Python爬取国家统计局2009至2020统计用区划和城乡划分代码(省市区/县三级)并存入mysql数据库
国家统计局->统计标准网址:http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/
获取资源请关注公众号 【靠谱杨阅读人生】回复【城乡分类】获取
流程简介
对统计标准的网站进行分层分级爬取:


代码
import pymysql
from bs4 import BeautifulSoup
import re
import requests
import lxml
import traceback
import time
import json
from lxml import etree def get_area(year):
year=str(year)
url="http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/"+ year +"/index.html"
print(url)
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
response=requests.get(url,headers)
# print(response.text)
response.encoding='GBK'
page_text = response.text
soup=BeautifulSoup(page_text,'lxml')
# print(page_text)
all_province=soup.find_all('tr',class_='provincetr') #获取所有省份第一级的tr 有4个tr
# all_province长度为4,其中第一组是从北京市到黑龙江省
"""
格式是这样的:
<tr class="provincetr"><td><a href="11.html">北京市<br/></a></td>
<td><a href="12.html">天津市<br/></a></td>
<td><a href="13.html">河北省<br/></a></td>
<td><a href="14.html">山西省<br/></a></td>
<td><a href="15.html">内蒙古自治区<br/></a></td>
<td><a href="21.html">辽宁省<br/></a></td><td>
"""
province_str="" #为了方便处理,把省份数据变成一个字符串
for i in range(len(all_province)):
province_str=province_str+str(all_province[i])
# print(province_str)
# 开始分别获得a标签的href和text
province={}
province_soup=BeautifulSoup(province_str,'lxml')
province_href=province_soup.find_all("a") #获取所有的a标签
for i in province_href:
href_str=str(i)
# print(href_str)
#创建省份数据字典
province.update({BeautifulSoup(href_str,'lxml').find("a").text:BeautifulSoup(href_str,'lxml').find("a")["href"]})
# print(province)
"""
数据provide字典
{'北京市': '11.html', '天津市': '12.html', '河北省': '13.html', '山西省': '14.html',
'内蒙古自治区': '15.html', '辽宁省': '21.html', '吉林省': '22.html', '黑龙江省': '23.html',
'上海市': '31.html', '江苏省': '32.html', '浙江省': '33.html', '安徽省': '34.html',
'福建省': '35.html', '江西省': '36.html', '山东省': '37.html', '河南省': '41.html',
'湖北省': '42.html', '湖南省': '43.html', '广东省': '44.html', '广西壮族自治区': '45.html',
'海南省': '46.html', '重庆市': '50.html', '四川省': '51.html', '贵州省': '52.html', '云南省': '53.html',
'西藏自治区': '54.html', '陕西省': '61.html', '甘肃省': '62.html', '青海省': '63.html',
'宁夏回族自治区': '64.html', '新疆维吾尔自治区': '65.html'}
"""
# 根据身份数据字典继续爬取下一级的市级数据,创建市级数据字典
city=[]
city_url=""
city_tr=[]
temp_list=[]
for item in province.items():
# print(value)
city_url="http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/"+year+"/"+item[1]
city_html=requests.get(city_url,headers)
city_html.encoding='GBK'
city_text=city_html.text
city_tr.append(BeautifulSoup(city_text,'lxml').find_all('tr',class_="citytr"))
# 获得所有的市区tr city_tr列表长度是31 对应31个省或直辖市
# 下面开始建立市区的字典{"名字":"链接"}
#存放省名字列表
province_key=[]
for key in province.keys():
province_key.append(key)
num=0
for i in city_tr:
for j in i:
# j:<tr class="citytr"><td><a href="11/1101.html">110100000000</a></td><td><a href="11/1101.html">市辖区</a></td></tr>
# print(j)
etree_ = etree.HTML(str(j))
temp_list.append({
etree_.xpath('//tr/td[2]/a/text()')[0]:
etree_.xpath('//tr/td[2]/a/@href')[0]
})
# print(temp_list)
city.append({province_key[num]:temp_list})
num=num+1
temp_list=[]
print(len(city)) """
city[11]
{'安徽省': [{'合肥市': '34/3401.html'}, {'芜湖市': '34/3402.html'}, {'蚌埠市': '34/3403.html'},
{'淮南市': '34/3404.html'}, {'马鞍山市': '34/3405.html'}, {'淮北市': '34/3406.html'}, {'铜陵市': '34/3407.html'},
{'安庆市': '34/3408.html'}, {'黄山市': '34/3410.html'}, {'滁州市': '34/3411.html'}, {'阜阳市': '34/3412.html'},
{'宿州市': '34/3413.html'}, {'六安市': '34/3415.html'}, {'亳州市': '34/3416.html'}, {'池州市': '34/3417.html'},
{'宣城市': '34/3418.html'}]}
""" # 搞定市级字典,下面开始最后一步,area
province_name=""
city_name=""
area_name=""
area_tr=[]
area_list=[]
temp_area_list=[] for item1 in city:
for k1,v1 in item1.items():
province_name=k1
if(province_name in ["北京","天津","上海","重庆"]):
province_name=province_name+"市"
if(province_name =="宁夏"):
province_name=province_name+"回族自治区"
if(province_name in["西藏","内蒙古"]):
province_name=province_name+"自治区"
if(province_name == "新疆"):
province_name=province_name+"维吾尔自治区"
if (province_name == "广西"):
province_name = province_name + "壮族自治区"
if(province_name=="黑龙江"):
province_name=province_name+"省"
if(len(province_name)==2 and province_name not in ["西藏","宁夏","新疆","广西","北京","天津","上海","重庆"]):
province_name = province_name+"省"
for item2 in v1:
for k2,v2 in item2.items():
city_name=k2
# print(city_name)
area_url="http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/"+ year +"/"+ v2
print(area_url)
area_response=requests.get(area_url,headers)
area_response.encoding='GBK'
area_text=area_response.text
area_soup=BeautifulSoup(area_text,'lxml')
area_tr=area_soup.find_all("tr",class_="countytr")
for i in range(len(area_tr)):
etree_area = etree.HTML(str(area_tr[i]))
try:
area_name=etree_area.xpath("//tr/td[2]/a/text()")[0]
except:
area_name = etree_area.xpath("//tr/td[2]/text()")[0]
# print(area_name)
# print(str(area_tr[i]))
try:
temp_area_list.append({
etree_area.xpath("//tr/td[1]/a/text()")[0][0:6]: province_name+"·"+city_name+"·"+area_name
})
except:
temp_area_list.append({
etree_area.xpath("//tr/td[1]/text()")[0][0:6]: province_name+"·"+city_name+"·"+area_name
})
area_list.append(temp_area_list)
temp_area_list=[]
time.sleep(1)
return area_list def into_mysql(year):
year=str(year)
SQL=""
conn,cursor=get_mysql_conn()
res=get_area(year)
try:
for item in res:
for k,v in item[0].items():
print(k)
print(v)
SQL="insert into std_area (year,area_code, area_name) values ('"+year+"','"+k+"','"+v+"')"
print(SQL)
cursor.execute(SQL)
conn.commit()
except:
print("出现错误")
conn,cursor.close()
return None def query(sql,*args):
"""
通用封装查询
:param sql:
:param args:
:return:返回查询结果 ((),())
"""
conn , cursor= get_mysql_conn()
print(sql)
cursor.execute(sql)
res = cursor.fetchall()
close_conn(conn , cursor)
return res
"""
------------------------------------------------------------------------------------
"""
def get_mysql_conn():
"""
:return: 连接,游标
"""
# 创建连接
conn = pymysql.connect(host="127.0.0.1",
user="root",
password="000429",
db="data_cleaning",
charset="utf8")
# 创建游标
cursor = conn.cursor() # 执行完毕返回的结果集默认以元组显示
return conn, cursor def close_conn(conn, cursor):
if cursor:
cursor.close()
if conn:
conn.close()
if __name__ == '__main__':
# res=get_area()
into_mysql('2009')
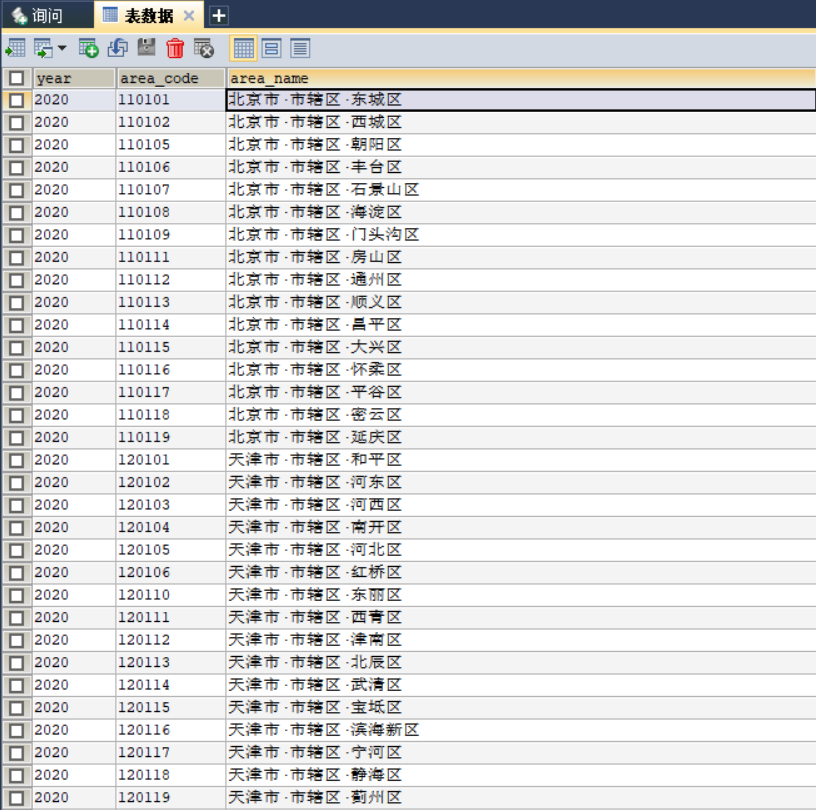
数据库截图
Python爬取国家统计局2009至2020统计用区划和城乡划分代码(省市区/县三级)并存入mysql数据库的更多相关文章
- [Python]爬取CSDN论坛 标题 2020.2.8
首先新建一个Lei.txt 内容为: CloudComputingParentBlockchainTechnologyEnterpriseDotNETJavaWebDevelopVCVBDelphiB ...
- 使用HtmlAgilityPack 爬取 国家统计局 区划和城乡划分代码
HtmlAgilityPack:Html解析神器,根据url地址解析html页面内容. 项目引用HtmlAgilityPack.dll文件或者通过安装 nuget 包 HtmlAgilityPack ...
- Python 爬取 热词并进行分类数据分析-[解释修复+热词引用]
日期:2020.02.02 博客期:141 星期日 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- Python 爬取淘宝商品数据挖掘分析实战
Python 爬取淘宝商品数据挖掘分析实战 项目内容 本案例选择>> 商品类目:沙发: 数量:共100页 4400个商品: 筛选条件:天猫.销量从高到低.价格500元以上. 爬取淘宝商品 ...
- python爬取《龙岭迷窟》的数据,看看质量剧情还原度到底怎么样
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:简单 PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行 ...
- steam夏日促销悄然开始,用Python爬取排行榜上的游戏打折信息
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 不知不觉,一年一度如火如荼的steam夏日促销悄然开始了.每年通过大大小小 ...
- Python爬取网易云音乐歌手歌曲和歌单
仅供学习参考 Python爬取网易云音乐网易云音乐歌手歌曲和歌单,并下载到本地 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做 ...
- 用Python爬取B站、腾讯视频、爱奇艺和芒果TV视频弹幕!
众所周知,弹幕,即在网络上观看视频时弹出的评论性字幕.不知道大家看视频的时候会不会点开弹幕,于我而言,弹幕是视频内容的良好补充,是一个组织良好的评论序列.通过分析弹幕,我们可以快速洞察广大观众对于视频 ...
- 用Python爬取分析【某东618】畅销商品销量数据,带你看看大家都喜欢买什么!
618购物节,辰哥准备分析一波购物节大家都喜欢买什么?本文以某东为例,Python爬取618活动的畅销商品数据,并进行数据清洗,最后以可视化的方式从不同角度去了解畅销商品中,名列前茅的商品是哪些?销售 ...
- Python爬取《你好李焕英》豆瓣短评并基于SnowNLP做情感分析
爬取过程在这里: Python爬取你好李焕英豆瓣短评并利用stylecloud制作更酷炫的词云图 本文基于前文爬取生成的douban.txt,基于SnowNLP做情感分析. 依赖库: 豆瓣镜像比较快: ...
随机推荐
- [Android 逆向]frida 破解 切水果大战原版.apk
1. 手机安装该apk,运行,点击右上角礼物 提示 支付失败,请稍后重试 2. apk拖入到jadx中,待加载完毕后,搜素失败,找到疑似目标类MymmPay的关键方法payResultFalse 4. ...
- 遭遇DDOS攻击忍气吞声?立刻报警!首都网警重拳出击,犯罪分子无所遁形
公元2024年2月24日18时许,笔者的个人网站突然遭遇不明身份者的DDOS攻击,且攻击流量已超过阿里云DDos基础防护的黑洞阈值,服务器的所有公网访问已被屏蔽,由于之前早已通过Nginx屏蔽了所有国 ...
- nuxt调用weixin-js-sdk
在nuxt中调用weixin-js-sdk与在vue中有所不同. 通常在vue中用 import wx from 'weixin-js-sdk' 调用weixin-js-sdk,但在nuxt中会出现w ...
- django学习第九天---raw查询原生sql和python脚本中调用django环境和ORM锁和事务
ORM执行原生sql语句 在模型查询api不够用的情况下,我们还可以使用原始的sql语句进行查询 方式1 raw() raw()方法,返回模型的实例django.db.models.query.Raw ...
- 矩池云上 git clone --recursive 出错,怎么解决
遇到问题 有时候安装包教程里 git clone 的时候会出现以下错误: git clone --recursive https://github.91chi.fun/https://github.c ...
- 钉钉机器人自动关联 GitHub 发送 approval prs
摘要:用技术来解决 PM 枯燥的 approval pr 工作,本文将阐述如何自动化获取 GitHub Organization 下各个 repo 待 merge 的 pull requests 并通 ...
- 如何扩展Spark Catalyst,抓取spark sql 语句,通过listenerBus发送sql event以及编写自定义的Spark SQL引擎
1.Spark Catalyst扩展点 Spark catalyst的扩展点在SPARK-18127中被引入,Spark用户可以在SQL处理的各个阶段扩展自定义实现,非常强大高效,是SparkSQL的 ...
- xml中xsd、xsi、xmlns的含义
XML是可扩展标记语言,它定义了按格式编码文件的一系列规则[3],编码的文件是机器可读和人可读的.XML文件对于机器可读是基于XSD(XML Schema Definition)[1]的.XSD是受W ...
- C语言初学习——易错点合集(长篇)
转义字符 例题一 int main() { char s[] = "012xy\08s34f4w2"; int i, n = 0; for (i = 0; s[i] != 0; i ...
- hire 聘用 受雇 租金 单词记忆
hire 基本解释 vt. 聘用:录用:雇用:租用 vi. 受雇:得到工作 n. 租金:酬金,工钱:[非正式用语] 被雇佣的人:销售部的两个新雇员 来自Proto-Germanic*hurjan,租, ...