ICLR 2024 | Mol-Instructions: 面向大模型的大规模生物分子指令数据集
发表会议:ICLR 2024论文标题:Mol-Instructions: A Large-Scale Biomolecular Instruction Dataset for Large Language Models论文链接:https://arxiv.org/pdf/2306.08018.pdf代码链接:https://github.com/zjunlp/Mol-Instructions
在自然语言处理(NLP)的众多应用场景中,大型语言模型(Large Language Model, LLM)展现了其卓越的文本理解与生成能力,不仅在传统的文本任务上成绩斐然,更在生物学、计算化学、药物研发等跨学科领域证明了其广泛的应用潜力。尽管如此,生物分子研究领域的特殊性—比如专用数据集的缺乏、数据标注的高复杂度、知识的多元化以及表示方式的不统一—仍旧是当前面临的关键挑战。针对这些问题,本文提出Mol-Instructions,这是一个针对生物分子领域各项研究任务定制的指令数据集。
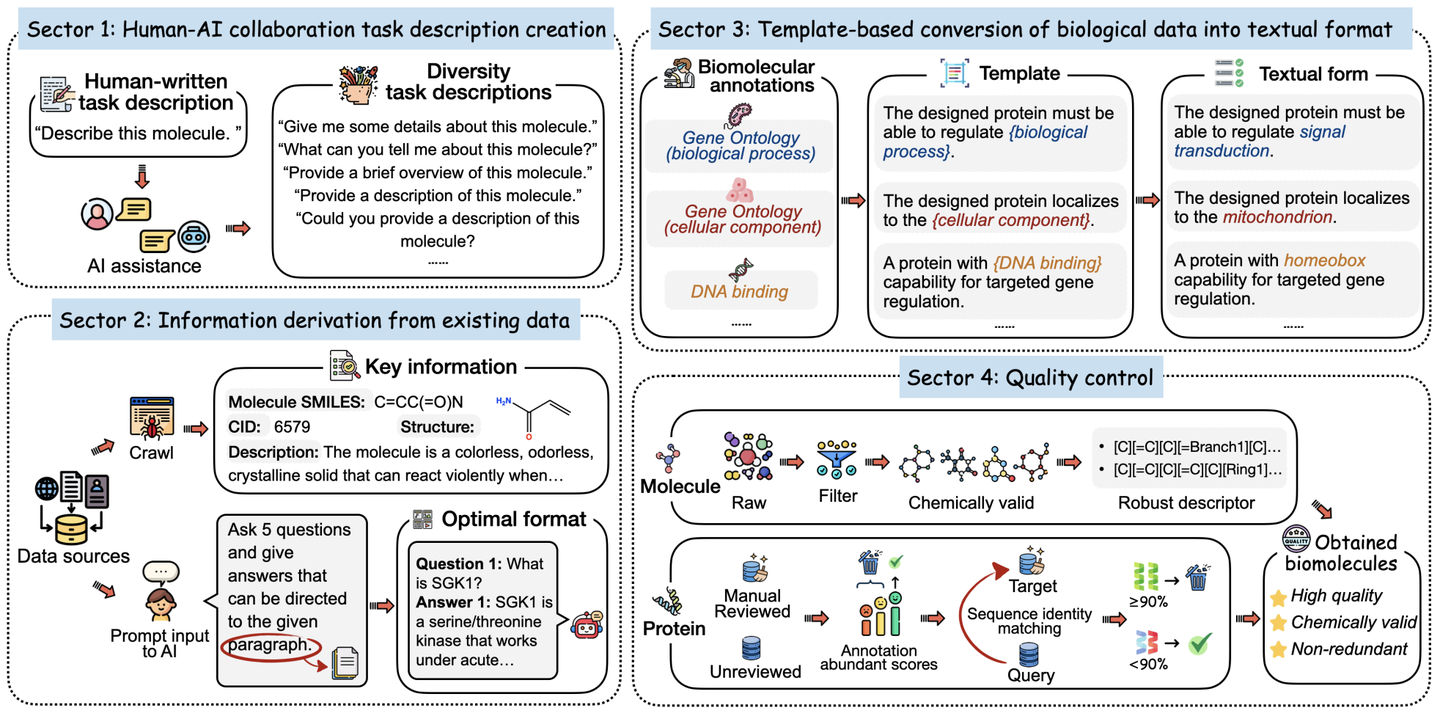
- 借助LLM的能力,生成多样化的任务描述,模拟人类需求和表达的多样性。
- 采用多种预处理策略,将现有数据库中的数据转化为可用的指令数据。
- 利用模版将结构化的功能注释转换为易于理解的文本。
- 对小分子和蛋白质序列进行严格的质量控制,以排除化学无效和冗余的序列。

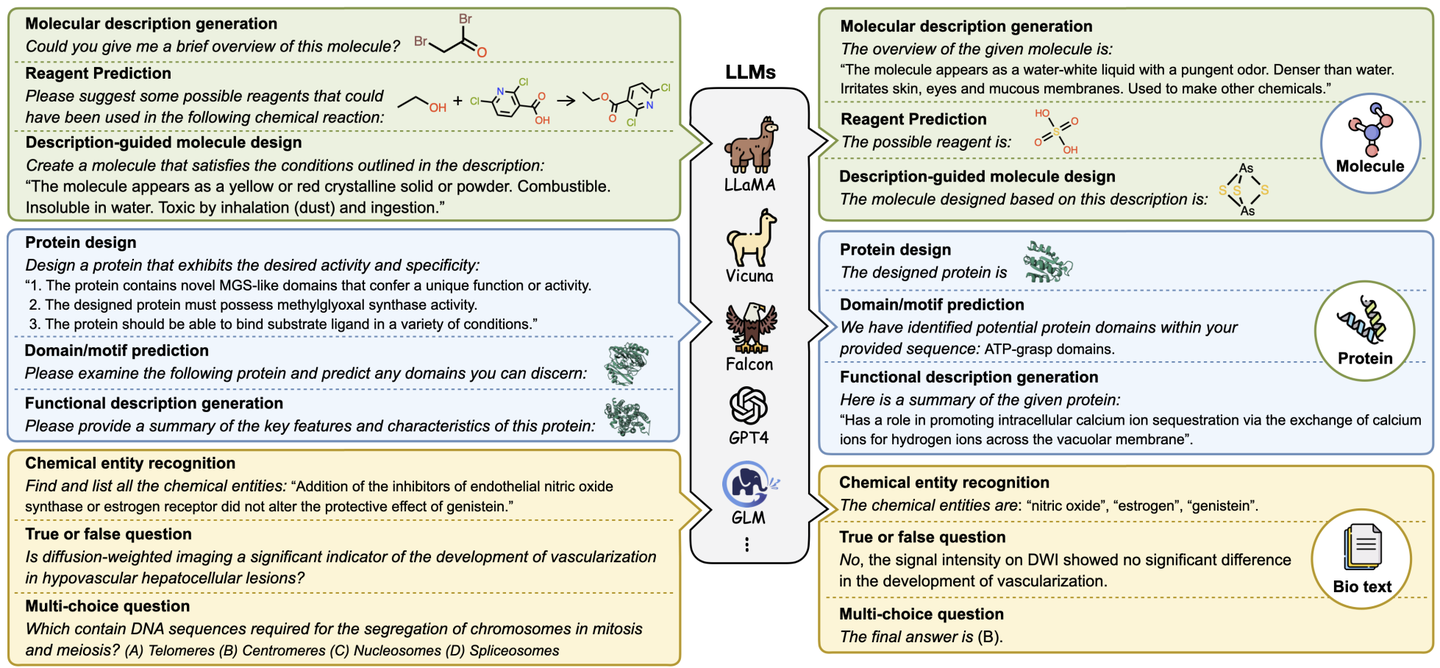
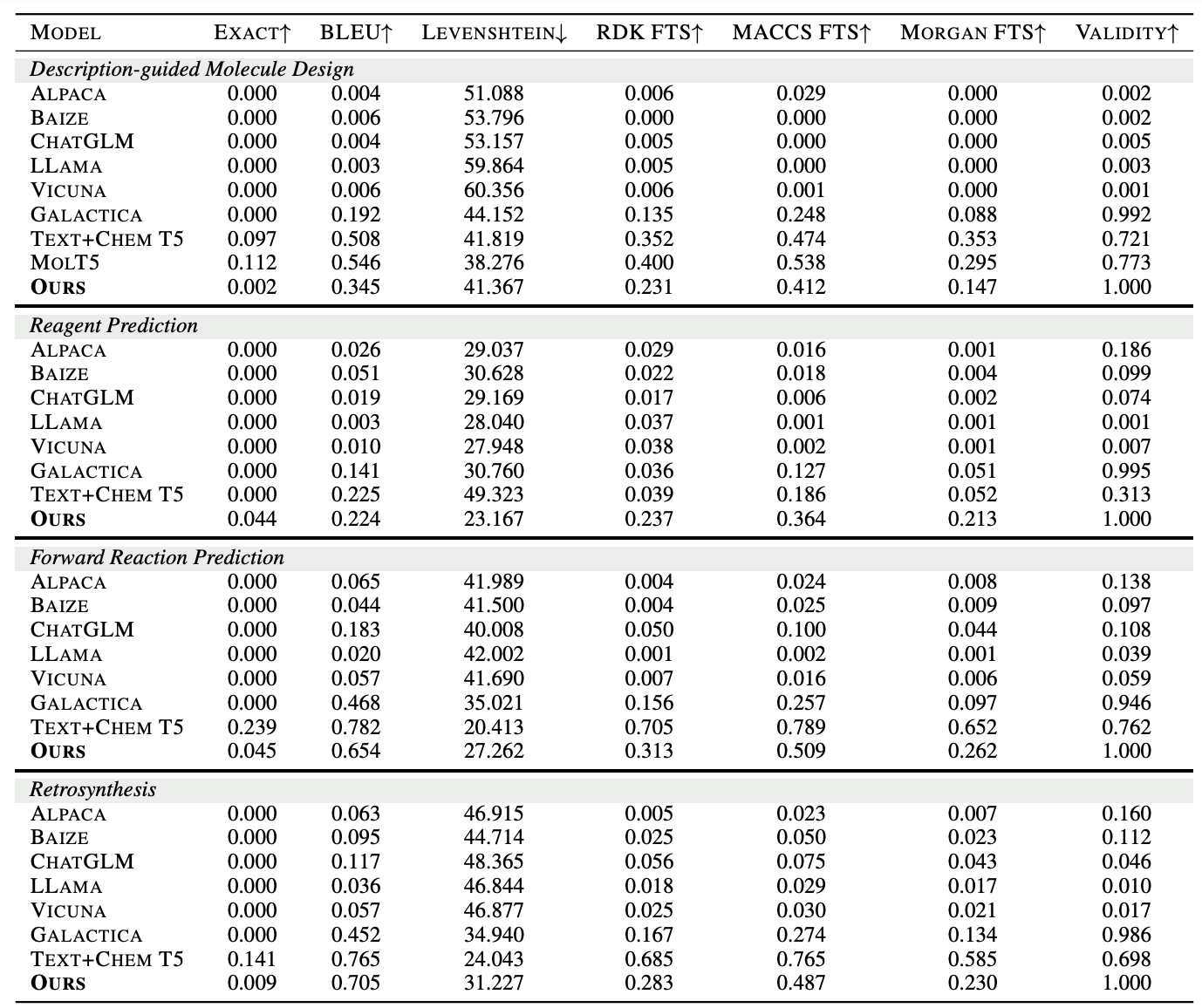
- 小分子指令:深度探索小分子的固有属性与行为,研究化学反应和分子设计的核心挑战。理解和预测小分子的化学特性,优化分子设计,提高化学反应预测的准确性和效率。其目标是在化学和药物设计领域加速药物的研发进程,同时降低研发成本。
- 蛋白质指令:主要解决蛋白质设计和功能相关的问题。旨在预测蛋白质结构域、功能及活性,通过文本指令推动蛋白质设计。对于疾病的诊断、治疗以及新药的研发工作具有一定的价值。
- 生物文本指令:侧重于生物信息学和化学信息学领域的自然语言处理任务。旨在从生物医学文献中提取和解析关键信息,支持研究人员快速获取知识、便于进行查询。
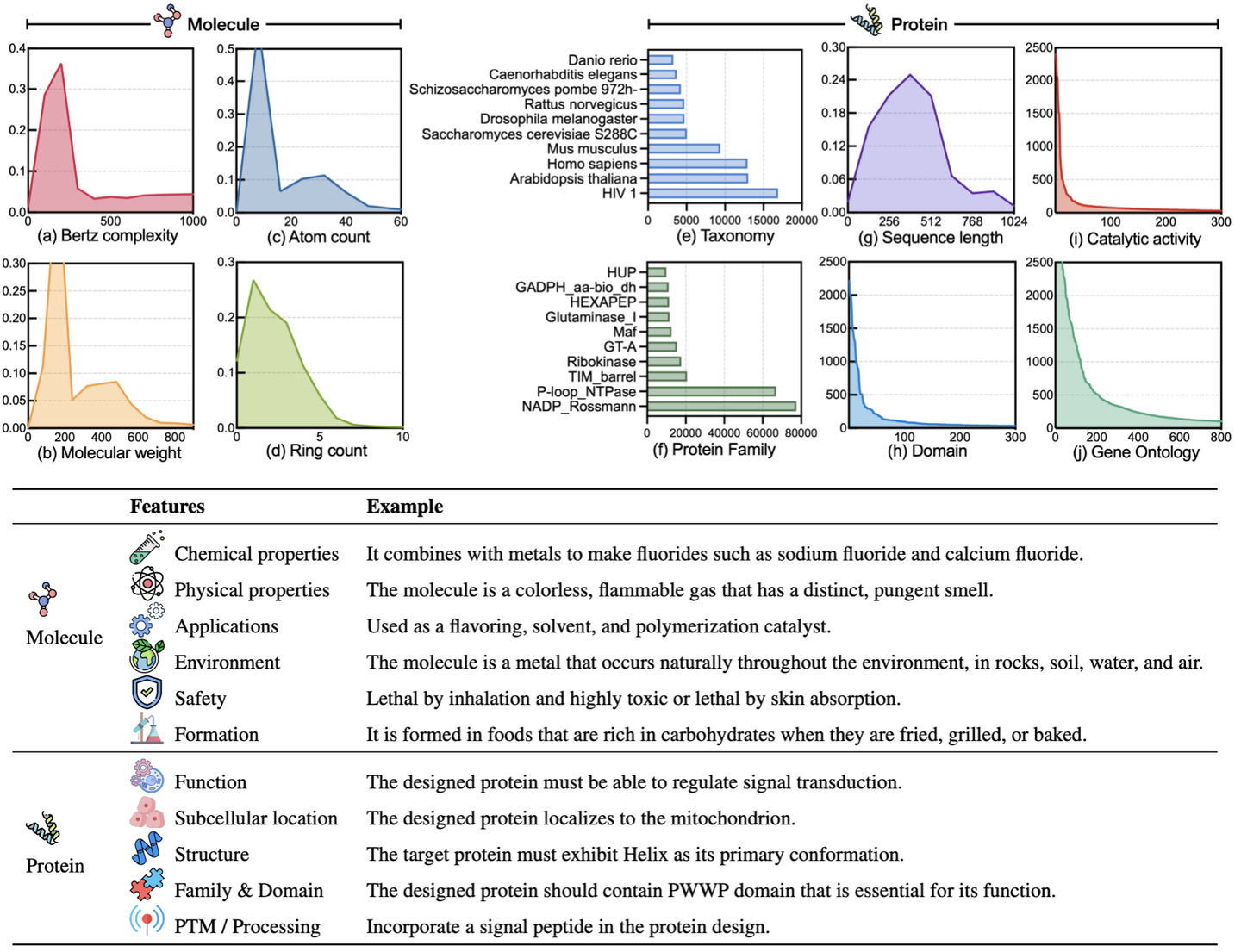
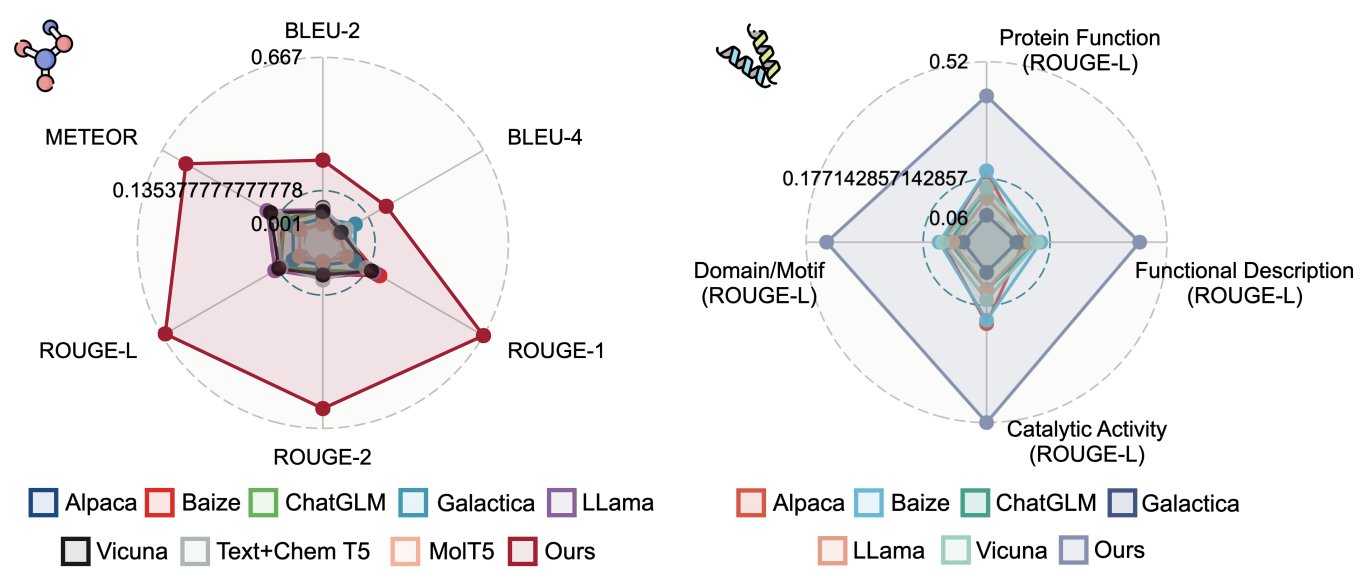
- 图(a-d)揭示了分子的多维特征。Bertz复杂度是评估分子复杂度的关键指标。分子量反映了分子的大小和复杂性,对众多化学反应具有决定性影响。原子计数揭示了分子的规模和复杂度,进而影响其稳定性和反应性。环计数则提供了结构复杂度和潜在稳定性的视角,对理解化学反应性和生物活性潜力至关重要。图(e-j)探究了蛋白质的特性。图(e-g)体现了蛋白质序列长度的不同分布。根据NCBI分类,这些蛋白质覆盖了丰富的物种和实验菌株,包括13,563个蛋白质家族和643个超家族。图(h-j)关注功能特征,如结构域、基因本体和催化活性的注释。这些数据表现出显著的长尾分布,凸显了推断特定蛋白质功能的挑战,尤其是那些罕见功能的蛋白质。
- 如表格所示,分子设计和蛋白质设计的文本描述提供了多维度的视角,涵盖从基本属性到特定应用场景的广泛特性。

ICLR 2024 | Mol-Instructions: 面向大模型的大规模生物分子指令数据集的更多相关文章
- PowerDesigner 学习:十大模型及五大分类
个人认为PowerDesigner 最大的特点和优势就是1)提供了一整套的解决方案,面向了不同的人员提供不同的模型工具,比如有针对企业架构师的模型,有针对需求分析师的模型,有针对系统分析师和软件架构师 ...
- PowerDesigner 15学习笔记:十大模型及五大分类
个人认为PowerDesigner 最大的特点和优势就是1)提供了一整套的解决方案,面向了不同的人员提供不同的模型工具,比如有针对企业架构师的模型,有针对需求分析师的模型,有针对系统分析师和软件架构师 ...
- 华为高级研究员谢凌曦:下一代AI将走向何方?盘古大模型探路之旅
摘要:为了更深入理解千亿参数的盘古大模型,华为云社区采访到了华为云EI盘古团队高级研究员谢凌曦.谢博士以非常通俗的方式为我们娓娓道来了盘古大模型研发的"前世今生",以及它背后的艰难 ...
- 无插件的大模型浏览器Autodesk Viewer开发培训-武汉-2014年8月28日 9:00 – 12:00
武汉附近的同学们有福了,这是全球第一次关于Autodesk viewer的教室培训. :) 你可能已经在各种场合听过或看过Autodesk最新推出的大模型浏览器,这是无需插件的浏览器模型,支持几十种数 ...
- 文心大模型api使用
文心大模型api使用 首先,我们要获取硅谷社区的连个key 复制两个api备用 获取Access Token 获取access_token示例代码 之后就会输出 作文创作 作文创作:作文创作接口基于文 ...
- AI大模型学习了解
# 百度文心 上线时间:2019年3月 官方介绍:https://wenxin.baidu.com/ 发布地点: 参考资料: 2600亿!全球最大中文单体模型鹏城-百度·文心发布 # 华为盘古 上线时 ...
- 千亿参数开源大模型 BLOOM 背后的技术
假设你现在有了数据,也搞到了预算,一切就绪,准备开始训练一个大模型,一显身手了,"一朝看尽长安花"似乎近在眼前 -- 且慢!训练可不仅仅像这两个字的发音那么简单,看看 BLOOM ...
- DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍
DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍 1. 概述 近日来,ChatGPT及类似模型引发了人工智能(AI)领域的一场风潮. 这场风潮对数字世 ...
- 图神经网络之预训练大模型结合:ERNIESage在链接预测任务应用
1.ERNIESage运行实例介绍(1.8x版本) 本项目原链接:https://aistudio.baidu.com/aistudio/projectdetail/5097085?contribut ...
- ILLA Cloud: 调用 Hugging Face Inference Endpoints,开启大模型世界之门
一个月前,我们 宣布了与 ILLA Cloud 与达成的合作,ILLA Cloud 正式支持集成 Hugging Face Hub 上的 AI 模型库和其他相关功能. 今天,我们为大家带来 ILLA ...
随机推荐
- 一篇文章教你从入门到精通 Google 指纹验证功能
本文首发于 vivo互联网技术 微信公众号 链接:https://mp.weixin.qq.com/s/EHomjBy4Tvm8u962J6ZgsA作者:Sun Daxiang Google 从 An ...
- nginx安装 没有网络且缺少基础包的环境下
一.安装 [root@oracle ~]# cd /etc/yum.repos.d/ [root@oracle yum.repos.d]# rm -rf * [root@oracle yum.repo ...
- P2196-DP【黄】
清醒了一点后我又写了一道黄色DP题,做出来了,还行,开心不少了... 中途暴露出一些问题 1.深搜过程中既然用了二维数组,那么深搜时就应该用二维循环取最优解,而不是只从最后一行中进行一维循环取最优解. ...
- 如何使用Markdown编写笔记
Markdown是什么? Markdown 是一种轻量级标记语言,创始人为约翰·格鲁伯(John Gruber). 它允许人们使用易读易写的纯文本格式编写文档,然后转换成有效的 XHTML(或者HTM ...
- java 文件上传 :MultipartFile 类型转换为file类型
通过前台进行文件上传并保存服务器. 1.从前台解析得到的文件类型为 MultipartFile 类型,在进行解析的时候,我们需要将 MultipartFile 类型转换为file类型,然后将文件上传到 ...
- 码农的转型之路-IoTBrowser(物联网浏览器)雏形上线
消失了半个月闭门造轮子去了,最近干了几件大事: 1.工控盒子,win10系统长时间跑物联网服务测试.运行快2周了,稳定性效果还满意,除了windows自动更新重启了一次. 2 .接触了一些新概念MQT ...
- [转帖]容器环境的JVM内存设置最佳实践
https://cloud.tencent.com/developer/article/1585288 Docker和K8S的兴起,很多服务已经运行在容器环境,对于java程序,JVM设置是一个重要的 ...
- [转帖]【SOP】最佳实践之 TiDB 业务写变慢分析
https://zhuanlan.zhihu.com/p/647831844 前言 在日常业务使用或运维管理 TiDB 的过程中,每个开发人员或数据库管理员都或多或少遇到过 SQL 变慢的问题.这类问 ...
- [转帖]金仓数据库KWR使用说明
金仓数据库KWR使用说明 1.KWR性能报告介绍 2.部署KWR性能报告功能 2.1.修改配置文件 2.2.使配置文件中参数生效 2.3.创建KWR扩展 3.使用KWR快照功能 3.1.创建KWR快照 ...
- 【转帖】bpftrace 指南
文章目录 0. bpftrace 0.1 bpftrace组件 0.2 bpftrace 帮助信息 0.3 bpftrace 工具速览表 0.4 bpftrace 探针 0.4.1 tracepoin ...