《最新出炉》系列入门篇-Python+Playwright自动化测试-10-标签页操作(tab)
1.简介
标签操作其实也是基于浏览器上下文(BrowserContext)进行操作的,而且宏哥在之前的BrowserContext也有提到过,但是有的童鞋或者小伙伴还是不清楚怎么操作,或者思路有点模糊,因此今天单独来对其进行讲解和分享一下,希望您有所帮助。
2.单标签页
单个标签操作这个是最简单的,之前讲的绝大多数都是单个标签的操作。通过context.new_page()就可以创建一个页面。
实战举例:以度娘为例,首先启动浏览器,然后再设置浏览器的大小。查询“北京宏哥”后,刷新页面执行回退到百度首页,然后有执行前进进入到搜索“北京宏哥”页面,最后退出浏览器。
2.1代码设计
按照上边的步骤进行代码设计,如下图所示:
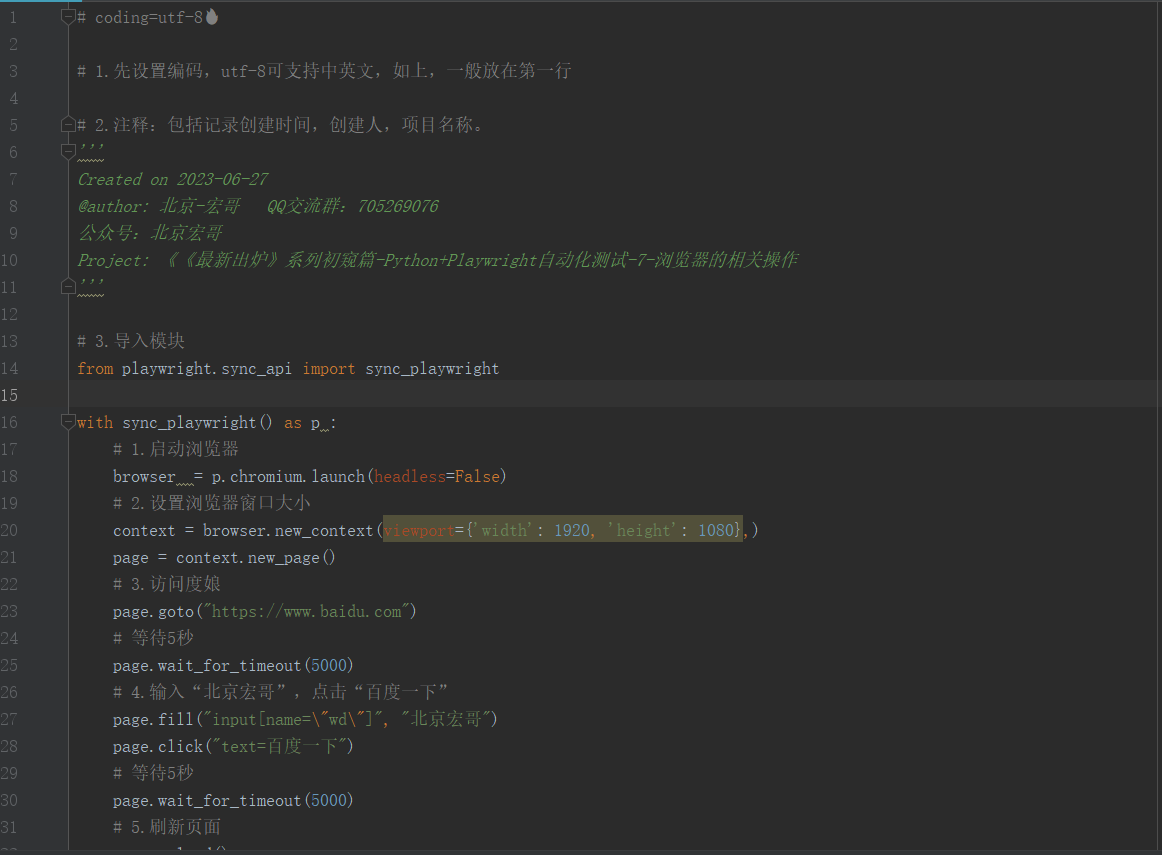
2.2参考代码
# coding=utf-8 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-06-27
@author: 北京-宏哥 QQ交流群:705269076
公众号:北京宏哥
Project: 《《最新出炉》系列初窥篇-Python+Playwright自动化测试-10-标签页操作
''' # 3.导入模块
from playwright.sync_api import sync_playwright with sync_playwright() as p :
# 1.启动浏览器
browser = p.chromium.launch(headless=False)
# 2.设置浏览器窗口大小
context = browser.new_context(viewport={'width': 1920, 'height': 1080},)
page = context.new_page()
# 3.访问度娘
page.goto("https://www.baidu.com")
# 等待5秒
page.wait_for_timeout(5000)
# 4.输入“北京宏哥”,点击“百度一下”
page.fill("input[name=\"wd\"]", "北京宏哥")
page.click("text=百度一下")
# 等待5秒
page.wait_for_timeout(5000)
# 5.刷新页面
page.reload()
# 等待5秒
page.wait_for_timeout(5000)
# 6.浏览器后退
page.go_back()
# 等待5秒
page.wait_for_timeout(5000)
# 7.浏览器前进
page.go_forward()
# 8.浏览器退出
page.wait_for_timeout(5000)
context.close()
browser.close()
2.3运行代码
1.运行代码,右键Run'Test',控制台输出,如下图所示:

2.运行代码后电脑端的浏览器的动作,可以看到查询“北京宏哥”后,刷新页面执行回退到百度首页,然后有执行前进进入到搜索“北京宏哥”页面。如下图所示:

3.多标签页
每个浏览器上下文可以承载多个页面(选项卡)。
- 每个页面都像一个聚焦的活动页面。不需要将页面置于最前面。
- 上下文中的页面遵循上下文级别的模拟,例如视口大小、自定义网络路由或浏览器区域设置。
# create two pages
page_one = context.new_page()
page_two = context.new_page() # get pages of a browser context
all_pages = context.pages
实战举例:在page_one 标签页打开百度,输入“北京-宏哥”, 在page_two 标签页打开百度,输入“宏哥”。
3.1代码设计
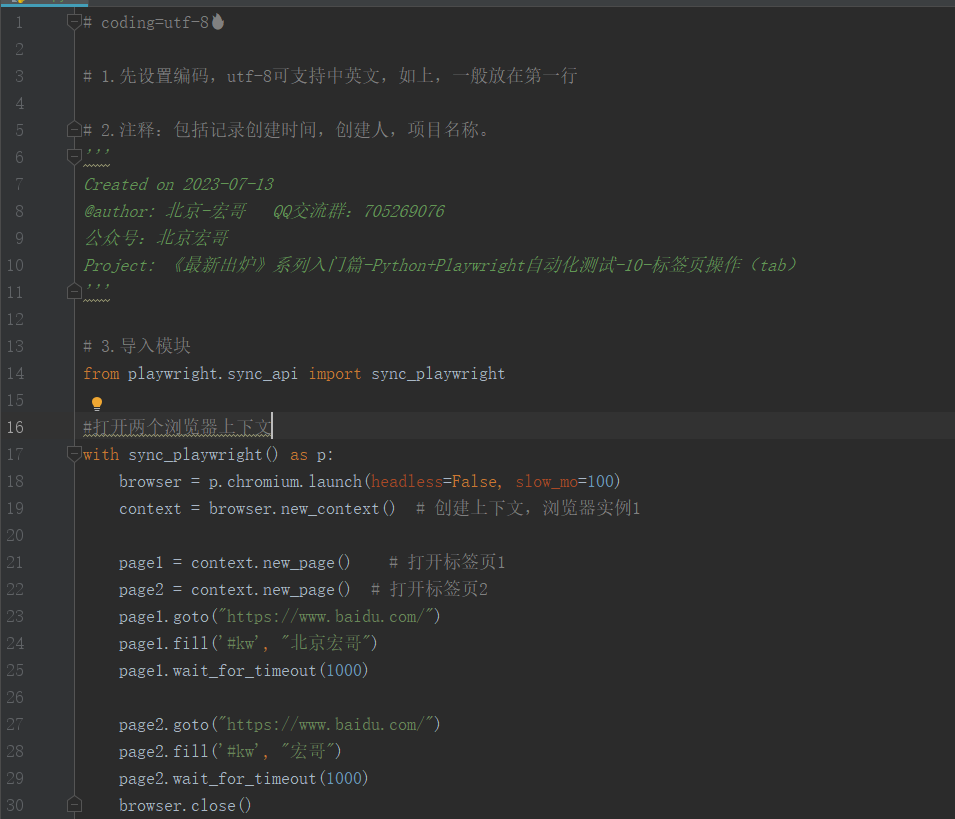
3.2参考代码
# coding=utf-8 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-07-13
@author: 北京-宏哥 QQ交流群:705269076
公众号:北京宏哥
Project: 《最新出炉》系列入门篇-Python+Playwright自动化测试-10-标签页操作(tab)
''' # 3.导入模块
from playwright.sync_api import sync_playwright #打开两个浏览器上下文
with sync_playwright() as p:
browser = p.chromium.launch(headless=False, slow_mo=100)
context = browser.new_context() # 创建上下文,浏览器实例1 page1 = context.new_page() # 打开标签页1
page2 = context.new_page() # 打开标签页2
page1.goto("https://www.baidu.com/")
page1.fill('#kw', "北京宏哥")
page1.wait_for_timeout(1000) page2.goto("https://www.baidu.com/")
page2.fill('#kw', "宏哥")
page2.wait_for_timeout(1000)
browser.close()
3.3运行代码
1.运行代码,右键Run'Test',控制台输出,如下图所示:
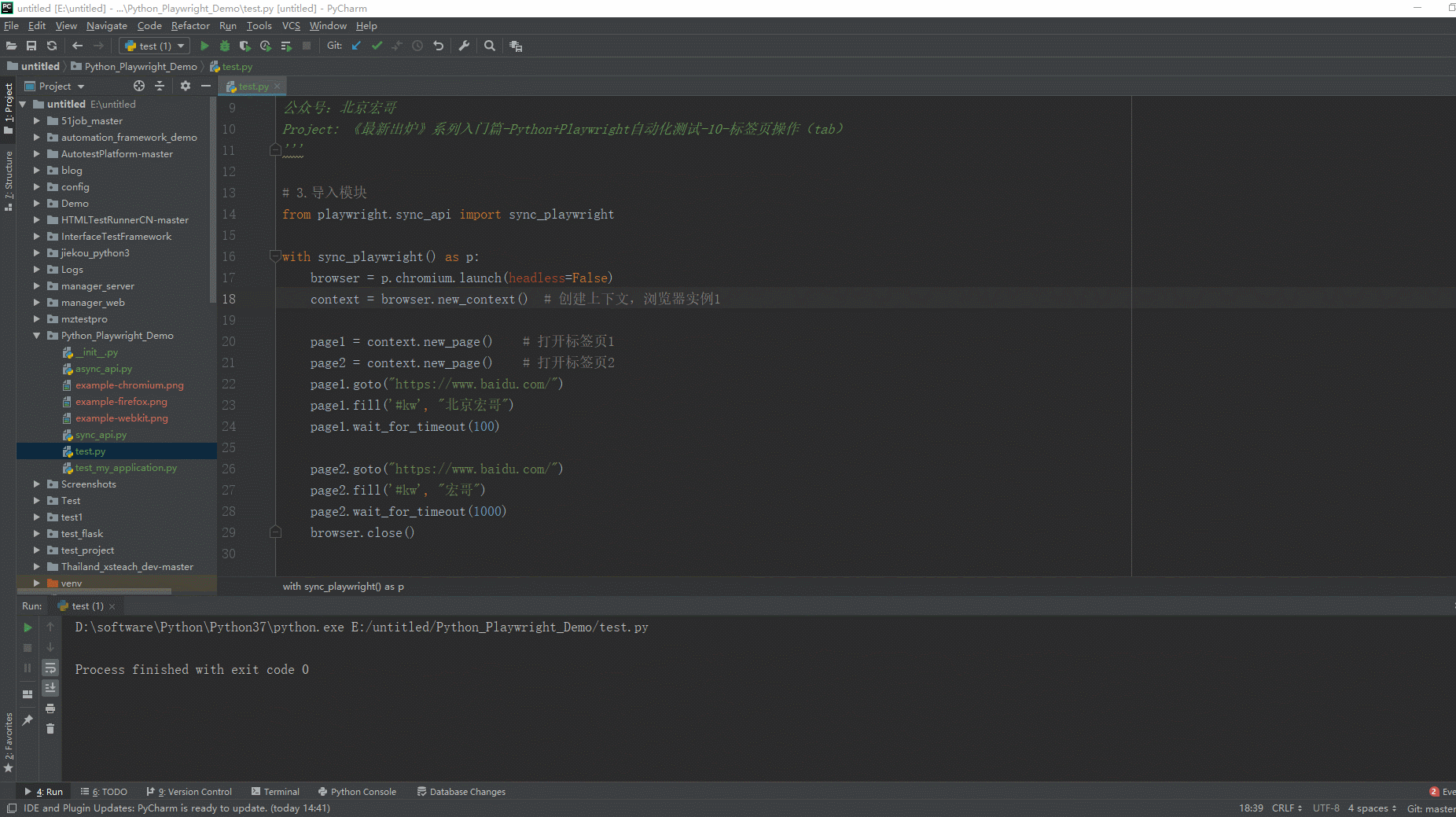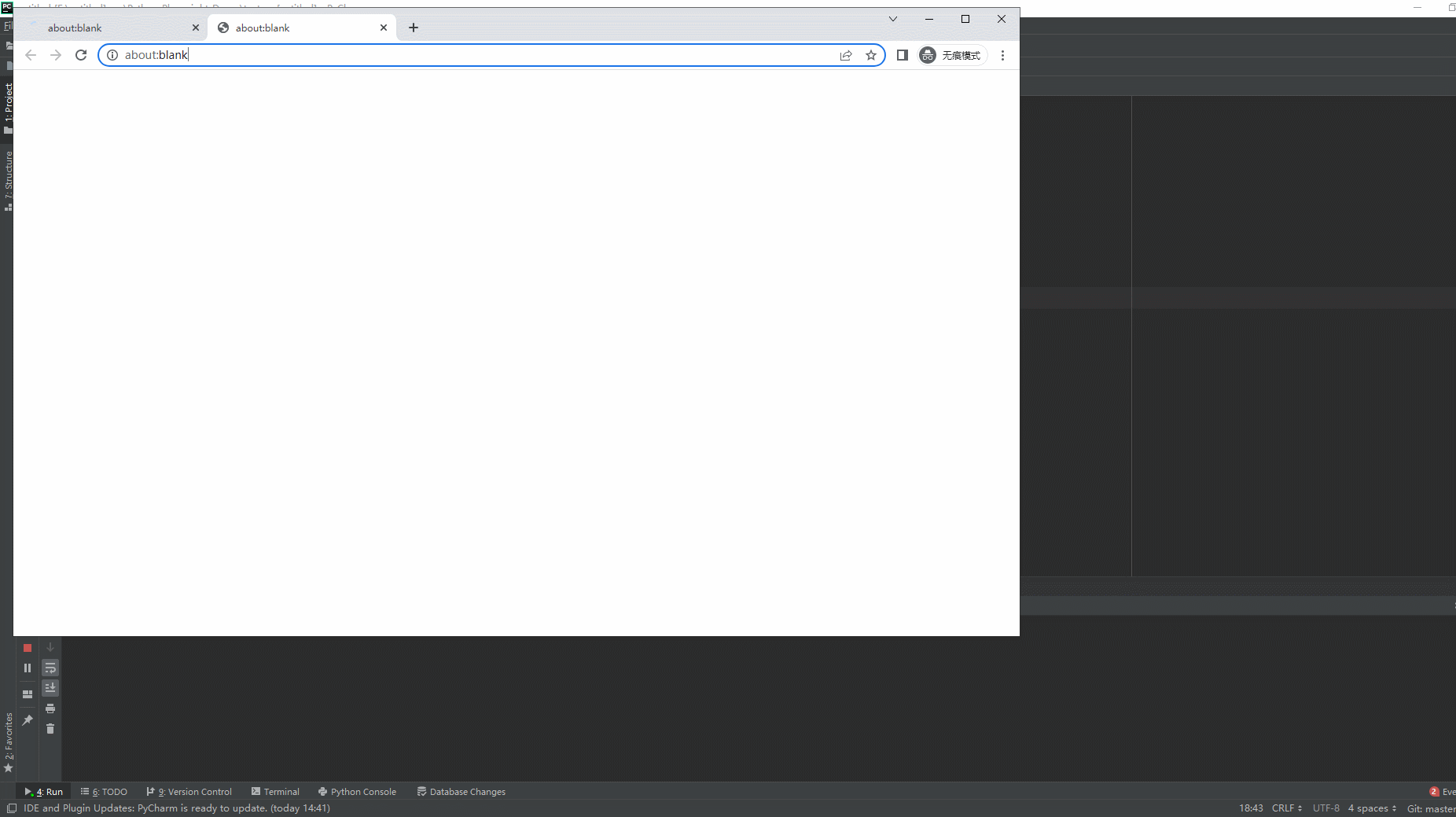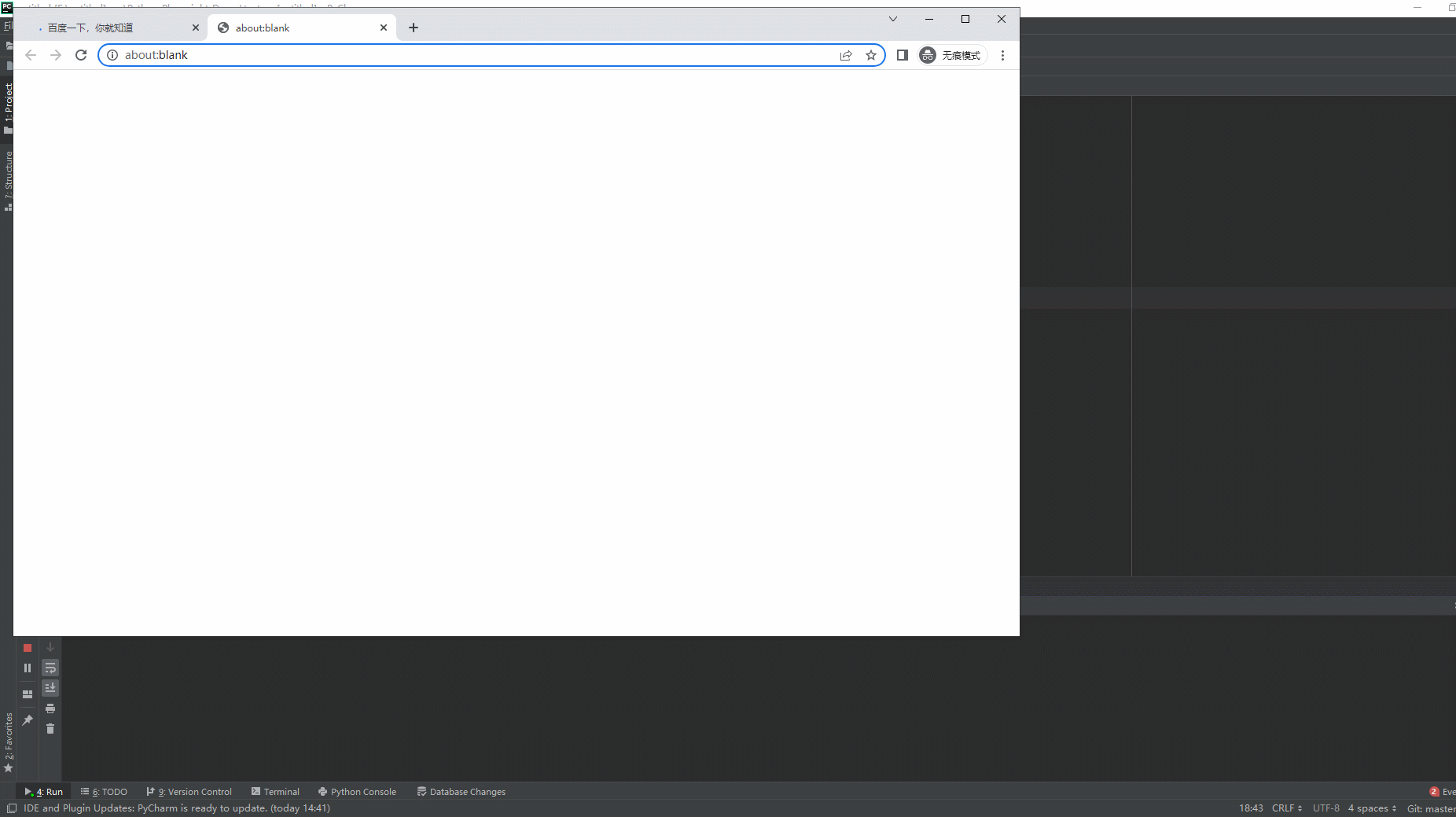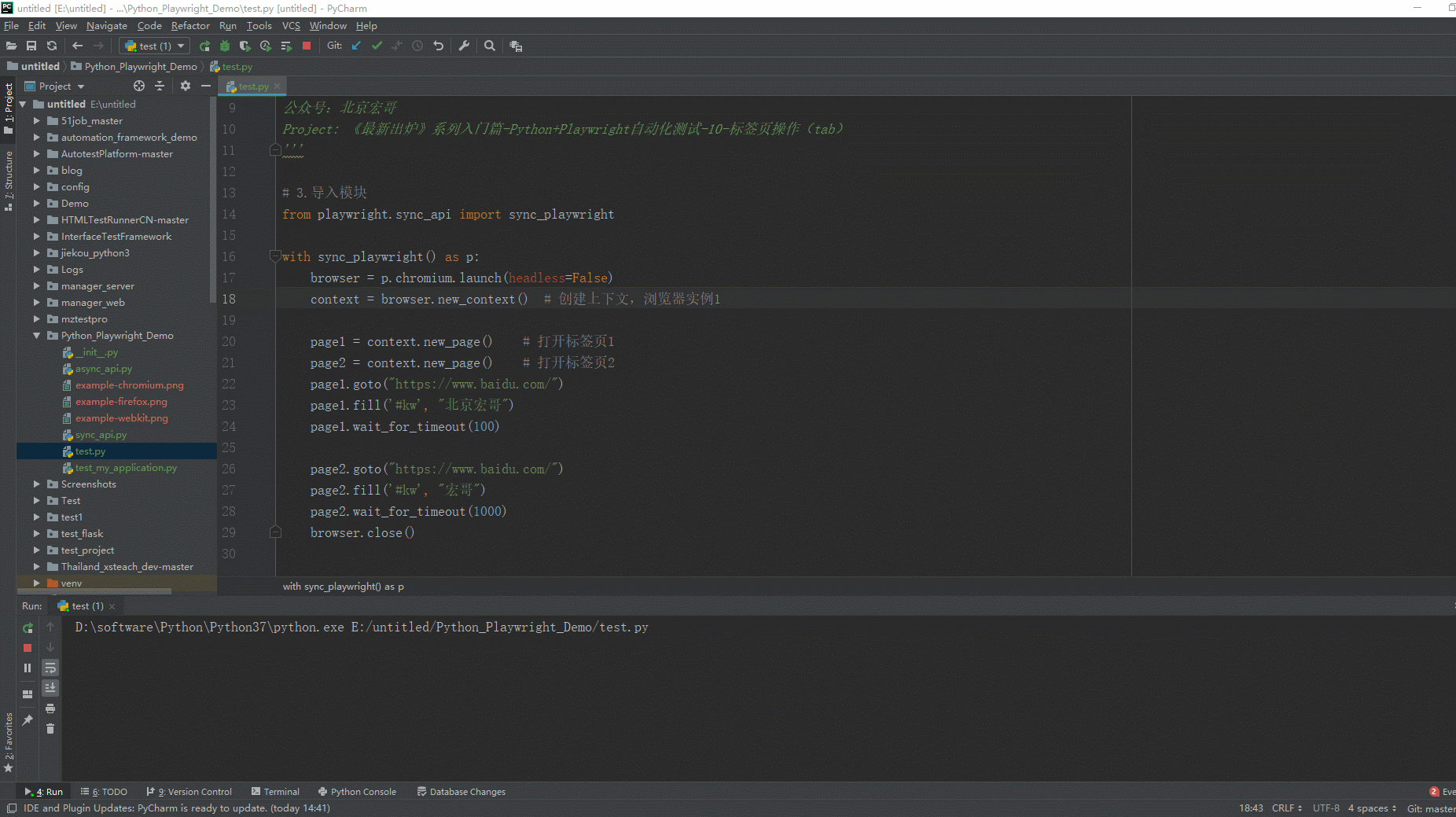
2.运行代码后电脑端的浏览器的动作。虽然你看不到第一个页面的操作,实际上它已经操作了,每个页面 page对象都是聚焦的活动页面, 不需要将页面置于最前面。如下图所示:
4.处理新标签页
浏览器上下文中的事件page可用于获取在上下文中创建的新页面。这可用于处理通过target="_blank"链接打开的新页面。
# Get page after a specific action (e.g. clicking a link)
with context.expect_page() as new_page_info:
page.get_by_text("open new tab").click() # Opens a new tab
new_page = new_page_info.value new_page.wait_for_load_state()
print(new_page.title())
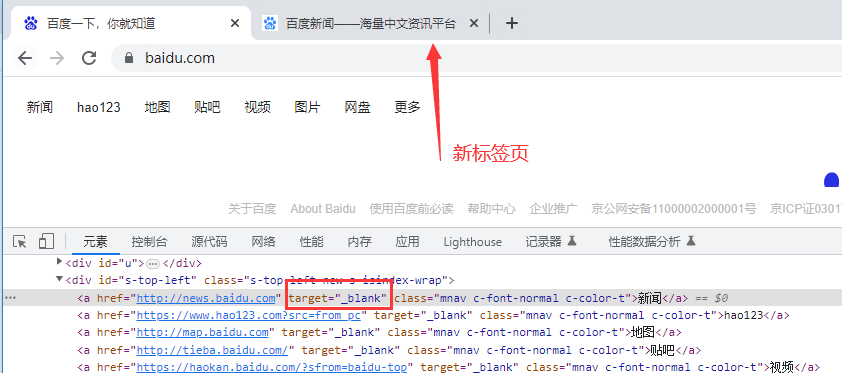
实战举例:打开百度页面的-新闻链接,会出现一个新标签页,如下图所示:
4.1代码设计
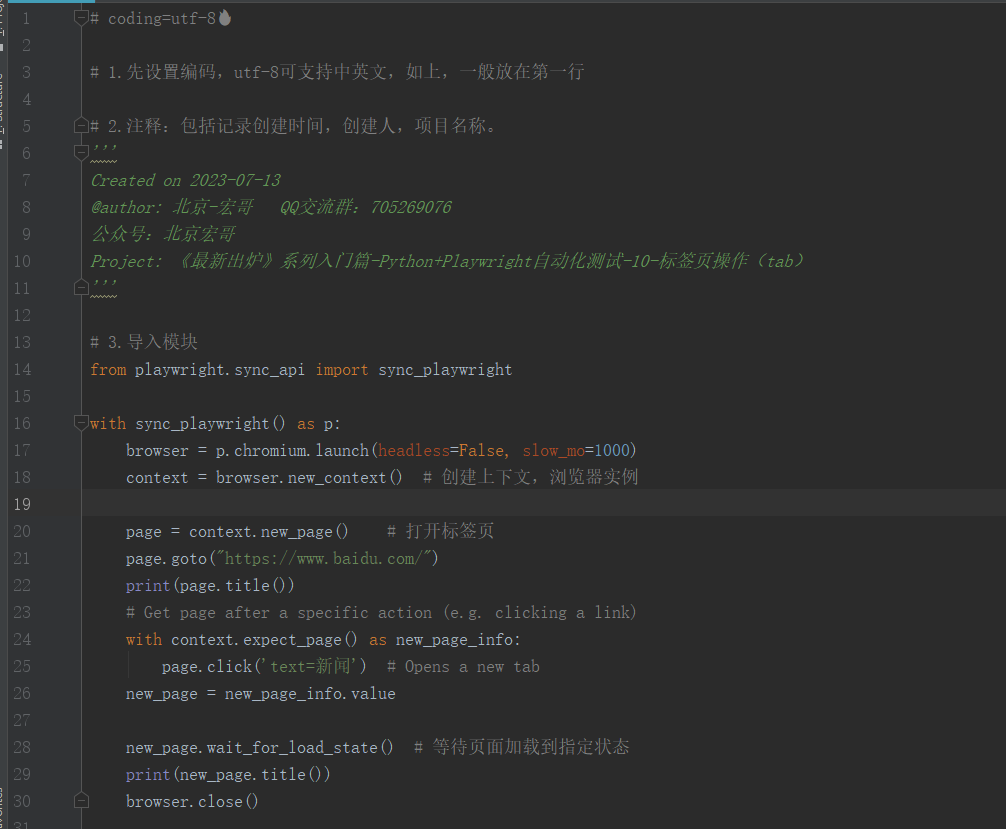
4.2参考代码
# coding=utf-8 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-07-13
@author: 北京-宏哥 QQ交流群:705269076
公众号:北京宏哥
Project: 《最新出炉》系列入门篇-Python+Playwright自动化测试-10-标签页操作(tab)
''' # 3.导入模块
from playwright.sync_api import sync_playwright with sync_playwright() as p:
browser = p.chromium.launch(headless=False, slow_mo=1000)
context = browser.new_context() # 创建上下文,浏览器实例 page = context.new_page() # 打开标签页
page.goto("https://www.baidu.com/")
print(page.title())
# Get page after a specific action (e.g. clicking a link)
with context.expect_page() as new_page_info:
page.click('text=新闻') # Opens a new tab
new_page = new_page_info.value new_page.wait_for_load_state() # 等待页面加载到指定状态
print(new_page.title())
browser.close()
4.3运行代码
1.运行代码,右键Run'Test',控制台输出,如下图所示:

2.运行代码后电脑端的浏览器的动作。如下图所示:
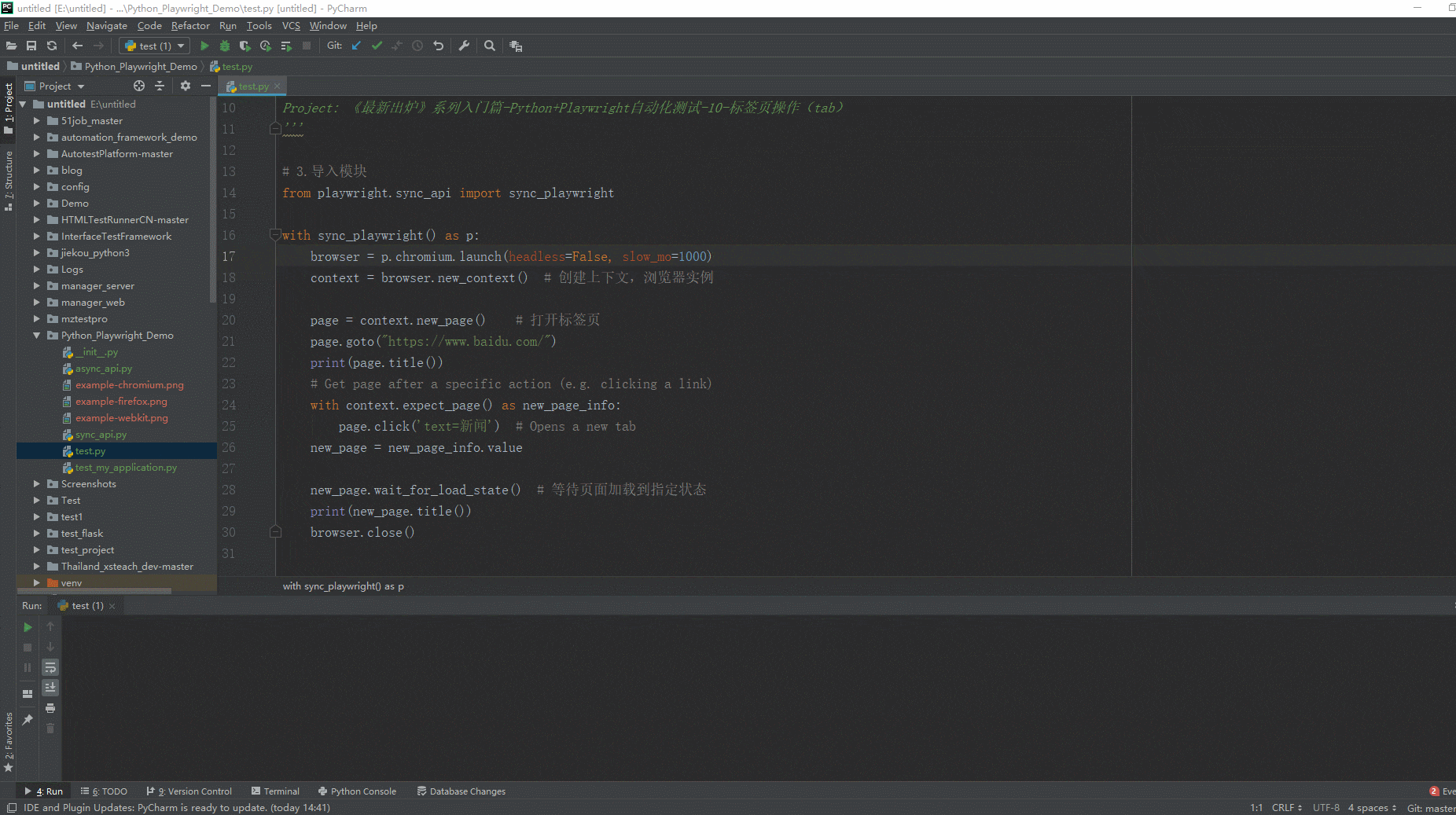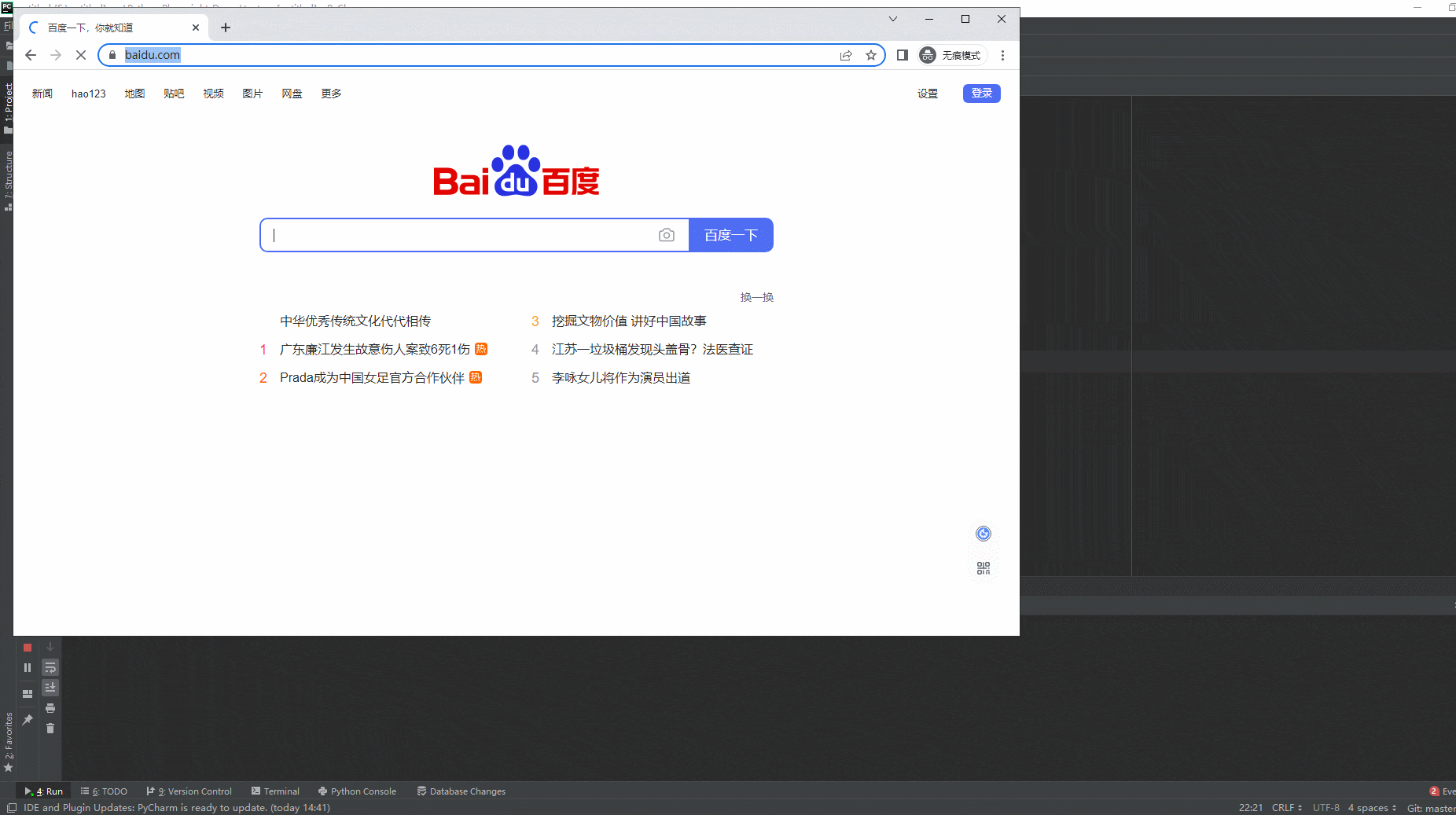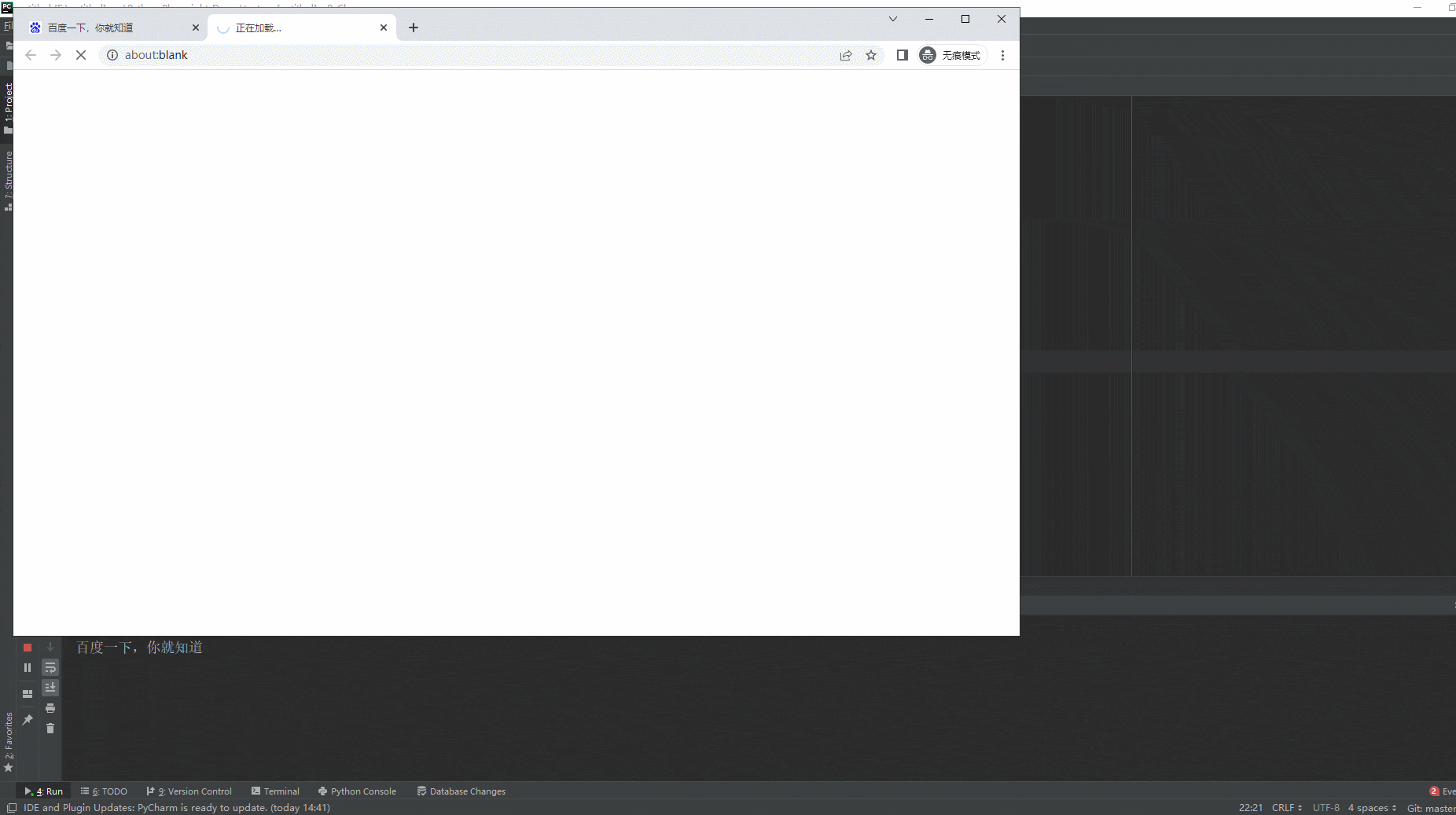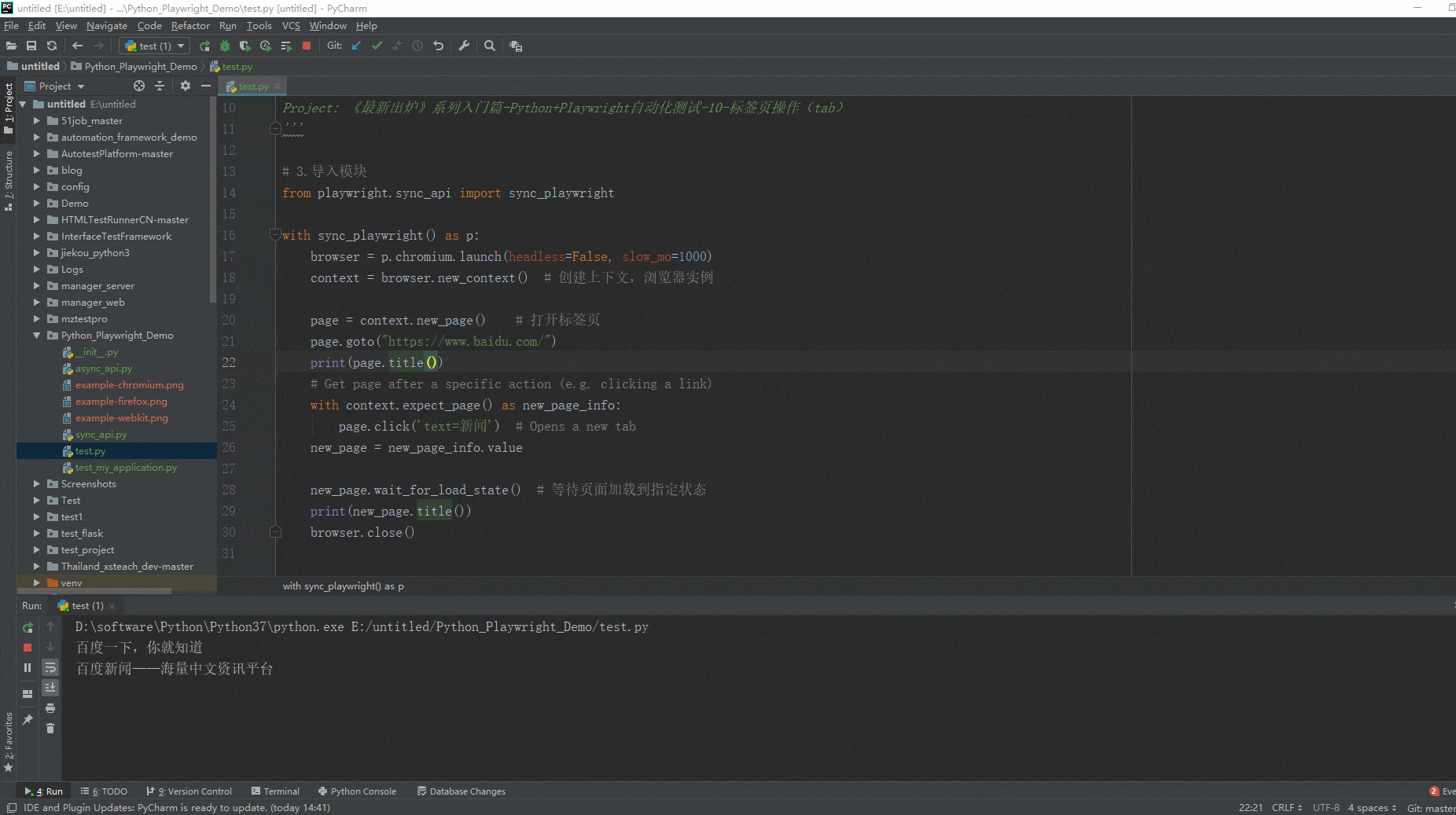
如果触发新页面的操作未知,可以使用以下模式。
# Get all new pages (including popups) in the context
def handle_page(page):
page.wait_for_load_state()
print(page.title()) context.on("page", handle_page)
5.处理弹出窗口
如果页面打开一个弹出窗口(例如通过链接打开的页面),您可以通过监听页面上的事件target="_blank"来获取对它的引用。popup
除了browserContext.on('page')事件之外还会发出此事件,但仅针对与此页面相关的弹出窗口。
# Get popup after a specific action (e.g., click)
with page.expect_popup() as popup_info:
page.get_by_text("open the popup").click()
popup = popup_info.value popup.wait_for_load_state()
print(popup.title())
如果触发弹出窗口的操作未知,则可以使用以下模式。
# Get all popups when they open
def handle_popup(popup):
popup.wait_for_load_state()
print(popup.title()) page.on("popup", handle_popup)
6.小结
好了,时间不早了,关于标签操作宏哥就今天就分享到这里。感谢你耐心地阅读。
《最新出炉》系列入门篇-Python+Playwright自动化测试-10-标签页操作(tab)的更多相关文章
- Spring实践系列-入门篇(一)
本文主要介绍了在本地搭建并运行一个Spring应用,演示了Spring依赖注入的特性 1 环境搭建 1.1 Maven依赖 目前只用到依赖注入的功能,故以下三个包已满足使用. <properti ...
- Google C++测试框架系列入门篇:第三章 基本概念
上一篇:Google C++测试框架系列入门篇:第二章 开始一个新项目 原始链接:Basic Concepts 词汇表 版本号:v_0.1 基本概念 使用GTest你肯定会接触到断言这个概念.断言是用 ...
- Google C++测试框架系列入门篇:第二章 开始一个新项目
上一篇:Google C++测试框架系列入门篇:第一章 介绍:为什么使用GTest? 原始链接:Setting up a New Test Project 词汇表 版本号:v_0.1 开始一个新项目 ...
- 深入浅出ASP.NET Core系列(入门篇)
入门篇 1.1.专题介绍 1.2.环境安装 1.3.创建项目 1.4部署到IIS 1.5准备CentOS和Nginx环境 1.6部署到CentOS 2.1命令行和JSON的配置 2.2Bind建立配置 ...
- 0x00-Kali Linux 系列入门篇
Kali Linux介绍篇 Kali Linux 官网:https://www.kali.org/ Kali Linux 前身是著名渗透测试系统BackTrack ,是一个基于 Debian 的 Li ...
- Node.js 从入门到茫然系列——入门篇
在创建服务的时候,我们一般代码就是: var http = require("http"); var server = http.createServer(function(req ...
- Google C++测试框架系列入门篇:第一章 介绍:为什么使用GTest?
原始链接:Introduction: Why Google C++ Testing Framework? 词汇表 版本号:v_0.1 介绍:为什么使用GTest? GTest帮助你写更好的C++测试代 ...
- 剖析Elasticsearch集群系列第一篇 Elasticsearch的存储模型和读写操作
剖析Elasticsearch集群系列涵盖了当今最流行的分布式搜索引擎Elasticsearch的底层架构和原型实例. 本文是这个系列的第一篇,在本文中,我们将讨论的Elasticsearch的底层存 ...
- HTML--HTML入门篇(我想10分钟入门HTML,可以,交给我吧)
我要正经的讲一节课,咳咳! HTML简介(废话) HTML称为超文本标记语言,是一种标识性的语言.它包括一系列标签.通过这些标签可以将网络上的文档格式统一,使分散的Internet资源连接为一个逻辑整 ...
- Nginx入门篇-基础知识与linux下安装操作
我们要深刻理解学习NG的原理与安装方法,要切合实际结合业务需求,应用场景进行灵活使用. 一.Nginx知识简述Nginx是一个高性能的HTTP服务器和反向代理服务器,也是一个 IMAP/POP3/SM ...
随机推荐
- Object o = new Object();
对象的创建过程: 1,申请内存,并初始化: 2,构造器初始化: 3,o指向对象. 对象在内存中的存储布局: 使用jol工具打印java对象在内存的存储布局: 其中,对象头的组成: 对象头包括Mark ...
- VueHub:我用 ChatGPT 开发的第一个项目,送给所有 Vue 爱好者
大家好,我是DOM哥. 我用 ChatGPT 开发了一个 Vue 的资源导航网站. 不管你是资深 Vue 用户,还是刚入门想学习 Vue 的小白,这个网站都能帮助到你. 网站地址:https://do ...
- UDP内核发包流程
背景 工作中遇到客户反馈,上层应用UDP固定间隔100ms发包,但本地tcpdump抓包存在波动,有的数据包之间间隔107ms甚至更多,以此重新梳理了下udp的发送流程. udp发包流程 udp_se ...
- 第一个c语言项目
怎么写代码呢 工具:编译器 市面上编译器主要有:clang,gcc,win-tc,msvc,turbo c等 怎么写呢 1.创建一个项目(项目名字不能以中文文字命名) 2.创建一个文件(项目名字不能以 ...
- #Python基础 利用Pyinstaller 模块对python代码进行打包exe
一般我们都用 Python 的 Pyinstaller 模块进行打包,这里记录Pyinstaller 模块进行打包. 一:安装 Pyinstaller 模块 pip install PyInstall ...
- selenium文件上传和弹框处理
文件上传 input 标签可以直接使用send_keys(文件地址)上传文件 用法: el = driver.find_element_by_id('上传按钮id') el.send_keys(&qu ...
- 关于python中的OSError报错问题
Traceback (most recent call last): File "main.py", line 1, in <module> from trai ...
- 2020-03-02:在无序数组中,如何求第K小的数?
2020-03-02:在无序数组中,如何求第K小的数? 福哥答案2021-03-02: 1.堆排序.时间复杂度:O(N*lgK).有代码. 2.单边快排.时间复杂度:O(N).有代码. 3.bfprt ...
- 2022-03-27:class AreaResource { String area; // area表示的是地区全路径,最多可能有6级,比如: 中国,四川,成都 或者 中国,浙江,杭州 Str
2022-03-27:class AreaResource { String area; // area表示的是地区全路径,最多可能有6级,比如: 中国,四川,成都 或者 中国,浙江,杭州 Strin ...
- SQL:DATEDIFF和DATEADD函数
DATEDIFF和DATEADD函数.DATEDIFF函数计算两个日期之间的小时.天.周.月.年等时间间隔总数.DATEADD函数计算一个日期通过给时间间隔加减来获得一个新的日期.要了解更多的DATE ...