13、Next Item Recommendation with Self-Attention---自注意力+CML
一、摘要:
自注意力机制------从用户历史交互中推断出项目-项目关系。学习每个项目的相对权重【用来学习用户的暂时兴趣表示】
二、 模型:
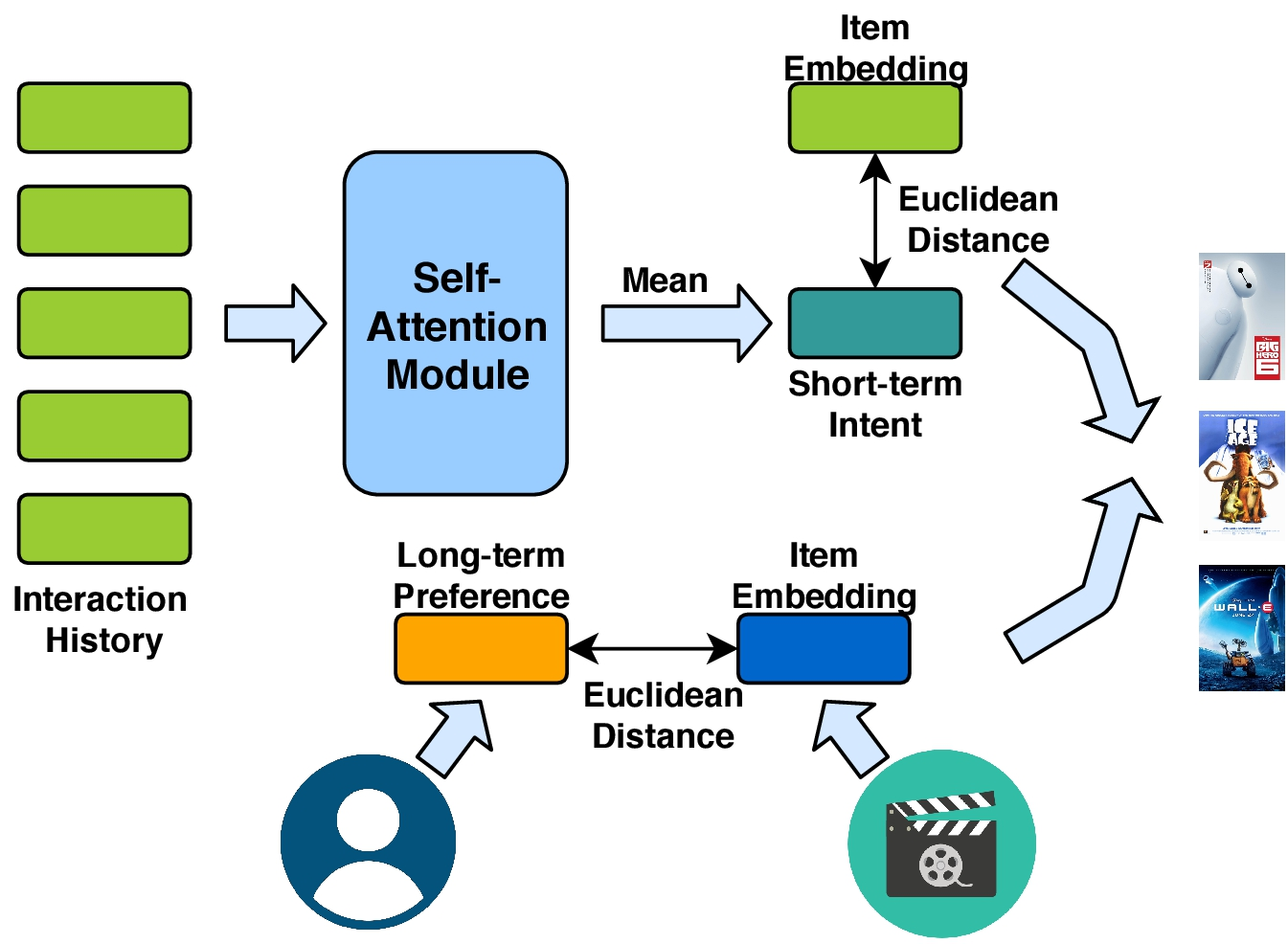
一部分是用于建模用户短期意图的自注意力机制,一部分是建模用户长期偏好的协作度量学习。
1、自注意力
自注意力可以保存上下文序列信息,并捕获序列中元素的关系。因此用自注意力来关注用户过去的行为。

输入:
query、key、value三值相等,并且都是又用户最近的历史记录L组成。其中每一项都可以由d维的嵌入向量表示。X ∈ RN×d表明全体item的嵌入表示。最新的L项(比如从t-L+1到t)按顺序放在在如下矩阵中:

输入嵌入的时间信号:以上的输入没有包括时间信号,没有序列信号。输入低级的词袋不能归保留序列模式。我们提议通过位置嵌入提供带有时间信息的query和key。我们使用一个时间尺度的几何序列来向输入端添加不同频率的正弦波。时间嵌入(TE)由以下两个正弦信号组成:
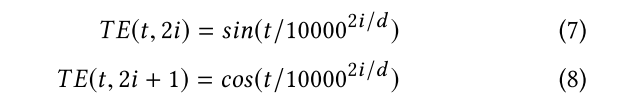
其中t是时间步长,i是维度。在非线性变换之前,TE加到query和key里。
模型:
将query和key通过共享参数的非线性变化整合到一个空间中。
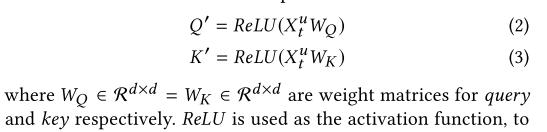
关联矩阵的计算如下:
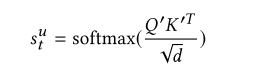
输出:
权重:
输出是L*L的关联矩阵(或注意力map),表明L项之间的相似度。
(归一化)注意根号d被用于收缩点积注意。在我们这个例子中,d通过设得比较大(比如100)。这样的话,缩放因子可以减小非常小的梯度效应。在softmax之前应用屏蔽操作(屏蔽关联矩阵的对角线),以避免相同的query向量和key之间的高匹配分数。(不是很理解)
关联矩阵和value相乘构成最后的自注意力机制的权重输出:(aut就表示用户短期意图的表示。)
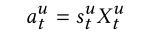
为了学习单个注意力表示,我们L自注意表示的均值嵌入作为用户瞬时意图。注意,其他的方式也可以(比如累加啊、求最大啊、最小啊),后面的实验将会比较效果。

2、用户长期喜好建模
在对短期效果进行建模之后,将用户的一般品味或长期偏好结合起来是有益的。和潜在因素方法相同,我们为每个用户和每个item分配一个潜在因素。让U属于RMd(Md为上标),V属于RNd(Nd为上标)表明users和item的潜在因素。然而,最新你的研究表明,点积操作违背了度量函数参数不等下的性质,并且将会导致次优解。为了避免这个问题,我们采用欧式距离去测量item i和user u的距离。
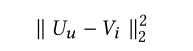
三、模型训练
目标函数:给定时间步t的短期意图,和长期偏好。我们的目标是预测用户u在时间t+1下的item(我们用Hu t+1表示,u为上标,t+1为下标)为了保证一致性,我们使用欧式距离,去建模短期和长期的影响。使用其和作为最后的推荐分数。
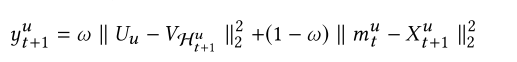
第一项是长期推荐的分数,第二项是短期推荐的分数。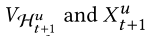 都是下一项item的嵌入向量,但是V和U是不一样的参数。最后的分数是由w控制的加权和。
都是下一项item的嵌入向量,但是V和U是不一样的参数。最后的分数是由w控制的加权和。
采用自适应梯度算法自动调整步长。
13、Next Item Recommendation with Self-Attention---自注意力+CML的更多相关文章
- 13 Zabbix Item类型之Zabbix ODBC类型
点击返回:自学Zabbix之路 13 Zabbix Item类型之Zabbix ODBC类型 ODBC是C语言开发的.用于访问数据库的中间件接口 . zabbix支持查询任何ODBC支持的数据库.za ...
- 【RS】RankMBPR:Rank-Aware Mutual Bayesian Personalized Ranking for Item Recommendation - RankMBPR:基于排序感知的相互贝叶斯个性化排序的项目推荐
[论文标题]RankMBPR:Rank-Aware Mutual Bayesian Personalized Ranking for Item Recommendation ( WAIM 2016: ...
- 第五课第四周笔记3:Multi-Head Attention多头注意力
Multi-Head Attention多头注意力 让我们进入并了解多头注意力机制. 符号变得有点复杂,但要记住的事情基本上只是你在上一个视频中学到的自我注意机制的四个大循环. 让我们看一下每次计算自 ...
- 13 Reasons Why You Should Pay Attention to Mobile Web Performance
Mobile is no longer on the sidelines. If you’re not already thinking mobile first, you should at lea ...
- 深度学习方法(九):自然语言处理中的Attention Model注意力模型
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.NET/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入. 上一篇博文深度学习方法(八):Enc ...
- 【NLP】Attention Model(注意力模型)学习总结
最近一直在研究深度语义匹配算法,搭建了个模型,跑起来效果并不是很理想,在分析原因的过程中,发现注意力模型在解决这个问题上还是很有帮助的,所以花了两天研究了一下. 此文大部分参考深度学习中的注意力机制( ...
- [深度概念]·Attention Model(注意力模型)学习笔记
此文源自一个博客,笔者用黑体做了注释与解读,方便自己和大家深入理解Attention model,写的不对地方欢迎批评指正.. 1.Attention Model 概述 深度学习里的Attention ...
- DL4NLP —— seq2seq+attention机制的应用:文档自动摘要(Automatic Text Summarization)
两周以前读了些文档自动摘要的论文,并针对其中两篇( [2] 和 [3] )做了presentation.下面把相关内容简单整理一下. 文本自动摘要(Automatic Text Summarizati ...
- seq2seq和attention应用到文档自动摘要
一.摘要种类 抽取式摘要 直接从原文中抽取一些句子组成摘要.本质上就是个排序问题,给每个句子打分,将高分句子摘出来,再做一些去冗余(方法是MMR)等.这种方式应用最广泛,因为比较简单.经典方法有Lex ...
随机推荐
- JDK(Java Development Kit)内置常用自带工具一览(转)
注意:可能随着JDK的版本升级,工具也会随着增多. JDK(Java Development Kit)是Java程序员最核心的开发工具,没有之一. JDK是一个功能强大的Java开发套装,它不仅仅为我 ...
- 查看当前Java进程工具jps(转)
jps是JDK提供的一个查看当前Java进程的小工具, 可以看做是JavaVirtual Machine Process Status Tool的缩写.非常简单实用. 命令格式: jps [optio ...
- Intellij Idea 13:导入openfire源代码
网络上已经有篇关于openfire导入到Intellij Idea的文章(http://www.th7.cn/Program/java/201404/187018.shtml),不过在我导入的过程中, ...
- Java三行代码搞定MD5加密
Java三行代码搞定MD5加密 https://www.dexcoder.com/selfly/article/4026 public class MD5Test { public static vo ...
- Java 设计模式—装饰者模式
在Java编程语言中,嵌套了非常多设计模式的思想,比如IO流中的缓冲流就使用到以下要介绍的装饰者设计模式. 演示样例代码: * 抽象构件角色:定义一个抽象接口,来规范准备附加功能的类 * @autho ...
- 一条SQL面试题
求其中同一个主叫号码的两次通话之间间隔大于10秒的通话记录ID 例如:6,7,8,9,10条记录均符合 ID 主叫号码 被叫号码 通话起始时间 通话结束时间 ...
- Yslow on Nodejs server
1. 目的:用yslow测试某个页面的性能 2. 需求:返回yslow测试后的数据,显示在页面 方法一. nodejs 需要把网址打包为har格式... 方法二. phantomjs 步骤: 1. 安 ...
- 将TensorFlow模型变为pb——官方本身提供API,直接调用即可
TensorFlow: How to freeze a model and serve it with a python API 参考:https://blog.metaflow.fr/tensorf ...
- bzoj1895
fhqtreap 其实fhqtreap只有可持久化之后才用新建节点... reverse和splay一样. //#include<bits/stdc++.h> #include<cs ...
- curl强制下载文件
<?phpfunction download_remote_file_with_curl($file_url, $save_to) { $ch = curl_init(); curl_setop ...