Beam编程系列之Java SDK Quickstart(官网的推荐步骤)
不多说,直接上干货!
https://beam.apache.org/get-started/beam-overview/
https://beam.apache.org/get-started/quickstart-java/
Apache Beam Java SDK Quickstart
This Quickstart will walk you through executing your first Beam pipeline to run WordCount, written using Beam’s Java SDK, on a runner of your choice.
- Set up your Development Environment
- Get the WordCount Code
- Run WordCount
- Inspect the results
- Next Steps
我这里为了方便大家快速入手,翻译并整理为中文。
本博文通过使用 Java SDK 来完成,你可以尝试运行在不同的执行引擎上。
第一步:设置开发环境
- 下载并安装 Java Development Kit (JDK) 1.7 或更高版本。检查 JAVA_HOME 环境变量已经设置并指向你的 JDK 安装目录。
- 照着 Maven 的 安装指南 下载并安装适合你的操作系统的 Apache Maven 。
第二步:获取 示例的WordCount 代码
获得一份 WordCount 管线代码拷贝最简单的方法,就是使用下列指令来生成一个简单的、包含基于 Beam 最新版的 WordCount 示例和构建的 Maven 项目:
Apache Beam 的源代码在 Github 有托管,可以到 Github 下载对应的源码,下载地址:https://github.com/apache/beam
然后,将其中的示例代码进行打包,命令如下所示:(这是最新稳定版本)(所以一般用这个)
$ mvn archetype:generate \
-DarchetypeRepository=https://repository.apache.org/content/groups/snapshots \
-DarchetypeGroupId=org.apache.beam \
-DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples \
-DarchetypeVersion=LATEST \
-DgroupId=org.example \
-DartifactId=word-count-beam \
-Dversion="0.1" \
-Dpackage=org.apache.beam.examples \
-DinteractiveMode=false
这是官网推荐的
$ mvn archetype:generate \
-DarchetypeGroupId=org.apache.beam \
-DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples \
-DarchetypeVersion=2.1. \
-DgroupId=org.example \
-DartifactId=word-count-beam \
-Dversion="0.1" \
-Dpackage=org.apache.beam.examples \
-DinteractiveMode=false
那是因为,最新的Bean为2.1.0。
这将创建一个叫 word-count-beam 的目录,其中包含了一份简单的 pom.xml 文件和一套示例管线,用来计算某个文本文件中的各个单词的数量。
$ cd word-count-beam/ $ ls
pom.xml src $ ls src/main/java/org/apache/beam/examples/
DebuggingWordCount.java WindowedWordCount.java common
MinimalWordCount.java WordCount.java
关于这些示例中用到的 Beam 的概念的详细介绍,请阅读 WordCount Example Walkthrough 一文。这里我们只聚焦于如何执行 WordCount.java 上。
运行 WordCount 示例代码
一个 Beam 程序可以运行在多个 Beam 的可执行引擎上,包括 ApexRunner,FlinkRunner,SparkRunner 或者 DataflowRunner。 另外还有 DirectRunner。不需要特殊的配置就可以在本地执行,方便测试使用。
下面,你可以按需选择你想执行程序的引擎,即哪个runner后:
- 对引擎进行相关配置,确保你已经正确配置了该runner。
- 使用不同的命令:通过 --runner=<runner>参数指明引擎类型,默认是 DirectRunner;添加引擎相关的参数;指定输出文件和输出目录,当然这里需要保证文件目录是执行引擎可以访问到的,比如本地文件目录是不能被外部集群访问的。
- 运行示例程序,你的第一个WordCount 管线。
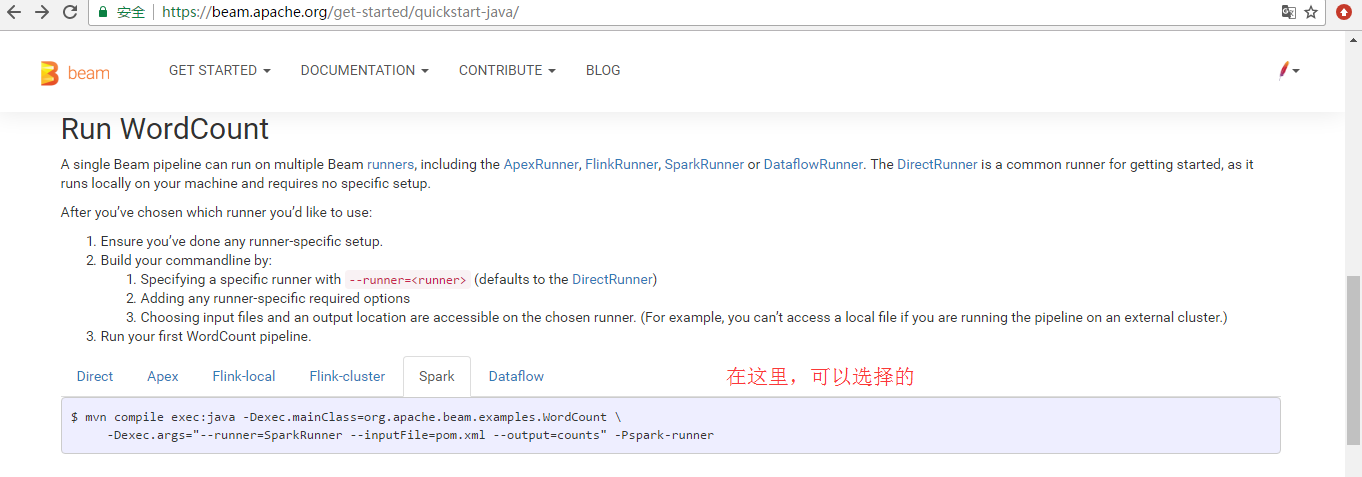
Direct
$ mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \
-Dexec.args="--inputFile=pom.xml --output=counts" -Pdirect-runner
Apex
$ mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \
-Dexec.args="--inputFile=pom.xml --output=counts --runner=ApexRunner" -Papex-runner
Flink-Local
$ mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \
-Dexec.args="--runner=FlinkRunner --inputFile=pom.xml --output=counts" -Pflink-runner
Flink-Cluster
$ mvn package exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \
-Dexec.args="--runner=FlinkRunner --flinkMaster=<flink master> --filesToStage=target/word-count-beam-bundled-0.1.jar \
--inputFile=/path/to/quickstart/pom.xml --output=/tmp/counts" -Pflink-runner You can monitor the running job by visiting the Flink dashboard at http://<flink master>:8081
然后,你可以通过访问 http://<flink master>:8081 来监测运行的应用程序。
Spark
$ mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \
-Dexec.args="--runner=SparkRunner --inputFile=pom.xml --output=counts" -Pspark-runner
Dataflow
$ mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \
-Dexec.args="--runner=DataflowRunner --project=<your-gcp-project> \
--gcpTempLocation=gs://<your-gcs-bucket>/tmp \
--inputFile=gs://apache-beam-samples/shakespeare/* --output=gs://<your-gcs-bucket>/counts" \
-Pdataflow-runner
运行结果
当程序运行完成后,你可以看到有多个文件以 count 开头,个数取决于执行引擎的类型。当你查看文件的内容的时候,每个唯一的单词后面会显示其出现次数,但是前后顺序是不固定的,也是分布式引擎为了提高效率的一种常用方式。
一旦管线完成运行,你可以查看结果。你会注意到有多个以 count 打头的输出文件。具体会有几个这样的文件是由 runner 决定的。这样能方便 runner 进行高效的分布式执行。
当你查看文件内容的时候,你会看到里面包含每个单词的出现数量。文件中的元素顺序可能会和这里看到的不同。因为 Beam 模型通常并不保障顺序,以便于 runner 优化效率。
Direct
$ ls counts* $ more counts*
api: 9
bundled: 1
old: 4
Apache: 2
The: 1
limitations: 1
Foundation: 1
...
Apex
$ cat counts*
BEAM: 1
have: 1
simple: 1
skip: 4
PAssert: 1
...
Flink-Local
$ ls counts* $ more counts*
The: 1
api: 9
old: 4
Apache: 2
limitations: 1
bundled: 1
Foundation: 1
...
Flink-Cluster
$ ls /tmp/counts* $ more /tmp/counts*
The: 1
api: 9
old: 4
Apache: 2
limitations: 1
bundled: 1
Foundation: 1
...
Spark
$ ls counts* $ more counts*
beam: 27
SF: 1
fat: 1
job: 1
limitations: 1
require: 1
of: 11
profile: 10
...
Dataflow
$ gsutil ls gs://<your-gcs-bucket>/counts* $ gsutil cat gs://<your-gcs-bucket>/counts*
feature: 15
smother'st: 1
revelry: 1
bashfulness: 1
Bashful: 1
Below: 2
deserves: 32
barrenly: 1
...
总结
Apache Beam 主要针对理想并行的数据处理任务,并通过把数据集拆分多个子数据集,让每个子数据集能够被单独处理,从而实现整体数据集的并行化处理。当然,也可以用 Beam 来处理抽取,转换和加载任务和数据集成任务(一个ETL过程)。进一步将数据从不同的存储介质中或者数据源中读取,转换数据格式,最后加载到新的系统中。
Beam编程系列之Java SDK Quickstart(官网的推荐步骤)的更多相关文章
- Beam编程系列之Python SDK Quickstart(官网的推荐步骤)
不多说,直接上干货! https://beam.apache.org/get-started/quickstart-py/ Beam编程系列之Java SDK Quickstart(官网的推荐步骤)
- Beam编程系列之Apache Beam WordCount Examples(MinimalWordCount example、WordCount example、Debugging WordCount example、WindowedWordCount example)(官网的推荐步骤)
不多说,直接上干货! https://beam.apache.org/get-started/wordcount-example/ 来自官网的: The WordCount examples demo ...
- Java并发编程系列-(5) Java并发容器
5 并发容器 5.1 Hashtable.HashMap.TreeMap.HashSet.LinkedHashMap 在介绍并发容器之前,先分析下普通的容器,以及相应的实现,方便后续的对比. Hash ...
- Java并发编程系列-(6) Java线程池
6. 线程池 6.1 基本概念 在web开发中,服务器需要接受并处理请求,所以会为一个请求来分配一个线程来进行处理.如果每次请求都新创建一个线程的话实现起来非常简便,但是存在一个问题:如果并发的请求数 ...
- Java并发编程系列-(7) Java线程安全
7. 线程安全 7.1 线程安全的定义 如果多线程下使用这个类,不过多线程如何使用和调度这个类,这个类总是表示出正确的行为,这个类就是线程安全的. 类的线程安全表现为: 操作的原子性 内存的可见性 不 ...
- Java 银联支付官网demo测试及项目整合代码
注:原文来源与 < Java 银联支付官网demo测试及项目整合代码 > 银联支付(网关支付B2C) 一.测试官网demo a)下载官网开发包,导入eclipse等待修改(下载的开发包没 ...
- 【ABAP系列】SAP LSMW(摘自官网)
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[MM系列]SAP LSMW(摘自官网) 前 ...
- Ubuntu16.04下Neo4j图数据库官网安装部署步骤(图文详解)(博主推荐)
不多说,直接上干货! 说在前面的话 首先,查看下你的操作系统的版本. root@zhouls-virtual-machine:~# cat /etc/issue Ubuntu LTS \n \l r ...
- Ubuntu14.04下Neo4j图数据库官网安装部署步骤(图文详解)(博主推荐)
不多说,直接上干货! 说在前面的话 首先,查看下你的操作系统的版本. root@zhouls-virtual-machine:~# cat /etc/issue Ubuntu 14.04.4 LTS ...
随机推荐
- Jquery hover 事件
hover(over,out)一个模仿悬停事件(鼠标移动到一个对象上面及移出这个对象)的方法.这是一个自定义的方法,它为频繁使用的任务提供了一种“保持在其中”的状态. 当鼠标移动到一个匹配的元素上面时 ...
- SQL 2005报错之Restore fail for Server 'DatabaseServerName'.
Restore fail for Server 'DatabaseServerName'.(Microsoft.SqlServer.Smo) Additional information: Syste ...
- vs 2017局域网内调试
之前调试代码都是在本地启动服务,以 localhost:端口号 的形式调试,今天发现也是可以用ip地址的形式来调用接口,这种方式可以支持内网内Client端调用接口,实现调试的功能,具体方法如下 ...
- Markdown使用心得
1. 标题的使用 在使用标题时,如果为了层次清晰,可以在"#"后加上"1. "或者"1.1. "这种序号. 每一级标题的正文结束后,最好加一 ...
- SQLServer 统计查询语句消耗时间
--方法1[set statistic ]: set statistics time on go --执行语句 xxxx go set statistics time off --方法2[getDat ...
- [转载]ssget 用法详解 by yxp
总结得很好的ssget用法.....如此好文,必须转载. 原文地址: http://blog.csdn.net/yxp_xa/article/details/72229202 ssget 用法详解 b ...
- Java面向对象之USB接口实例
一.需求: 1.在电脑上设置一个USB接口. 2.电脑运行时,将鼠标连接到接口上,鼠标可以使用自己的功能. 3.电脑运行时,将键盘连接到接口上,键盘可以使用自己的功能.(使用接口的作用:减低鼠标.键盘 ...
- python参数传递:对象的引用
大家都知道在python中,一切皆对象,变量也不再具有类型,变量仅仅是对象的一个引用,我们通常用变量来测类型,通常测得就是被这个变量引用得对象的类型. python采用的是传递对象的引用,为了方便说明 ...
- 17、OpenCV Python 数字验证码识别
__author__ = "WSX" import cv2 as cv import numpy as np from PIL import Image import pytess ...
- CodeCraft-19 and Codeforces Round #537 (Div. 2) C. Creative Snap 分治
Thanos wants to destroy the avengers base, but he needs to destroy the avengers along with their bas ...