Flink Standalone集群jobmanagers高可用配置
上篇文章简单叙述了Flink standalone集群的基础部署,在生产环境中假如只有1个jobmanager的话,那么这个节点一旦挂掉,所有运行的task都会中断,带来的影响比较大,因此在生产环境至少要保证jobmanager的高可用,至少2个节点,也可以将jobmanager和taskmanager两个实例运行到1个物理节点上,多个taskmanager和多个jobmanager并存实现高可用,高可用需要依赖zookeeper的故障恢复,因此要先准备好zookeeper集群,建议独立搭建zookeeper集群,不要用flink内置的单节点zookeeper,之前原有的环境如下:
bigdata1 - jobmanager
bigdata2,bigdata3,bigdata4 - taskmanager
目前zookeeper集群为:bigdata1,bigdata2,bigdata3,端口号为2181
接下来要进行jobmanager扩展,在bigdata4上面运行jobmanager,和bigdata1的jobmanager共同实现高可用.
首先在一个节点开始配置,这里现在bigdata1开始配置:
配置:conf/flink-conf.yaml 找到High Availability配置部分,这部分默认都是注释的也就是不使用高可用,需要手动去掉注释并且添加一些配置项,具体配置如下:
high-availability: zookeeper
high-availability.storageDir: file:///data/flink/ha
high-availability.zookeeper.quorum: bigdata1:2181,bigdata2:2181,bigdata3:2181
high-availability.zookeeper.path.root: /flink
high-availability.cluster-id: /flink_cluster
high-availability默认是NONE,表示不使用高可用,这里改成zookeeper
high-availability.storageDir 这个是高可用中用于存储一些较大的对象用于恢复,文档中建议配置所有节点都可以访问到的资源,推荐使用hdfs,这里配置的是本地文件系统,具体有效性需要验证,建议生产环境使用hdfs
high-availability.zookeeper.quorum 配置zookeeper集群
high-availability.zookeeper.path.root 配置flink在zookeeper中的path,整个集群要统一,这里是/flink;如果是多个flink集群使用同一个zookeeper集群,那么这里要区分开.
high-availability.cluster-id 集群的标识,整个集群要一致,在zookeeper下以及storageDir下都有这个cluster-id指定的目录,用于存放必须的协调数据
上面这些配置无误后,保存文件
配置masters,文件:conf/masters,添加bigdata4的节点
同时conf/slaves保持不变,仍然为bigdata2,bigdata3,bigdata4
然后将flink-conf.yaml和masters配置同步到集群其他所有节点,同时保证zookeeper服务已经正常运行
执行: bin/start-cluster.sh 启动集群,启动后会发现bigdata4多出了StandaloneSessionClusterEntrypoint进程,这个时候通过zookeeper客户端执行 get /flink/flink_cluster/leader/rest_server_lock 查看当前的jobmanager master可以一般会看到是bigdata1
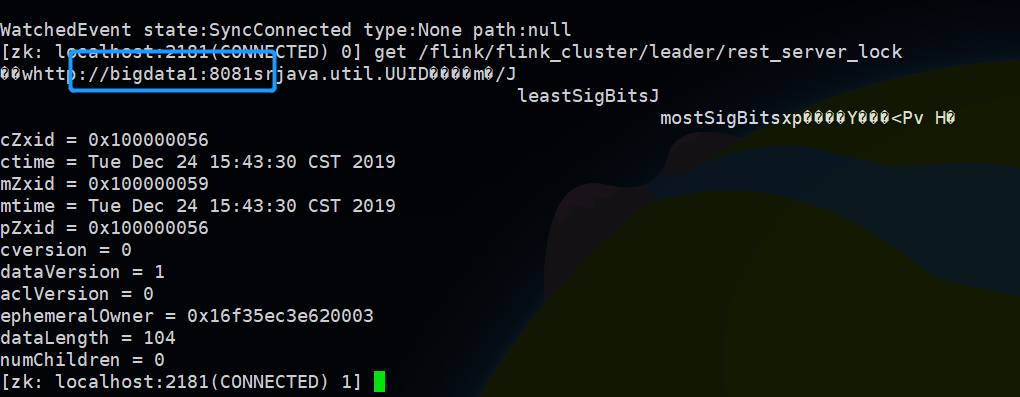
然后可以尝试将bigdata1上面的StandaloneSessionClusterEntrypoint进程kill掉,通过bigdata4:8081访问web ui,这个时候故障转移flink日志可能会报错,稍微等待一段时间,然后界面就会加载成功,正常看到slots和task managers以及详细的任务,说明这个时候jobmanager成功进行了故障转移,实现了高可用,同时查看zookeeper上面的节点也会切换成bigdata4了
另外注意配置高可用之后,之前的flink-conf.yaml中的配置项jobmanager.rpc.port就不再生效,这个配置项只针对之前的单个jobmanager的独立集群,现在这个端口会自动选择并且多个jobmanager都是不一样的,但是我们不用去关心他,对使用flink没有任何影响.
以上就是flink jobmanager高可用的配置,配置起来还是比较简单的,推荐在生产环境中使用,集群稳定性更好.
参考文档: https://ci.apache.org/projects/flink/flink-docs-release-1.9/zh/ops/jobmanager_high_availability.html
对于新版的flink有时候可能是偶然的原因导致第一次启动flink集群的时候报一些莫名其妙的错误死活启动不起来,这个时候可以尝试重启zookeeper集群,删除对应的/flink节点或者调大zookeeper tickTime,再启动flink集群一般就正常了.
Flink Standalone集群jobmanagers高可用配置的更多相关文章
- Rabbitmq安装、集群与高可用配置
历史: RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现.AMQP 的出现其实也是应了广大人民群众的需求,虽然在同步消息通讯的世界里有很多 ...
- RabbitMQ 集群与高可用配置
集群概述 通过 Erlang 的分布式特性(通过 magic cookie 认证节点)进行 RabbitMQ 集群,各 RabbitMQ 服务为对等节点,即每个节点都提供服务给客户端连接,进行消息发送 ...
- (转)RabbitMQ 集群与高可用配置
集群概述 环境 配置步骤 集群概述 通过 Erlang 的分布式特性(通过 magic cookie 认证节点)进行 RabbitMQ 集群,各 RabbitMQ 服务为对等节点,即每个节点都提供服务 ...
- RabbitMQ集群和高可用配置
概述 RabbitMQ是一个开源的AMQP实现,服务器端用Erlang语言编写,支持多种客户端,如:Python.Ruby..NET.Java.JMS.C.PHP.ActionScript.XMPP. ...
- 高可用OpenStack(Queen版)集群-3.高可用配置(pacemaker&haproxy)
参考文档: Install-guide:https://docs.openstack.org/install-guide/ OpenStack High Availability Guide:http ...
- flink初识及安装flink standalone集群
flink architecture 1.可以看出,flink可以运行在本地,也可以类似spark一样on yarn或者standalone模式(与spark standalone也很相似),此外fl ...
- 浅谈web应用的负载均衡、集群、高可用(HA)解决方案(转)
1.熟悉几个组件 1.1.apache —— 它是Apache软件基金会的一个开放源代码的跨平台的网页服务器,属于老牌的web服务器了,支持基于Ip或者域名的虚拟主机,支持代理服务器,支持安 ...
- hadoop 集群HA高可用搭建以及问题解决方案
hadoop 集群HA高可用搭建 目录大纲 1. hadoop HA原理 2. hadoop HA特点 3. Zookeeper 配置 4. 安装Hadoop集群 5. Hadoop HA配置 搭建环 ...
- Nginx+Zuul集群实现高可用网关
代码参考:https://github.com/HCJ-shadow/Zuul-Gateway-Cluster-Nginx Zuul的路由转发功能 前期准备 搭建Eureka服务注册中心 服务提供者m ...
- 11.Redis 哨兵集群实现高可用
作者:中华石杉 Redis 哨兵集群实现高可用 哨兵的介绍 sentinel,中文名是哨兵.哨兵是 redis 集群机构中非常重要的一个组件,主要有以下功能: 集群监控:负责监控 redis mast ...
随机推荐
- C++ Qt开发:QNetworkAccessManager网络接口组件
Qt 是一个跨平台C++图形界面开发库,利用Qt可以快速开发跨平台窗体应用程序,在Qt中我们可以通过拖拽的方式将不同组件放到指定的位置,实现图形化开发极大的方便了开发效率,本章将重点介绍如何运用QNe ...
- 5-事件组&任务通知
获取某个事件 获取若干事件中的某个事件 获取若干事件中的全部事件 !!!!不可获得若干事件中的几个事件 创建事件组,设置事件,等待事件 static EventGroupHandle_t xEvent ...
- python getOpenFileNames 获取文件实例解析
一 概念 选取文件夹 QFileDialog.getExistingDirectory() 选择文件 QFileDialog.getOpenFileName() 选择多个文件 QFileDialog. ...
- Handler源码解析
Handler源码解析 一.基本原理回顾 在android开发中,经常会在子线程中进行一些操作,当操作完毕后会通过handler发送一些数据给主线程,通知主线程做相应的操作. 探索其背后的原理:子线程 ...
- 修复华硕笔记本fn+f2在ubuntu下wifi不能够正常使用和WiFi Disabled (Hard-blocked) (译文)
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文发布于 2014-12-22 11:49:16 ...
- .NET Emit 入门教程:第一部分:Emit 介绍
前言: Emit 是开发者在掌握反射的使用后,进阶需要的知识,它能显著的改善因反射带来的性能影响. 目前能搜到的 Emit 的相关文章,都是一篇系列,通常推荐对照着反绎后的 IL 编写 Emit 代码 ...
- Python解压当天创建的ZIP文件到指定的文件夹中
1. 首先,导入了需要使用的模块: - `zipfile`:用于处理ZIP文件的模块. - `os`:提供了与操作系统交互的功能. - `shutil`:用于高级文件操作,例如移动文件等. - `da ...
- KingbaseES sys_restore 恢复表时默认不包括表上的索引
前言 最近碰到一个案例,在使用sys_restore恢复指定表时,默认不恢复表上的索引,如果想恢复需要单独指定. 测试过程 [](javascript:void(0) 查看表的有关属性:test=# ...
- KingbaseES V8R6在解决复制冲突中hot_standby_feedback参数的重要性
背景 如果我们看到这样的类似报错:那说明可能遇到了复制冲突. 复制冲突的理解:当备库正在应用主库传输过来的wal日志与备库正在进行的查询产生冲突就会有此报错.比如说备库正在执行基于某个表的查询,这时主 ...
- Java生成Json字符串
public class Test01 { public static void main(String[] args) { // StringBuilder responseMsg = new St ...