聊一聊 Go 的内存对齐
前言
在一次工作中,需要使用 Go 调用 DLL 文件,其中就涉及到内存对齐的相关知识,如果自定义的结构体内存布局和所调用的 DLL 结构体内存布局不一致,就会无法正确调用。所以,一旦涉及到较为底层的编程,特别是与硬件交互,内存对齐是一个必修的课题。
基础知识
在正式了解内存对齐前,我们先来看一个方法 unsafe.Sizeof(),它可以获取任意一个变量占据的内存大小,即这个变量在内存中所占据的字节数。Go 内置的变量类型占据内存大小情况如下:
| 类型 | 字节数 |
| bool | 1 |
| string | 2 * 计算机字长/8 (64位16个字节,32位8个字节) |
| int、uint、uintptr | 计算机字长/8 (64位8个字节,32位4个字节) |
| *T, map, func, chan | 计算机字长/8 (64位8个字节,32位4个字节) |
| intN, uintN, floatN, complexN | N/8个字节(int32是4个字节,float64是8个字节) |
| interface | 2 * 计算机字长/8 (64位16个字节,32位8个字节) |
| []T | 3 * 计算机字长/8 (64位24个字节,32位12个字节) |
对于切片类型而言,字节数是固定的24字节或者12字节(32位系统上),而对于数组类型而言,它的大小是元素数量 * 元素类型字节数:
var (
slice []int8
array [3]int8
)
fmt.Printf("切片:%v\n", unsafe.Sizeof(slice))
fmt.Printf("数组:%v\n", unsafe.Sizeof(array))
// 结果
切片:24
数组:3对于复合结构,也就是结构体,其情况就会变的复杂起来:
type MemStruct struct {
b bool // 1
i8 int8 // 1
i16 int16 // 2
i32 int32 // 4
}
type MemStruct2 struct {
b bool // 1
i8 int8 // 1
i32 int32 // 4
}
func TestStruct(t *testing.T) {
fmt.Println("MemStruct:", unsafe.Sizeof(MemStruct{}))
fmt.Println("MemStruct2:", unsafe.Sizeof(MemStruct2{}))
}
// 结果
MemStruct: 8
MemStruct2: 8嗯,看完代码,是不是发现了哪里不对,MemStruct 和 MemStruct2 两个结构体的 SizeOf 值居然是一样的?MemStruct 还好理解, 1 + 1 + 2 + 4 = 8 当然没问题,那 MemStruct2 是怎么回事?这个问题我们暂且按下不表, 先来看一下 CPU 是怎么访问内存的。
CPU 访问内存
CPU 访问内存时,并不是逐个字节访问,而是按照字长位单位访问,比如 32 位系统,CPU 一次性读取 4 字节,64位则一次性读取 8 字节。对于上文的 MemStruct2 结构体,假使它在内存中是这样的(实际上不是,这里是为了方便理解):
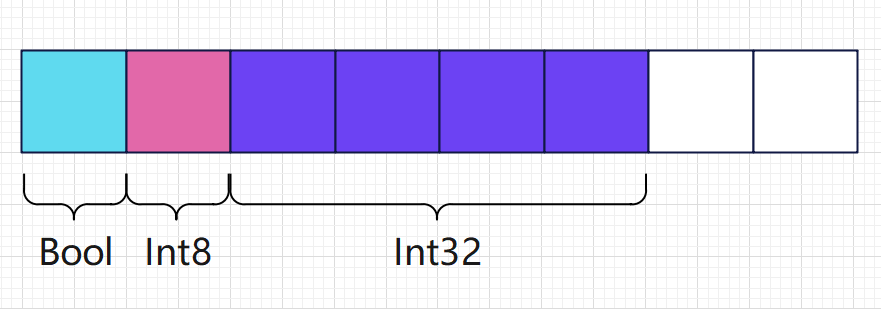
那么,此时我们以 4 字长来读取 Int32 变量,CPU 就必须要读取两次内存,然后将两次读取的结果进行整理,最终得到完整的数据:
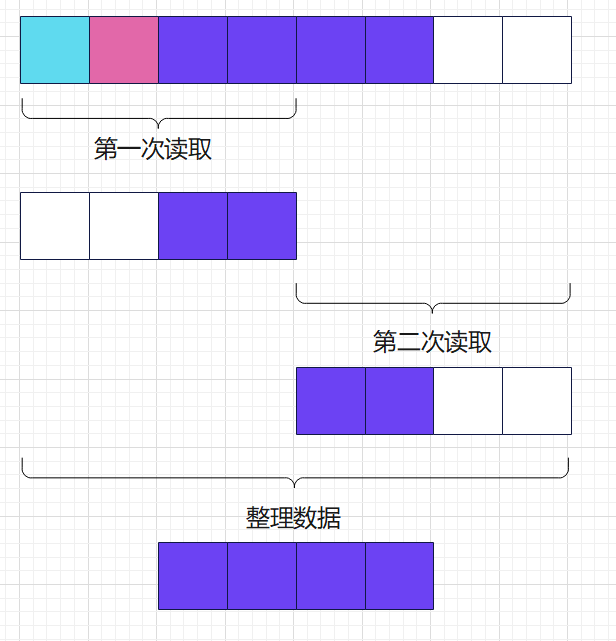
读取一个变量需要访问两次内存访问?这既不优雅也不高效,而且不利于变量操作的原子性。那么,Go 编译器是怎么解决这个问题呢,可能你也想到了,我们把结构体内存调整一下,在 Int8 之后填充两个空字节:
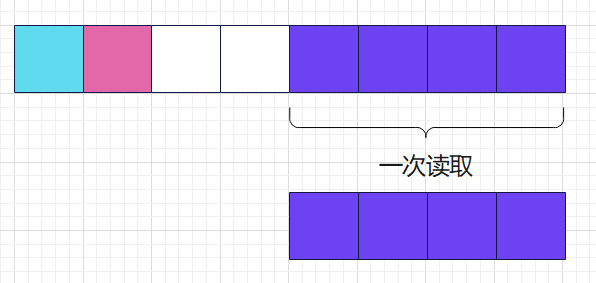
经过调整,我们就可以一次性的读取出 Int32。这种调整方式有一个响亮的名字——内存对齐。内存对齐是 Go 编译器来完成的,它对于程序员是透明的。我们的 MemStruct2 结构体之所以会多出 2 个字节,正是因为内存对齐的原因。
为什么需要内存对齐
如上文所说,内存对齐可以保障变量被 CPU 一次性的读取出来,这可以减少CPU访问内存的次数,加大CPU访问内存的吞吐量。一次性的读取变量,也保证变量的原子操作性。除此之外,有些硬件平台不支持访问任意地址的任意数据,如果不进行内存对齐,编程语言就丧失了平台可移植性。内存对齐赋予了编程语言的可移植性。
当然,内存对齐也有一些缺点:
- 因为会置空一些内存,所以会造成一定量的内存浪费;
- 会增加编译器的复杂度,编译器需要根据不同的平台和指令集来确定合适的对齐方式,并且需要处理一些特殊的情况,比如位域、联合体、指针等。
对齐保证
unsafe.Alignof(x) 返回一个类型的对齐系数,对于 Go 的基础类型来说,这个值会取 计算机字长/8 和 unsafe.Sizeof(x) 中较小的一个值。即 min(计算机字长/8,unsafe.Sizeof(x)):
func TestAlignOf(t *testing.T) {
var (
s string
i8 int8
)
fmt.Printf("string sizeof:%v, alignof: %v\n", unsafe.Sizeof(s), unsafe.Alignof(s)) // min(8, 1) = 1
fmt.Printf("int8 sizeof:%v, alignof: %v\n", unsafe.Sizeof(i8), unsafe.Alignof(i8)) // min(8, 16) = 16
}对于 64 位操作系统来说,计算机字长64/8 = 8。int8 的 SizeOf 是 1,与 8 对比较小,所以 int8 的对齐系数就是1;string 的 SizeOf 是16,与 8 相比较大,所以 string 的对齐系数就是 8。
对于数组和结构体类型来说,情况则有些特殊。在 The Go Programming Language Specification 一文中提到了三点,其中后两点说的就是结构体和数组:
- For a variable x of any type: unsafe.Alignof(x) is at least 1.
- For a variable x of struct type: unsafe.Alignof(x) is the largest of all the values unsafe.Alignof(x.f) for each field f of x, but at least 1.
- For a variable x of array type: unsafe.Alignof(x) is the same as the alignment of a variable of the array's element type.
这段话翻译过来就是:
- 对于任意类型的变量 x ,unsafe.Alignof(x) 至少为 1;
- 对于 struct 结构体类型的变量 x,计算 x 每一个字段 f 的 unsafe.Alignof(x.f),unsafe.Alignof(x) 等于其中的最大值;
- 对于 array 数组类型的变量 x,unsafe.Alignof(x) 等于构成数组的元素类型的对齐倍数。
第一点容易理解,没有哪个类型对齐系数会小于1的,不然那不就乱套了吗。第二点的意思就是说对于任意结构体而言,它的对齐系数会等于它所包含字段中对齐系数最大的那一个:
type MemStruct struct {
b bool // alignof: 1
i8 int8 // alignof: 1
i32 int32 // alignof: 4
s string // alignof: 8
}
func TestStruct(t *testing.T) {
fmt.Printf("MemStruct的对齐系数:{%v}, 等于string的对齐系数:{%v}", unsafe.Alignof(MemStruct{}), unsafe.Alignof(string("1")))
}
// 结果
MemStruct的对齐系数:{8}, 等于string的对齐系数:{8}第三点就是说对于数组类型而言,它的对齐系数等于它构成元素类型的对齐系数:
func TestArray(t *testing.T) {
var (
it interface{}
arr [3]interface{}
)
fmt.Printf("数组interface{}的对齐系数:{%v}, 等于interface的对齐系数:{%v}", unsafe.Alignof(arr), unsafe.Alignof(it))
}
// 结果
数组interface{}的对齐系数:{8}, 等于interface的对齐系数:{8}以上两个例子的基于 64 位操作系统。
结构体对齐技巧
合理的布局可以减少内存浪费,假使我们现在有一个结构体有 int8、int16、int32 三个字段,那么这三个字段在结构体的顺序会影响结构体的内存占用吗?我们来看一个例子:
type S1 struct {
i8 int8
i16 int16
i32 int32
}
type S2 struct {
i8 int8
i32 int32
i16 int16
}
func TestLeastMem(t *testing.T) {
fmt.Printf("S1的占用: %v\n", unsafe.Sizeof(S1{}))
fmt.Printf("S2的占用: %v\n", unsafe.Sizeof(S2{}))
}
// 结果
S1的占用: 8
S2的占用: 12可以看到,S1 明显占用的内存更少。让我们来分析一下,S1 和 S2 的对齐系数都等于其子字段 int16 的对齐系数,也就是 4。对于S1,经过内存对齐,它们在内存中的布局是这样的:
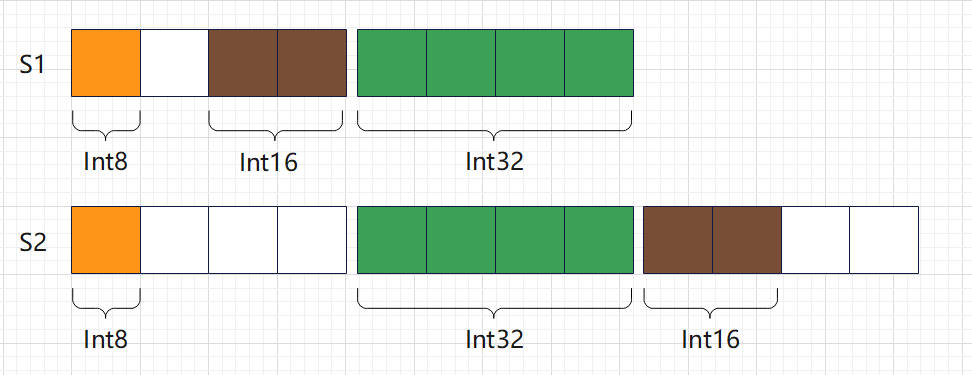
对于 S1:
- i8 是第一个字段,默认已经对齐,从 0 开始占据 1 个字节;
- i16 是第二个字段,对齐系数为 2,因此,必须填充 1 个字节,其偏移量才是 2 的倍数,从 2 开始占据 2 字节;
- i32 是第三个字段,对齐系数为 4,此时,内存已经是对齐的,从第 4 开始占据 4 字节即可;
因此 S1 在内存占用了 8 个字节,浪费了 1 个字节。
对于 S2:
- i8 是第一个字段,默认已经对齐,从 0 开始占据 1 个字节;
- i32 是第二个字段,对齐系数为 4,因此,必须填充 3 个字节,其偏移量才是 4 的倍数,从第 4 开始占据 4 字节;
- i16 是第三个字段,对齐系数为 2,此时,内存已经是对齐的,从第 8 开始占据 2 字节即可。
因此 S2 在内存占用了 12 个字节,浪费了 5 个字节。
空结构体对齐保证
对于空结构体,其 Sizeof 为0,Alignof 是 1,一般其作为其他结构体字段时,不需要内存对齐,但有一种情况除外:在结构体末尾。为什么呢?我们先要知道一件事情:因为空结构体的 Size 为0,所以编译器会把 zerobase 的地址分配出去,这体现在 src/runtime/malloc.go 878 行中(Go 1.20.4):
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
...
if size == 0 {
return unsafe.Pointer(&zerobase)
}
...
}zerobase 是 Go 定义的一个 uintptr 的特殊全局变量,占据 8 个字节。因为所有空接口体的地址都指向 zerobase,所以所有空结构体的内存地址都是一样的!这样做就可以使所有的空结构体有一个独一无二的内存地址,不与 nil 混淆,而且多个空结构体不会占用额外的内存。空结构体有内存地址却不占用内存,这个概念很重要!
有了这个概念,我们就比较容易理解为什么空结构体在末尾需要内存对齐了。当空结构体类型作为结构体的最后一个字段时,如果有指向该字段的指针,那么就会返回该结构体之外的地址,导致内存泄露。为了避免这种情况就需要进行一次内存对齐,且内存占用大小和前一个变量的大小保持一致:
type emptyStruct struct{}
type S1 struct {
empty emptyStruct
i8 int8
}
type S2 struct {
i8 int8
empty emptyStruct
}
type S3 struct {
i16 int16
empty emptyStruct
}
type S4 struct {
i16 int16
i8 int8
empty emptyStruct
}
func TestSpaceStructMem(t *testing.T) {
fmt.Printf("S1的占用: %v\n", unsafe.Sizeof(S1{}))
fmt.Printf("S2的占用: %v\n", unsafe.Sizeof(S2{}))
fmt.Printf("S3的占用: %v\n", unsafe.Sizeof(S3{}))
fmt.Printf("S4的占用: %v\n", unsafe.Sizeof(S4{}))
// S3 空结构从第二位开始,往后补充两个字节
fmt.Printf("S3的空结构体偏移量: %v\n", unsafe.Offsetof(S3{}.empty))
// S4 空结构从第三位开始,往后补充一个字节
fmt.Printf("S4的空结构体偏移量: %v\n", unsafe.Offsetof(S4{}.empty))
}
// 结果
S1的占用: 1
S2的占用: 2
S3的占用: 4
S4的占用: 4
S3的空结构体偏移量: 2
S4的空结构体偏移量: 3聊一聊 Go 的内存对齐的更多相关文章
- C++内存对齐总结
大家都知道,C++空类的内存大小为1字节,为了保证其对象拥有彼此独立的内存地址.非空类的大小与类中非静态成员变量和虚函数表的多少有关. 而值得注意的是,类中非静态成员变量的大小与编译器内存对齐的设置有 ...
- C/C++: C++位域和内存对齐问题
1. 位域: 1. 在C中,位域可以写成这样(注:位域的数据类型一律用无符号的,纪律性). struct bitmap { unsigned a : ; unsigned b : ; unsigned ...
- C/C++ 知识点1:内存对齐
预备知识:基本类型占用字节 在32位操作系统和64位操作系统上,基本数据类型分别占多少字节呢? 32位操作系统: char : 1 int :4 short : 2 unsigned ...
- Windows+GCC下内存对齐的常见问题
结构/类对齐的声明方式 gcc和windows对于modifier/attribute的支持其实是差不多的.比如在gcc的例子中,内存对齐要写成: class X { //... } __attrib ...
- c++内存对齐
内存对齐原则: 1.数据成员对齐规则:struct, union的数据成员,第一个数据成员放在offset为0的地方,之后的数据成员的存储起始位置都是放在该数据成员大小的整数倍位置.如在32bit的机 ...
- C语言中内存对齐
今天一考研同学问我一个问题,一个结构体有一个int类型成员和一个char类型成员,问我这个结构体类型占多少个字节,我直接编个程序给他看结果.这个结构体占八个字节,咦,当时我蛮纳闷的,一个int类型四个 ...
- 内存对齐 和 sizeof小结
数据对齐(内存对齐)指该数据所在的地址必须是该数据长度的整数倍.X86CPU能直接访问对齐的数据,当它试图访问未对齐的数据时,会在内部进行一系列的调整,降低运行速度.数据对齐一般出现在结构体和类中,在 ...
- 解析C语言结构体对齐(内存对齐问题)
C语言结构体对齐也是老生常谈的话题了.基本上是面试题的必考题.内容虽然很基础,但一不小心就会弄错.写出一个struct,然后sizeof,你会不会经常对结果感到奇怪?sizeof的结果往往都比你声明的 ...
- C语言再学习之内存对齐
昨天看Q3的代码,看到有个_INTSAIZEOF的宏,着实晕了一阵.一番google后,终于明白,这个宏的作用是求出变量占用内存空间的大小,先看看_INTSAIZEOF的定义吧: #define _I ...
- C结构体中数据的内存对齐问题
转自:http://www.cnblogs.com/qwcbeyond/archive/2012/05/08/2490897.html 32位机一般默认4字节对齐(32位机机器字长4字节),64位机一 ...
随机推荐
- docker安装带postgis插件的postgresql 数据库
最初直接拉取的postgresql 数据,在导入 .bakup 文件时始终会报错,最后才想到该数据库默认不带postgis空间组件 一.拉取镜像 这里我们拉取postgres 和 gis 组合的镜像 ...
- 在vue 项目中嵌入jsp页面
今日一个项目中一块功能模块是其他系统使用jsp已经开发好的页面,想着直接将其嵌入到当前的vue项目中节约开发成本:但是发现并非想象的那么简单 创建一个server.vue组件加载jsp页面 1 .第一 ...
- U3DFrameWorkDemo:二、资源管理
代码参考 代码文件参考下述详解的类图,工程参考第零章工程说明 概述 在游戏项目中有很多资产如:预制体,图片,音频,Lua脚本,Shader等等.他们随打包放在用户的硬盘里.在游戏的运行过程中,需要对这 ...
- 500行代码手写docker-实现硬件资源限制cgroups
(5)500行代码手写docker-实现硬件资源限制cgroups 本系列教程主要是为了弄清楚容器化的原理,纸上得来终觉浅,绝知此事要躬行,理论始终不及动手实践来的深刻,所以这个系列会用go语言实现一 ...
- 一个.Net强大的Excel控件,支持WinForm、WPF、Android【强烈推荐】
推荐一个强大的电子表单控件,使用简单且功能强大. 项目简介 这是一个开源的表格控制组件,支持Winform.WPF和Android平台,可以方便的加载.修改和导出Excel文件,支持数据格式.大纲.公 ...
- 新风向标:学术界开始从 Python 转向 Rust
作者 | Jeffrey M. Perkel 策划 | Tina 来源 | Rust语言中文社区 Rust 现在已经越来越受到科学家们的欢迎了,比起 Python,Rust 有着更高效的性能,同时在社 ...
- 深入理解注解驱动配置与XML配置的融合与区别
摘要:本文旨在深入探讨Spring框架的注解驱动配置与XML配置,揭示两者之间的相似性与差异. 本文分享自华为云社区<Spring高手之路2--深入理解注解驱动配置与XML配置的融合与区别> ...
- 【技术积累】Python中的NumPy库【一】
NumPy库是什么 NumPy是Python科学计算的核心库之一,用来进行科学计算,数值分析等矩阵运算.主要提供了以下几种功能: 1.多维数组(ndarray)对象,可以进行快速的数值计算和数组操作: ...
- 【whale-starry-stl】01天 list学习笔记
一.知识点 1. std::bidirectional_iterator_tag std::bidirectional_iterator_tag 是 C++ 标准库中定义的一个迭代器类型标签,用于标识 ...
- 前端Vue自定义导航栏菜单 定制左侧导航菜单按钮 中部logo图标 右侧导航菜单按钮
前端Vue自定义导航栏菜单 定制左侧导航菜单按钮 中部logo图标 右侧导航菜单按钮, 下载完整代码请访问uni-app插件市场地址:https://ext.dcloud.net.cn/plugin? ...