Hadoop MapReduce编程 API入门系列之挖掘气象数据版本3(九)
不多说,直接上干货!
下面,是版本1。
Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一)
下面是版本2。
Hadoop MapReduce编程 API入门系列之挖掘气象数据版本2(九)
这篇博客,给大家,体会不一样的版本编程。


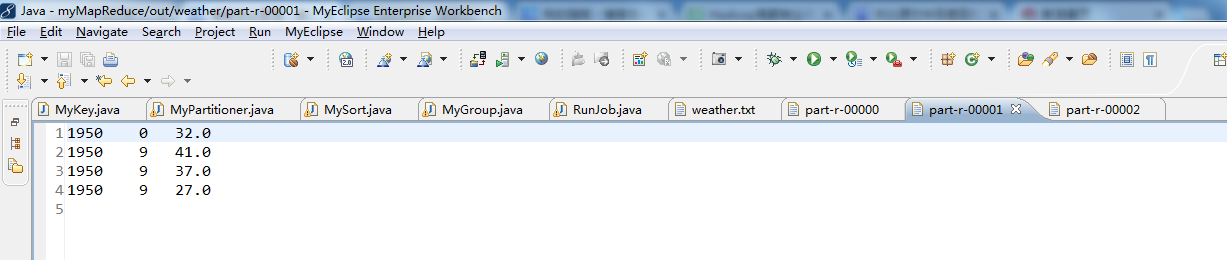
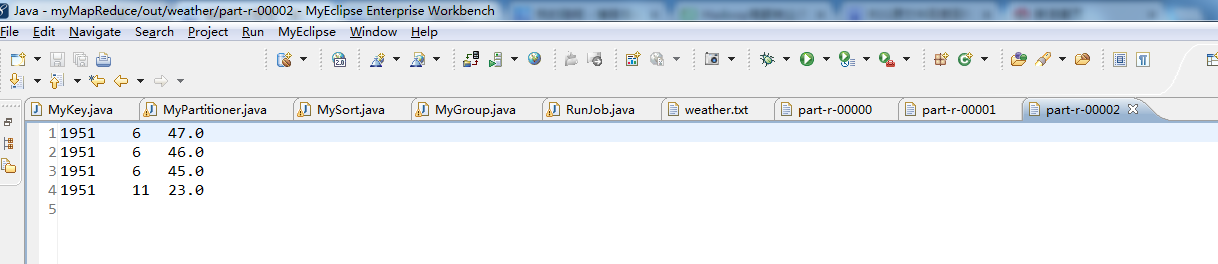
代码
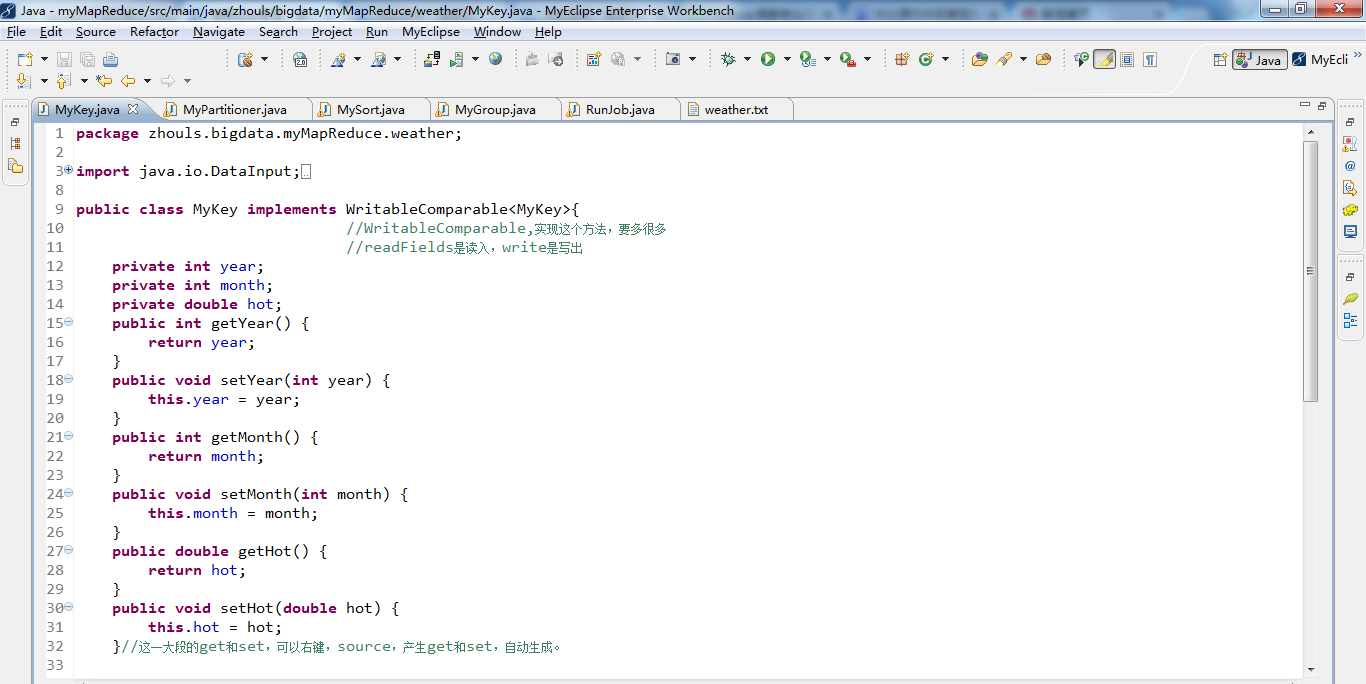
package zhouls.bigdata.myMapReduce.weather; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; import org.apache.hadoop.io.WritableComparable; public class MyKey implements WritableComparable<MyKey>{
//WritableComparable,实现这个方法,要多很多
//readFields是读入,write是写出
private int year;
private int month;
private double hot;
public int getYear() {
return year;
} public void setYear(int year) {
this.year = year;
} public int getMonth() {
return month;
} public void setMonth(int month) {
this.month = month;
} public double getHot() {
return hot;
} public void setHot(double hot) {
this.hot = hot;
}//这一大段的get和set,可以右键,source,产生get和set,自动生成。 public void readFields(DataInput arg0) throws IOException { //反序列化
this.year=arg0.readInt();
this.month=arg0.readInt();
this.hot=arg0.readDouble();
} public void write(DataOutput arg0) throws IOException { //序列化
arg0.writeInt(year);
arg0.writeInt(month);
arg0.writeDouble(hot);
} //判断对象是否是同一个对象,当该对象作为输出的key
public int compareTo(MyKey o) {
int r1 =Integer.compare(this.year, o.getYear());//比较当前的年和你传过来的年
if(r1==){
int r2 =Integer.compare(this.month, o.getMonth());
if(r2==){
return Double.compare(this.hot, o.getHot());
}else{
return r2;
}
}else{
return r1;
}
} }
package zhouls.bigdata.myMapReduce.weather; import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner; public class MyPartitioner extends HashPartitioner<MyKey, DoubleWritable>{//这里就是洗牌 //执行时间越短越好
public int getPartition(MyKey key, DoubleWritable value, int numReduceTasks) {
return (key.getYear()-)%numReduceTasks;//对于一个数据集,找到最小,1949
}
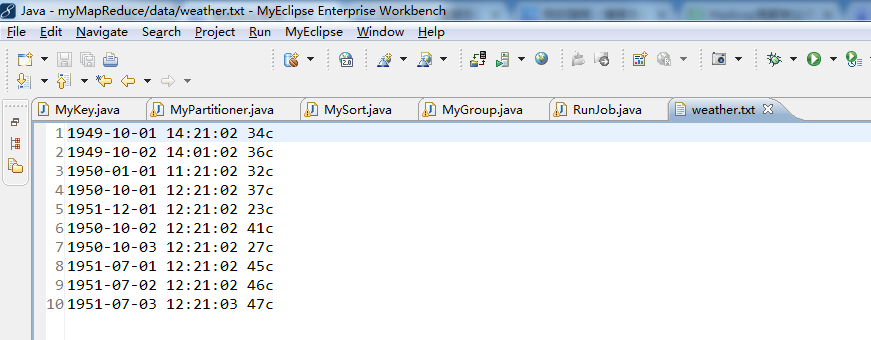
} //1949-10-01 14:21:02 34c
//1949-10-02 14:01:02 36c
//1950-01-01 11:21:02 32c
//1950-10-01 12:21:02 37c
//1951-12-01 12:21:02 23c
//1950-10-02 12:21:02 41c
//1950-10-03 12:21:02 27c
//1951-07-01 12:21:02 45c
//1951-07-02 12:21:02 46c
//1951-07-03 12:21:03 47c
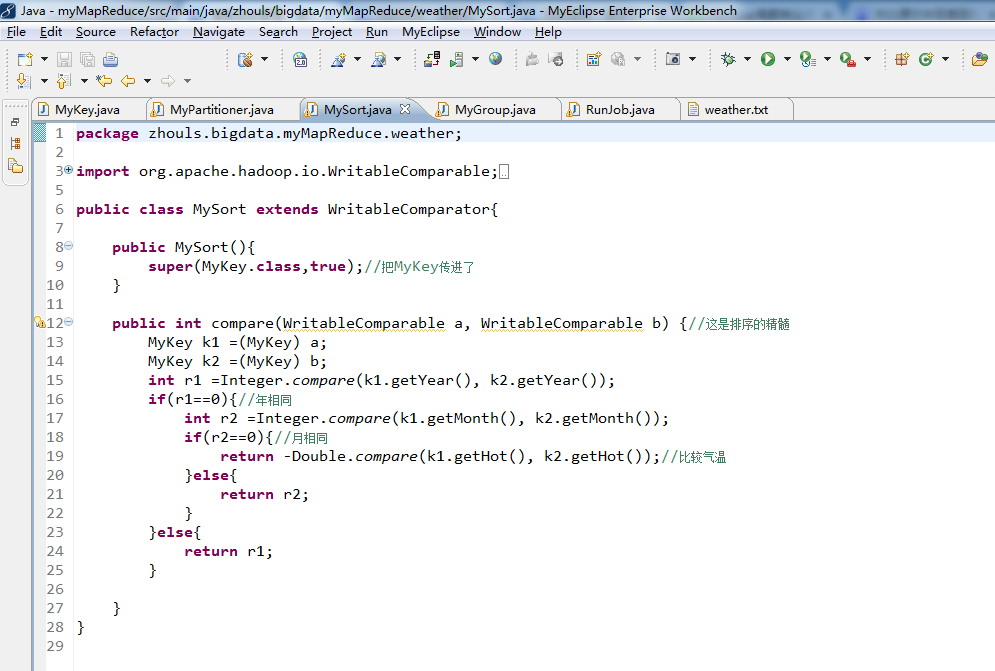
package zhouls.bigdata.myMapReduce.weather; import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator; public class MySort extends WritableComparator{ public MySort(){
super(MyKey.class,true);//把MyKey传进了
} public int compare(WritableComparable a, WritableComparable b) {//这是排序的精髓
MyKey k1 =(MyKey) a;
MyKey k2 =(MyKey) b;
int r1 =Integer.compare(k1.getYear(), k2.getYear());
if(r1==){//年相同
int r2 =Integer.compare(k1.getMonth(), k2.getMonth());
if(r2==){//月相同
return -Double.compare(k1.getHot(), k2.getHot());//比较气温
}else{
return r2;
}
}else{
return r1;
} }
}
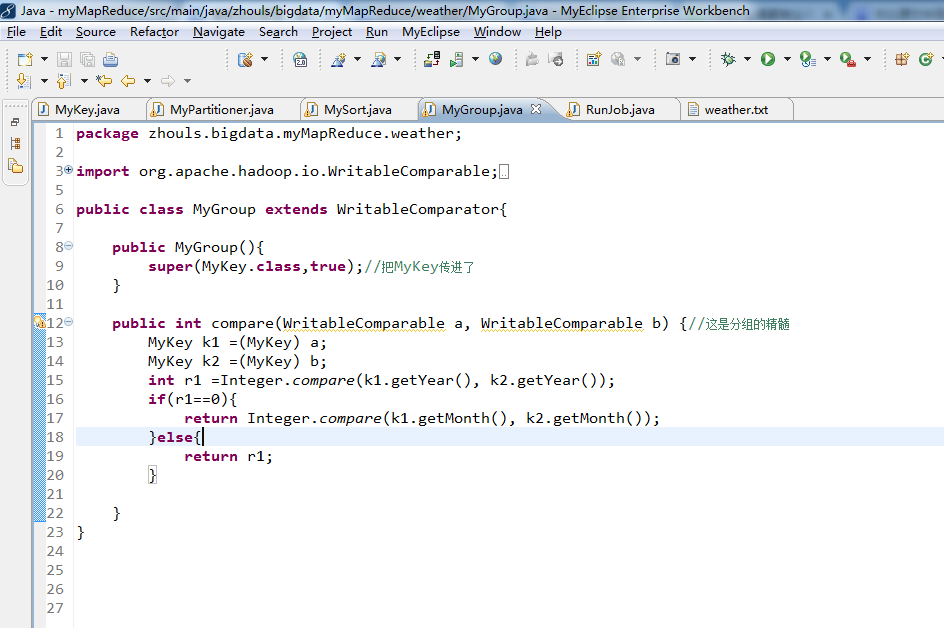
package zhouls.bigdata.myMapReduce.weather; import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator; public class MyGroup extends WritableComparator{ public MyGroup(){
super(MyKey.class,true);//把MyKey传进了
} public int compare(WritableComparable a, WritableComparable b) {//这是分组的精髓
MyKey k1 =(MyKey) a;
MyKey k2 =(MyKey) b;
int r1 =Integer.compare(k1.getYear(), k2.getYear());
if(r1==){
return Integer.compare(k1.getMonth(), k2.getMonth());
}else{
return r1;
} }
}
package zhouls.bigdata.myMapReduce.weather; import java.io.IOException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Calendar;
import java.util.Date; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
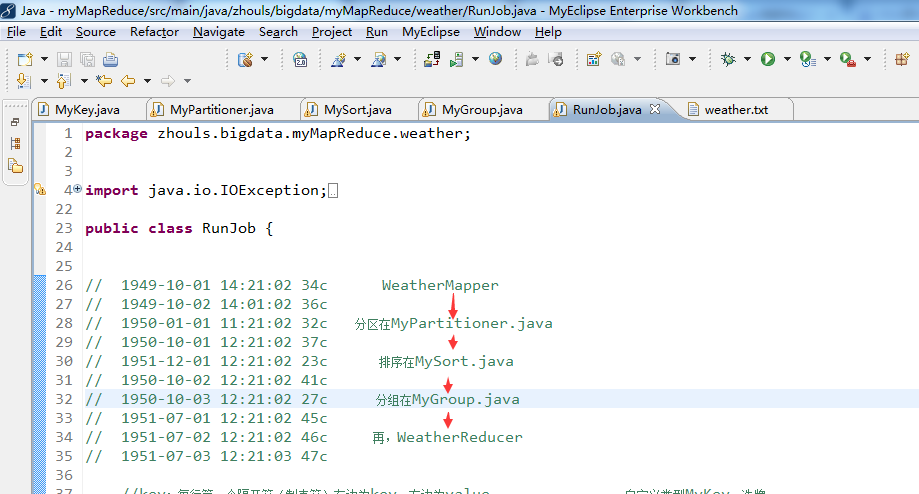
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class RunJob { // 1949-10-01 14:21:02 34c WeatherMapper
// 1949-10-02 14:01:02 36c
// 1950-01-01 11:21:02 32c 分区在MyPartitioner.java
// 1950-10-01 12:21:02 37c
// 1951-12-01 12:21:02 23c 排序在MySort.java
// 1950-10-02 12:21:02 41c
// 1950-10-03 12:21:02 27c 分组在MyGroup.java
// 1951-07-01 12:21:02 45c
// 1951-07-02 12:21:02 46c 再,WeatherReducer
// 1951-07-03 12:21:03 47c //key:每行第一个隔开符(制表符)左边为key,右边为value 自定义类型MyKey,洗牌,
static class WeatherMapper extends Mapper<Text, Text, MyKey, DoubleWritable>{
SimpleDateFormat sdf =new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
NullWritable v =NullWritable.get();
// 1949-10-01 14:21:02是自定义类型MyKey,即key
// 34c是DoubleWritable,即value protected void map(Text key, Text value,Context context) throws IOException, InterruptedException {
try {
Date date =sdf.parse(key.toString());
Calendar c =Calendar.getInstance();
//Calendar 类是一个抽象类,可以通过调用 getInstance() 静态方法获取一个 Calendar 对象,
//此对象已由当前日期时间初始化,即默认代表当前时间,如 Calendar c = Calendar.getInstance();
c.setTime(date);
int year =c.get(Calendar.YEAR);
int month =c.get(Calendar.MONTH); double hot =Double.parseDouble(value.toString().substring(, value.toString().lastIndexOf("c")));
MyKey k =new MyKey();
k.setYear(year);
k.setMonth(month);
k.setHot(hot);
context.write(k, new DoubleWritable(hot));
} catch (Exception e) {
e.printStackTrace();
}
}
} static class WeatherReducer extends Reducer<MyKey, DoubleWritable, Text, NullWritable>{
protected void reduce(MyKey arg0, Iterable<DoubleWritable> arg1,Context arg2)throws IOException, InterruptedException {
int i=;
for(DoubleWritable v :arg1){
i++;
String msg =arg0.getYear()+"\t"+arg0.getMonth()+"\t"+v.get();//"\t"是制表符
arg2.write(new Text(msg), NullWritable.get());
if(i==){
break;
}
}
}
} public static void main(String[] args) {
Configuration config =new Configuration();
// config.set("fs.defaultFS", "hdfs://HadoopMaster:9000");
// config.set("yarn.resourcemanager.hostname", "HadoopMaster");
// config.set("mapred.jar", "C:\\Users\\Administrator\\Desktop\\wc.jar");
// config.set("mapreduce.input.keyvaluelinerecordreader.key.value.separator", ",");//默认分隔符是制表符"\t",这里自定义,如","
try {
FileSystem fs =FileSystem.get(config); Job job =Job.getInstance(config);
job.setJarByClass(RunJob.class); job.setJobName("weather"); job.setMapperClass(WeatherMapper.class);
job.setReducerClass(WeatherReducer.class);
job.setMapOutputKeyClass(MyKey.class);
job.setMapOutputValueClass(DoubleWritable.class); job.setPartitionerClass(MyPartitioner.class);
job.setSortComparatorClass(MySort.class);
job.setGroupingComparatorClass(MyGroup.class); job.setNumReduceTasks(); job.setInputFormatClass(KeyValueTextInputFormat.class); // FileInputFormat.addInputPath(job, new Path("hdfs://HadoopMaster:9000/weather.txt"));//输入路径,下有weather.txt
//
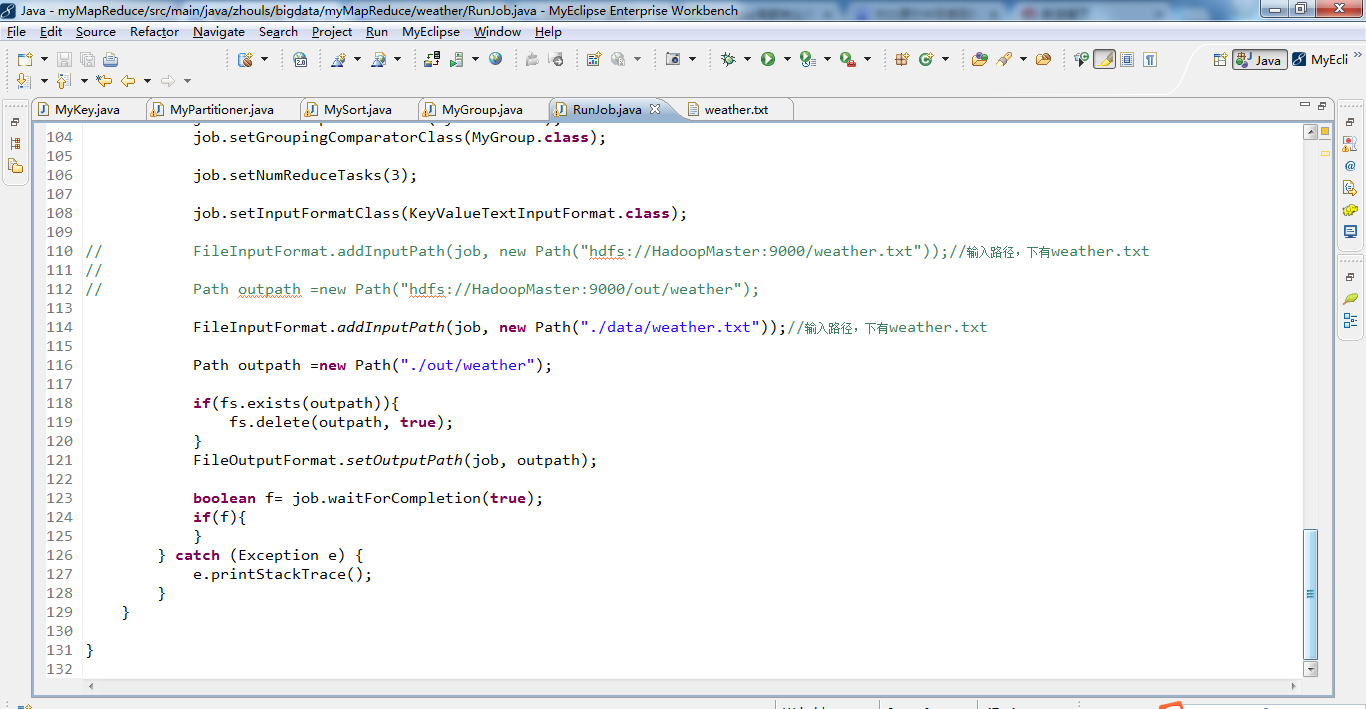
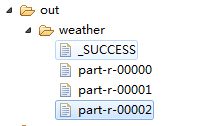
// Path outpath =new Path("hdfs://HadoopMaster:9000/out/weather"); FileInputFormat.addInputPath(job, new Path("./data/weather.txt"));//输入路径,下有weather.txt Path outpath =new Path("./out/weather"); if(fs.exists(outpath)){
fs.delete(outpath, true);
}
FileOutputFormat.setOutputPath(job, outpath); boolean f= job.waitForCompletion(true);
if(f){
}
} catch (Exception e) {
e.printStackTrace();
}
} }
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/
以及对应本平台的QQ群:161156071(大数据躺过的坑)

Hadoop MapReduce编程 API入门系列之挖掘气象数据版本3(九)的更多相关文章
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本2(十)
下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 这篇博文,包括了,实际生产开发非常重要的,单元测试和调试代码.这里不多赘述,直接送上代码. MRUni ...
- Hadoop MapReduce编程 API入门系列之统计学生成绩版本2(十八)
不多说,直接上代码. 统计出每个年龄段的 男.女 学生的最高分 这里,为了空格符的差错,直接,我们有时候,像如下这样的来排数据. 代码 package zhouls.bigdata.myMapRedu ...
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
- Hadoop MapReduce编程 API入门系列之join(二十六)(未完)
不多说,直接上代码. 天气记录数据库 Station ID Timestamp Temperature 气象站数据库 Station ID Station Name 气象站和天气记录合并之后的示意图如 ...
- Hadoop MapReduce编程 API入门系列之MapReduce多种输入格式(十七)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.ScoreCount; import java.io.DataInput; import java.i ...
- Hadoop MapReduce编程 API入门系列之自定义多种输入格式数据类型和排序多种输出格式(十一)
推荐 MapReduce分析明星微博数据 http://git.oschina.net/ljc520313/codeexample/tree/master/bigdata/hadoop/mapredu ...
- Hadoop MapReduce编程 API入门系列之wordcount版本1(五)
这个很简单哈,编程的版本很多种. 代码版本1 package zhouls.bigdata.myMapReduce.wordcount5; import java.io.IOException; im ...
- Hadoop MapReduce编程 API入门系列之薪水统计(三十一)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.SalaryCount; import java.io.IOException; import jav ...
- Hadoop MapReduce编程 API入门系列之Crime数据分析(二十五)(未完)
不多说,直接上代码. 一共12列,我们只需提取有用的列:第二列(犯罪类型).第四列(一周的哪一天).第五列(具体时间)和第七列(犯罪场所). 思路分析 基于项目的需求,我们通过以下几步完成: 1.首先 ...
随机推荐
- JavaOO小结二,及MySQL小结
流按照传输内容分有几种?各自的父类是什么? 流按照传输内容有 字节流.字符流.对象流.但其本质都是字节流.字符流和对象流是在字节流基础上作了一层封装,以便更好对字符和对象进行操作. 字节流的父类:In ...
- CXF-JAX-RS开发(二)spring整合CXF-JAX-RS
一.创建maven工程[Packaging:war] 1.目录结构 2.坐标书写 二.导入依赖和tomcat服务器插件 <dependencies> <!-- CXF --> ...
- [Intermediate Algorithm] - Arguments Optional
题目 创建一个计算两个参数之和的 function.如果只有一个参数,则返回一个 function,该 function 请求一个参数然后返回求和的结果. 例如,add(2, 3) 应该返回 5,而 ...
- OAuth密码模式说明(resource owner password credentials)
用户向客户端(third party application)提供用户名和密码. 客户端将用户名和密码发给认证服务器(Authorization server),向后者请求令牌(token). 认证服 ...
- 范畴论-一个单子(Monad)说白了不过就是自函子范畴上的一个幺半群而已
范畴即为结构:包含要素和转化. 范畴为高阶类型. 函子为高阶函数.函子的输入为态射.函子为建立在态射基础上的高阶函数.函子用于保持范畴间映射的结构.态射用于范畴内部的转换. 群为运算规则的约束. 自函 ...
- h5调用app中写好的的方法
做h5页面的时候,总会遇到些不能解决的问题于是就要与app做一些交互, app那边编辑好的方法后我们怎么用js语法去调用app编写好的方法 if(this.$winInfo.shebei == 1){ ...
- nginx设置跳转https
在监听80端口的内部,添加一句代码:rewrite ^(.*)$ https://$host$1 permanent;
- HTML 5语义化标签
HTML 5的革新之一:语义化标签一节元素标签. 在HTML 5出来之前,我们用div来表示页面章节,但是这些div都没有实际意义.(即使我们用css样式的id和class形容这块内容的意义).这些标 ...
- Tomcat Eclipse Debug出现异常
1.可能是java类没有及时更新成class文件2.本地程序没有同步到Tommcat服务器里面3.Servlet类里面加了版本号private static final long serialVers ...
- day34-2 类和对象(重点)
目录 类 定义类和对象 __dict__ 和__class__ 创建对象时的底层运作 定义对象独有的特征 init __slots__(了解) 给对象添加属性时的底层运作 类 分类/类别 上述的代码( ...