力于提供微服务开发的一站式解决方案.此 ...
- [CISCN2019 华北赛区 Day2 Web1]Hack World
知识点:题目已经告知列名和表明为flag,接下来利用ascii和substr函数即可进行bool盲注 eg: id=(ascii(substr((select(flag)from(flag)),1,1 ...
- c语言的各种技巧
一.参考网址 1.参考网址1:C 语言的奇技淫巧 二.
- Struts 2 的常规配置
Struts 2 的默认配置文件是struts.xml,该文件应该放在Web应用的类加载路径下,通常就是放在WEB-INF/classes路径下. struts.xml文件的最大作用是配置Action ...