Caffe学习--Layer分析
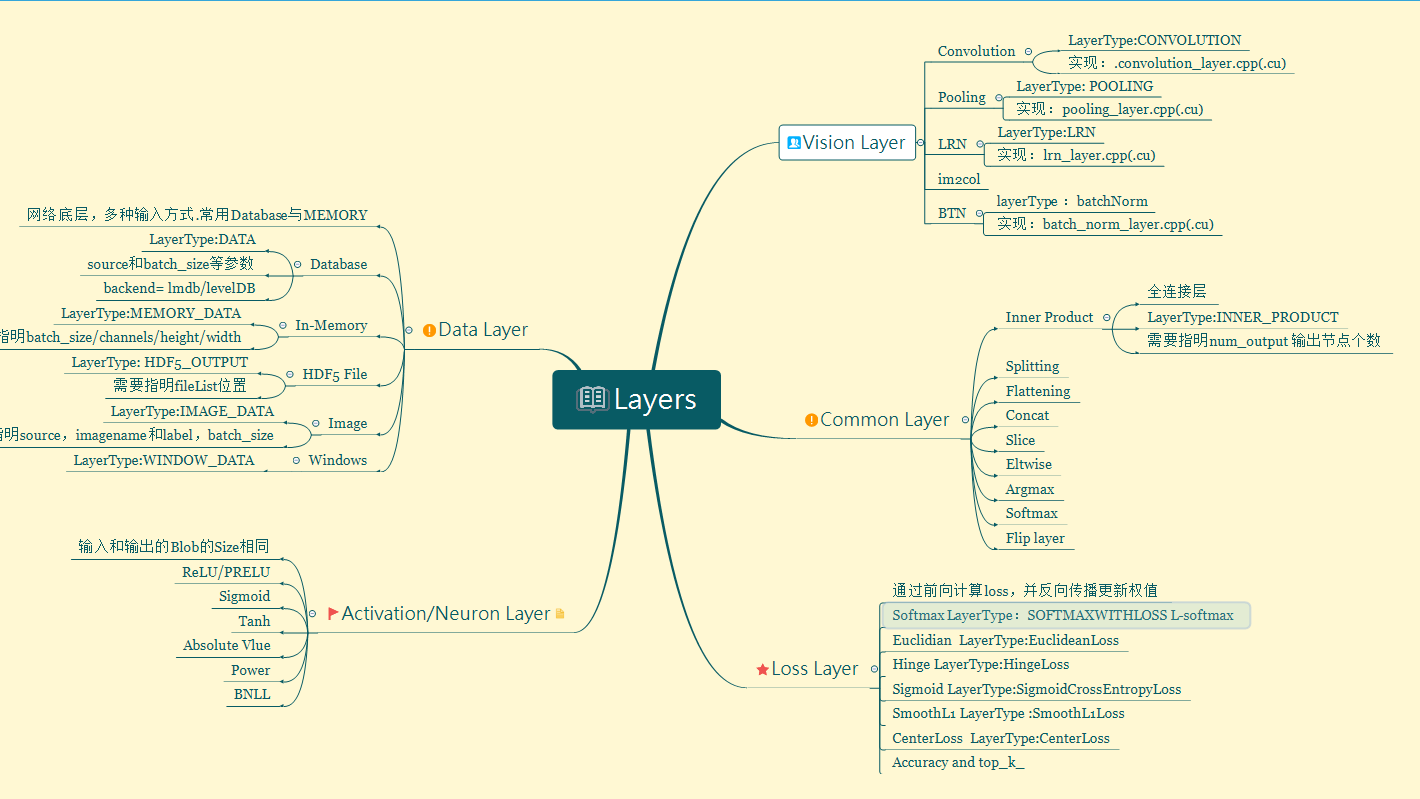
Caffe_Layer
1.基本数据结构
//Layer层主要的的参数
LayerParamter layer_param_; // protobuf内的layer参数
vector<shared_ptr<Blob<Dtype>*>>blobs_;//存储layer的参数,
vector<bool>param_propagate_down_;//表示是否计算各个blobs反向误差。
2.主要函数接口
virtual void SetUp(const vector<Blob<Dtype>*>&bottom,
vector<Blob<Dtype>*>& top);
Dtype Forward(const vector<Blob<Dtype>*>&bottom,
vector<Blob<Dtype>*>&top);
void Backward(const vector<Blob<Dtype>*>&top,
const vector<bool>param_propagate_down,vector<Blob<Dtype>*>& bottom);
3.具体的Layer分析
具体的常用Layer分析
(1) DataLayer
数据通过数据层进入Layer,可以来自于数据库(LevelDB或者LMDB),也可以来自内存,HDF5等
//Database:类型 Database
//必须参数 source,batch_size
//可选参数:rand_skip,mirror,backend[default LEVELDB]
// In-Memory:类型 MemoryData
// 必选参数:batch_size,channels,height,width
//HDF5 Input:类型 HDF5Data
//必选参数: source,batch_size
//Images : 类型 ImageData
//必要参数:source(文件名label),batch_size
//可选参数:rand_skip,shuffle,new_width,new_height;
(2) 激励层(neuron_layers)
一般来说,激励层是element-wise,输入输出大小相同,一般非线性函数
输入:n*c*h*w
输出:n*c*h*w
//ReLU/PReLU
//可选参数 negative_slope 指定输入值小于零时的输出。
// f(x) = x*(x>0)+negative_slope*(x<=0)
//ReLU目前使用最为广泛,收敛快,解决梯度弥散问题
layer{
name:"relu"
type:"ReLU"
bottom:"conv1"
top:"conv1"
}
//Sigmoid
//f(x) = 1./(1+exp(-x)); 负无穷--正无穷映射到-1---1
layer{
name:"sigmoid-test"
bottom:"conv1"
top:"conv1"
type:"Sigmoid"
}
(3) 视觉层(vision-layer)
常用layer操作
//卷积层(Convolution):类型Convolution
//包含学习率,输出卷积核,卷积核size,初始方式,权值衰减
//假使输入n*ci*hi*wi,则输出
// new_h = ((hi-kernel_h)+2*pad_h)/stride+1;
// new_w = ((wi-kernel_w)+2*pad_w)/stride+1;
//输出n*num_output*new_h*new_w;
layer{
name: "conv1"
type: "CONVOLUTION"
bottom: "data"
top: "conv1"
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
convolution_param {
num_output: 96
kernel_size: 11
stride: 4
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
//池化层(Pooling) 类型 Pooling
// (hi-kernel_h)/2+1;
layer{
name:"pool1"
type:"POOLING"
bottom:"conv1"
top:"conv1"
pooling_param{
pool:MAX //AVE,STOCHASTIC
kernel_size:3
stride:2
}
}
//BatchNormalization
// x' = (x-u)/δ ;y = α*x'+β;
(4) 损失层
最小化输出于目标的LOSS来驱动学习更新
//Softmax
4.说明
SetUp函数需要根据实际的参数设置进行实现,对各种类型的参数初始化;Forward和Backward对应前向计算和反向更新,输入统一都是bottom,输出为top,其中Backward里面有个propagate_down参数,用来表示该Layer是否反向传播参数。
在Forward和Backward的具体实现里,会根据Caffe::mode()进行对应的操作,即使用cpu或者gpu进行计算,两个都实现了对应的接口Forward_cpu、Forward_gpu和Backward_cpu、Backward_gpu,这些接口都是virtual,具体还是要根据layer的类型进行对应的计算(注意:有些layer并没有GPU计算的实现,所以封装时加入了CPU的计算作为后备)。另外,还实现了ToProto的接口,将Layer的参数写入到protocol buffer文件中。
Caffe学习--Layer分析的更多相关文章
- Caffe学习--Blob分析
Caffe_blob 1.基本数据结构 Blob为模板类,可以理解为四维数组,n * c * h * w的结构,Layer内为blob输入data和diff,Layer间的blob为学习的参数.内部封 ...
- Caffe学习--Net分析
Caffe_Net 1.基本数据 vector<shared_ptr<Layer<Dtype> > > layers_; // 记录每一层的layer参数 vect ...
- caffe 学习(3)——Layer Catalogue
layer是建模和计算的基本单元. caffe的目录包含各种state-of-the-art model的layers. 为了创建一个caffe model,我们需要定义模型架构在一个protocol ...
- Caffe学习笔记(三):Caffe数据是如何输入和输出的?
Caffe学习笔记(三):Caffe数据是如何输入和输出的? Caffe中的数据流以Blobs进行传输,在<Caffe学习笔记(一):Caffe架构及其模型解析>中已经对Blobs进行了简 ...
- Caffe学习笔记(一):Caffe架构及其模型解析
Caffe学习笔记(一):Caffe架构及其模型解析 写在前面:关于caffe平台如何快速搭建以及如何在caffe上进行训练与预测,请参见前面的文章<caffe平台快速搭建:caffe+wind ...
- Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- Caffe学习系列(23):如何将别人训练好的model用到自己的数据上
caffe团队用imagenet图片进行训练,迭代30多万次,训练出来一个model.这个model将图片分为1000类,应该是目前为止最好的图片分类model了. 假设我现在有一些自己的图片想进行分 ...
- Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
- 转 Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
随机推荐
- 函数与装饰器Python学习(三)
1.1 文件处理 1.1.1 打开文件过程 在Python中,打开文件,得到文件句柄并赋值给一个变量,默认打开模式就为r f=open(r'a.txt','w',encoding='utf-8') p ...
- 如何将App从一个账号迁移到另一个账号?
App迁移(App transfer):将App从一个开发者账号迁移至另一个开发者账号.此文演示了整个迁移过程,为了方便解释,在此过程中,将App转出的开发者账号我们下文将会称之为A账号,接收杭州Ap ...
- router+x
vue-router官方的路由管理器 包含的功能: ——绑定方法进行跳转 路由嵌套 写的不一样搜索的路由路径也不一样 二级路由 设置默认路由 导航守卫: 用于强制跳转或者取消的方式 ...
- Hive 基本操作
1.创建一个表 (字段表名不加引号‘,分隔符需要加引号) create table t1( id int ,name string ,hobby array<string> ,add ma ...
- Pyhton学习——Day6
# def test(x) : #形参:不占内存空间,调用函数时传入值,程序完成形参释放内存# # 注释内容# # 代码内容# y = x*2# print(y)# # return# # test( ...
- 【转】Retina 屏幕下,网页图片的显示兼容
感谢 Apple,带来了 Retina 屏幕的革命,让我们可以在电子显示屏上享受到印刷级的分辨率.由于分辨率的提升,网页中的文字.Flash 和 SVG 内容显示得比原来更加精细,但网页中的图片却变得 ...
- javaScript(其他引用类型对象)
javascript其他引用类型对象 Global对象(全局)这个对象不存在,无形的对象,无法new一个 其内部定义了一些方法和属性:如下 encodeURI str = www.baidu.com ...
- HDU1061 - Rightmost Digit
Given a positive integer N, you should output the most right digit of N^N. Input The input contains ...
- BZOJ 2342 [SHOI2011]双倍回文 (回文自动机)
题目大意:略 先建出$PAM$ 因为双倍回文串一定是4的倍数,所以找出$PAM$里所有$dep$能整除4的节点 看这个串是否存在一个回文后缀,长度恰好为它的一半,沿着$pre$链往上跳就行了 暴跳可能 ...
- 自动合法打印VitalSource Bookshelf中的电子书
最近有一本2千多页的在VitalSource中的电子书想转为PDF随时阅读,没料网上找了一圈没有找到合适的.相对好一些的只有一个用Python写的模拟手动打印.于是想到了用AutoHotkey写一个自 ...