可视化技术在 Nebula Graph 中的应用

本文整理自 #可视化 on Live 主题直播,在本期直播中 3 位可视化嘉宾讲述了他们眼中的可视化,以及他们在可视化项目实践中踩过的那些“坑”。
- 卢晓龙:可视化图探索工具 Nebula Explorer 产品负责人,可视化技术专家;
- 苗壮:可视化图探索工具 Nebula Explorer 核心开发,可视化技术专家;
- 汪洋:可视化监控运维工具 Nebula Dashboard 产品负责人,可视化技术专家;
可视化是什么?
从个人理解来说的话,可视化便是将我们平时看到的某些数据或者文字这些相对抽象的东西用合理的方式,比如:图标或者图表,进行二次展示,更方便用户进行交互。简单来说,网页上常见的按钮、图标,比如输入:https://www.baidu.com/ 之后标蓝的“百度一下”按钮,右下角的辅助功能图标,都是一种简单、基础的可视化展示。如果没有这些小图标,你可能需要调用终端执行某条命令才能方便地完成对应操作。而可视化则能大大地降低操作成本以及更容易让用户理解对应操作。
上面的例子,我们讲到的是 UI 可视化。提到 UI,我们来读取下十几年前的记忆。大家知道早年间,电脑技术还不发达,大家看的都是命令行。而现在的话,为什么计算机能飞入寻常百姓家呢?就是因为计算机或者说电脑有了界面,有了 UI,有了符合人直觉的东西。所以说,能提升效率的视觉东西就叫做可视化。如果要给一个定义的话,可视化大概有两点:
上段例子和 GUI,此类可视化人人可见,但在我看来并非体现可视化的最大亮点;
设计,或者是美术,这是可视化的灵魂。 因为有了这个东西,它会给可视化赋予生命的意义。通俗来说,一个东西好不好用,往往不是你能把它做出来它就是好用的;但如果它的交互好、体验好、视觉效果好,能符合人的直觉,挖掘出来一些信息,这便算是一个好的可视化。所以说,我认为可视化还是要两部分,一部分是物理意义上的,即第一部分说的渲染,第二部分的话就是它的设计体验,这涉及了软硬件。
其实,可以把可视化这个概念分为广义和狭义两个维度来看。
广义的可视化,可以理解为把一个复杂的信息通过一定的处理,让这个信息更简单、直观呈现在用户眼前,让用户更方便地去接受一些信息。这便属于可视化范畴,像 GUI,其实它就是一种可视化,把底层的命令通过一种可视化的方式抽象出来,让用户可以更方便的和机器做交互。
而狭义来说,也就是针对的场景的应用。比如说,伴随着互联网的发展,我们应对的数据量会越来越大,我们要把这些数据通过一定的方式呈现出来,呈现的效果越好,数据表达也就越好越能被理解。如何在当前硬件存在一定性能瓶颈的基础上,更流畅地展示更多的数据,可能是当前可视化的意义所在。这么来看,可视化在狭义的角度上来看,它可能就是图表、Canvas 动画,或是元宇宙兴起的 VR 技术、浏览器渲染、3D 渲染,这些可视化可研究的方向。
具体来说,因为 Nebula 是一款分布式图数据库,我们提到的可视化更多的是数据可视化。比如,Nebula Dashboard 是一款可视化运维监控产品,在这块的可视化实践不只是图标、动画,更多的是如何把复杂的运维信息通过简单的方式,让用户更容易地 Control 集群。
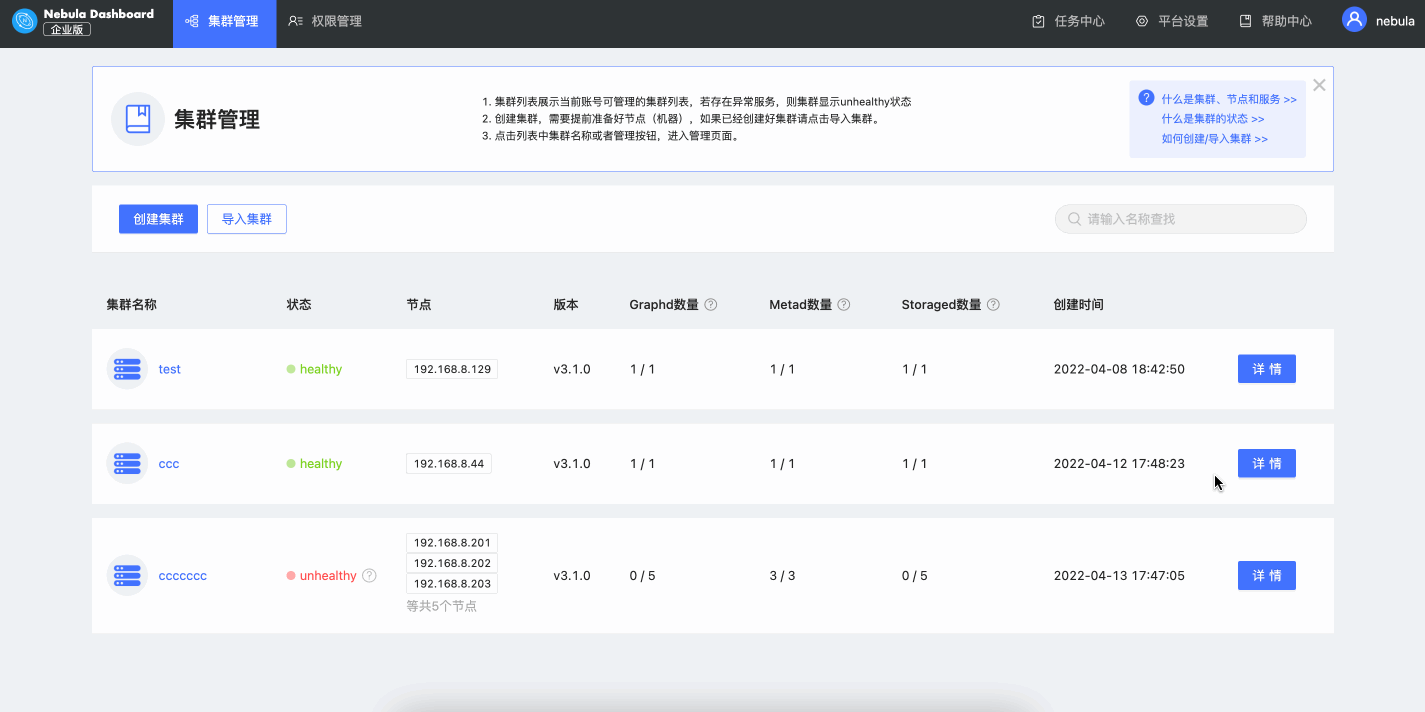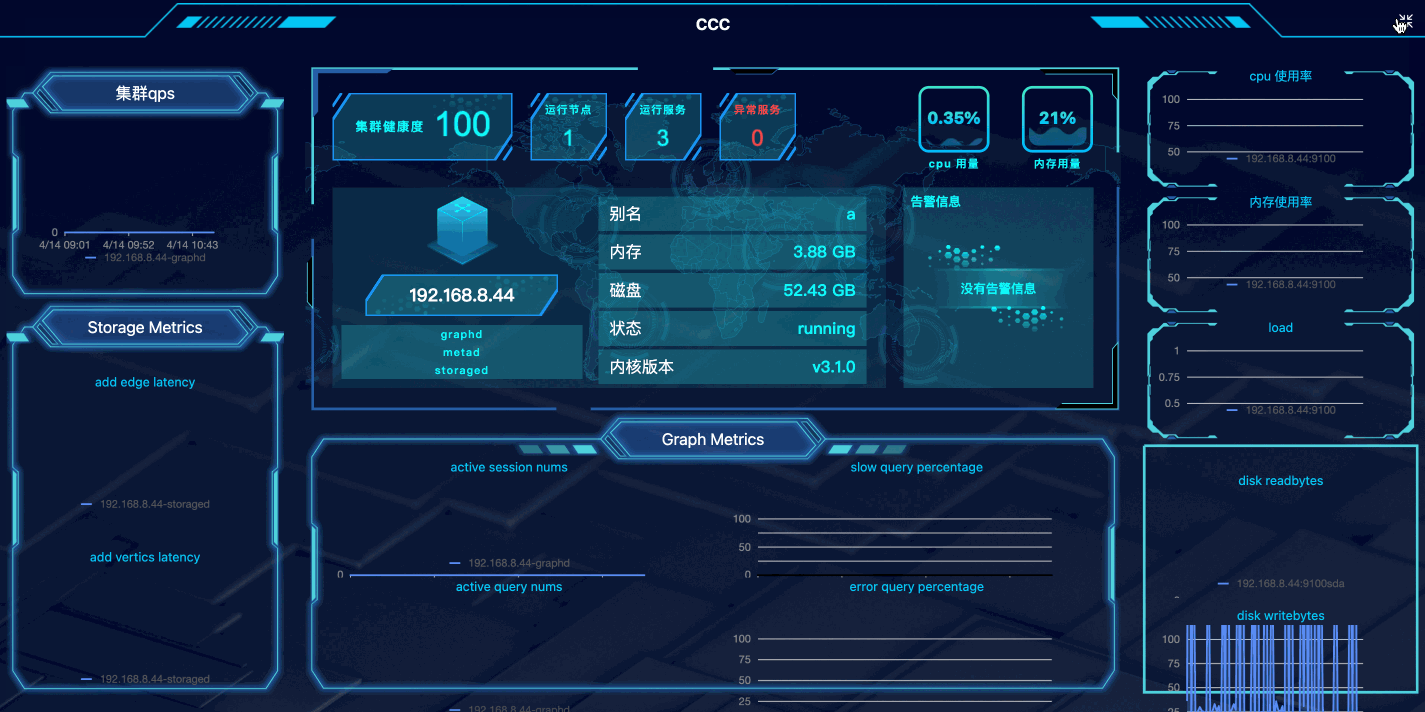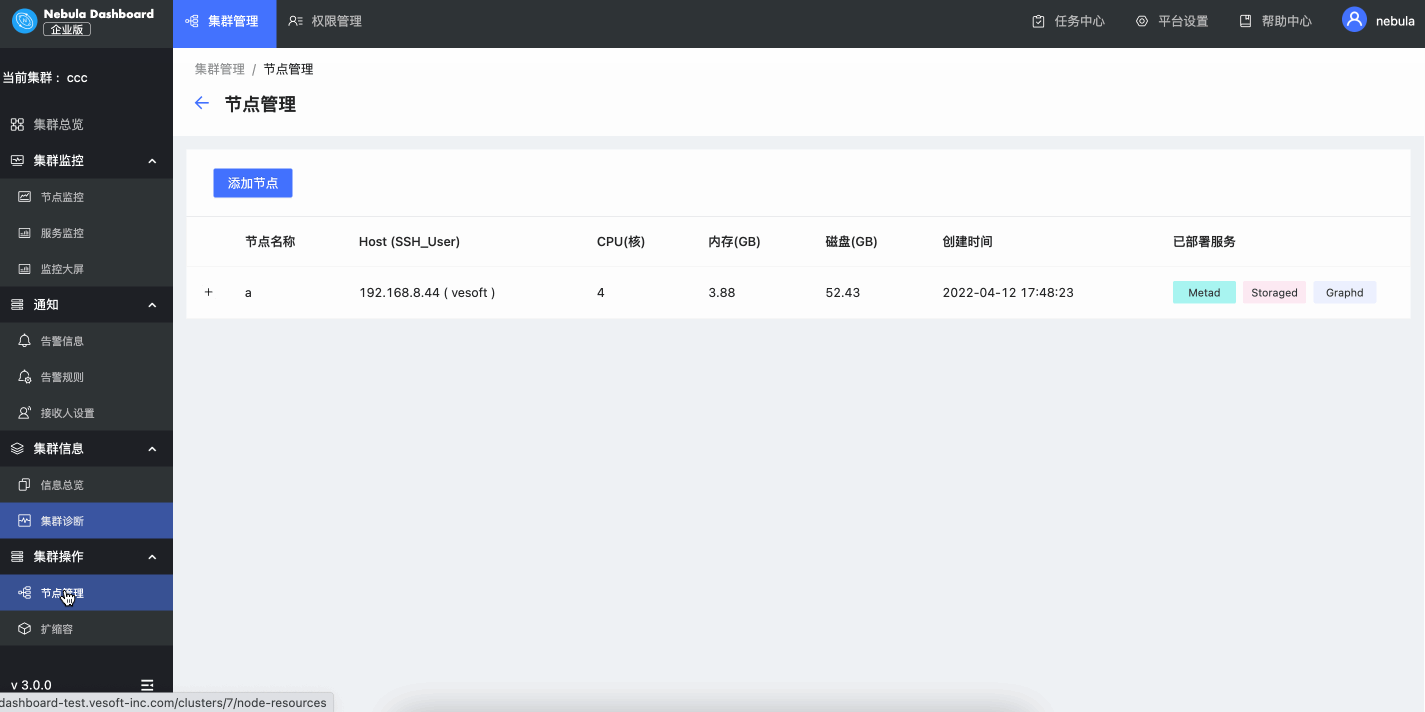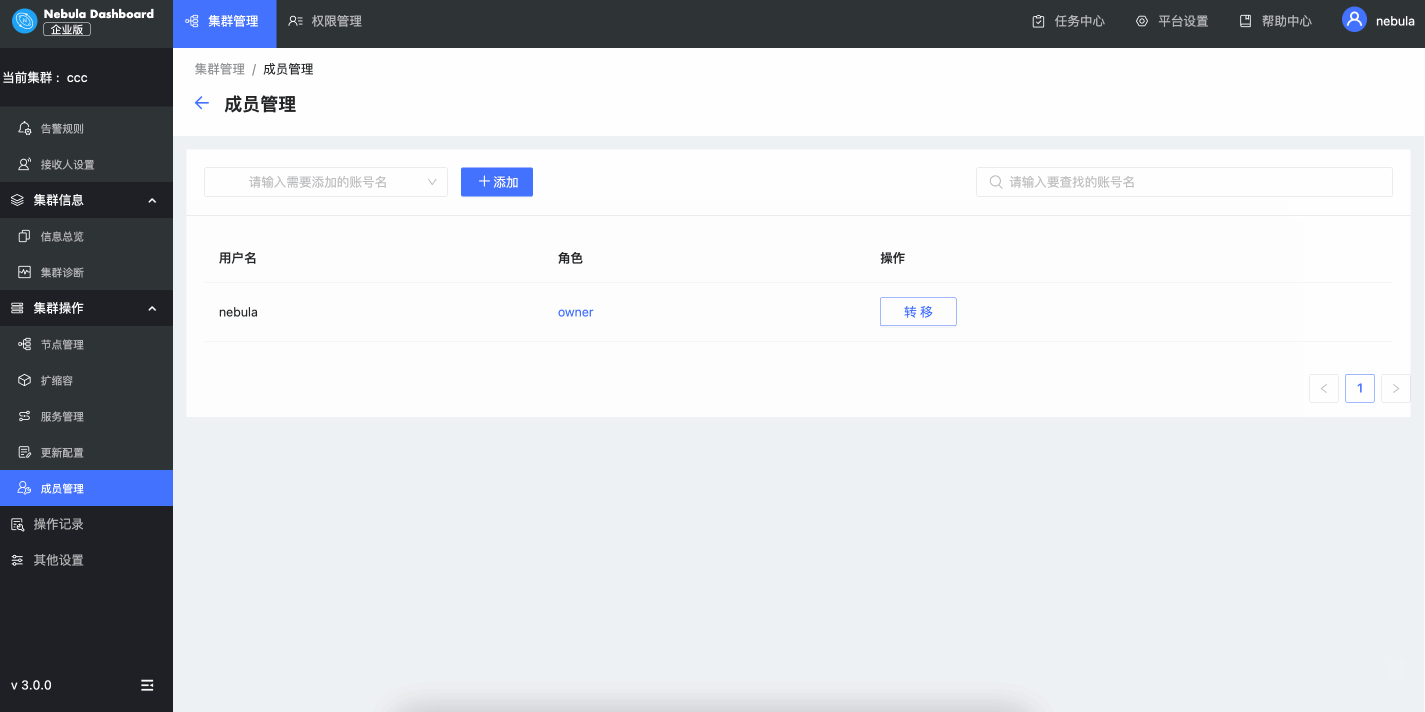
可视化技术
在不同的阶段、不同的场景下,我们会选择不同的可视化技术以便更好地服务于产品和业务。
就可视化技术来说,前端展示常见的可视化渲染技术是 SVG、Canvas、CSS 和 WebGL,而用什么东西去画 SVG、Canvas 便是另外一个话题。像 Nebula 社区常提到的 D3,其实并非是一种可视化技术,本质上它是一个可视化算法工具,可在网页上使用也可在终端应用。而 D3 本身有些周边工具去做简单 SVG 封装,这比较偏上层应用工具,比如像是图表库 ECharts 就是这类。
而 Nebula Dashboard 产品负责人汪洋表示常见可视化渲染技术如上所述的 CSS 和 SVG 等等,会根据所面临的应用场景、计算资源,针对性地定制化开发。比如:为了方便第三方接入,可视化库的设计人员会抽象语法、让语法糖更加科学、规范;对性能要求高的场景,便会去封装工具以便获得高性能。这里他提到了蚂蚁开源的可视化引擎:G2 https://github.com/antvis/g2/,G2 受启发于《The Grammar of Graphics》一书的理念,设计这套基于图形语法理论的可视化底层引擎,G2 的这套语法实现也是业界比较公认给的科学规范。同其他可视化库相比,G2 在语法设计这块更像是一个完整的产品。
谈及 G2,可视化图探索工具 Nebula Explorer 核心开发苗壮表示虽然 G2 语法规范、科学,但是如果真的要做数据可视化并非是一个十分顺手的可视化工具,因为它基于图形语法理论,需要一定的专业知识,因此会有一定的门槛。更多时候,G2 可能还是作为一个可视化图表库被使用而非可视化库。
可视化的性能问题
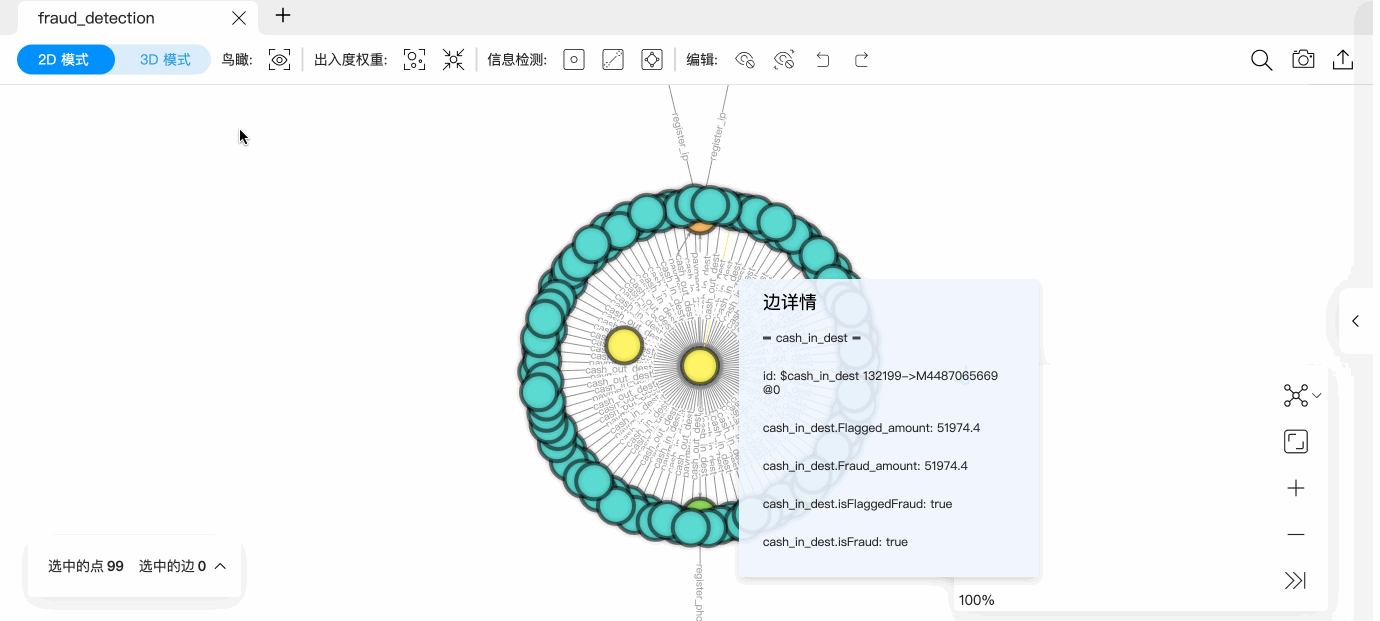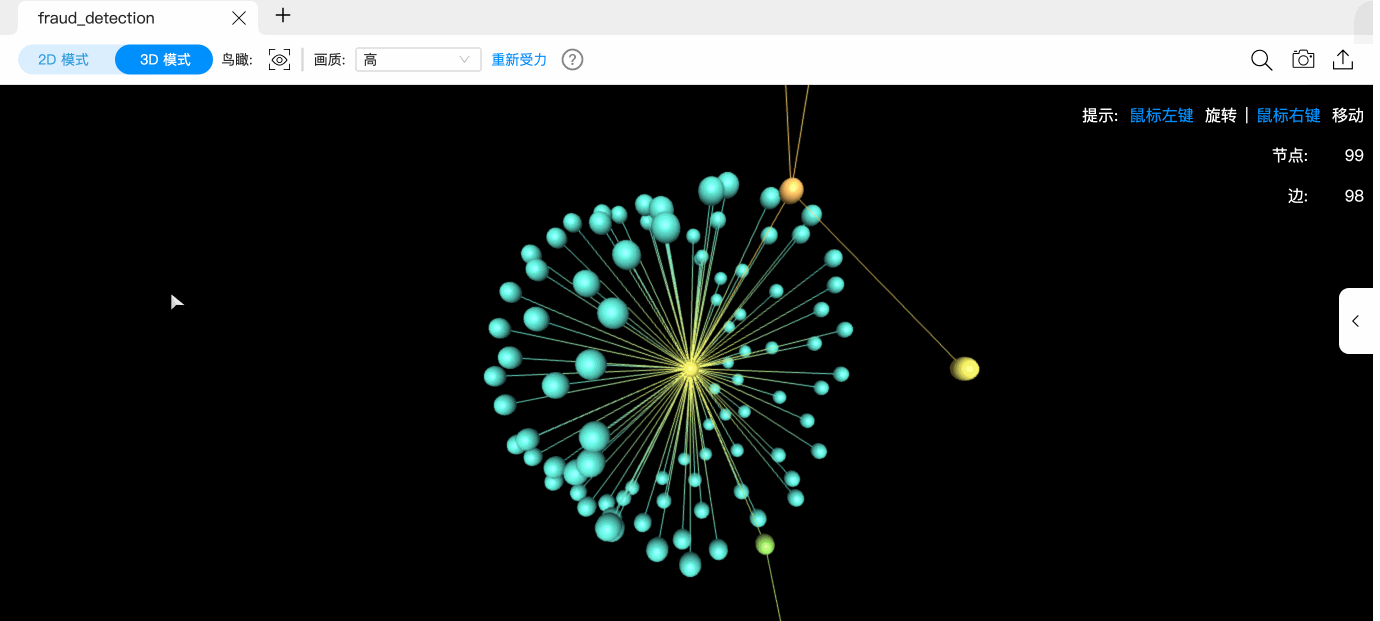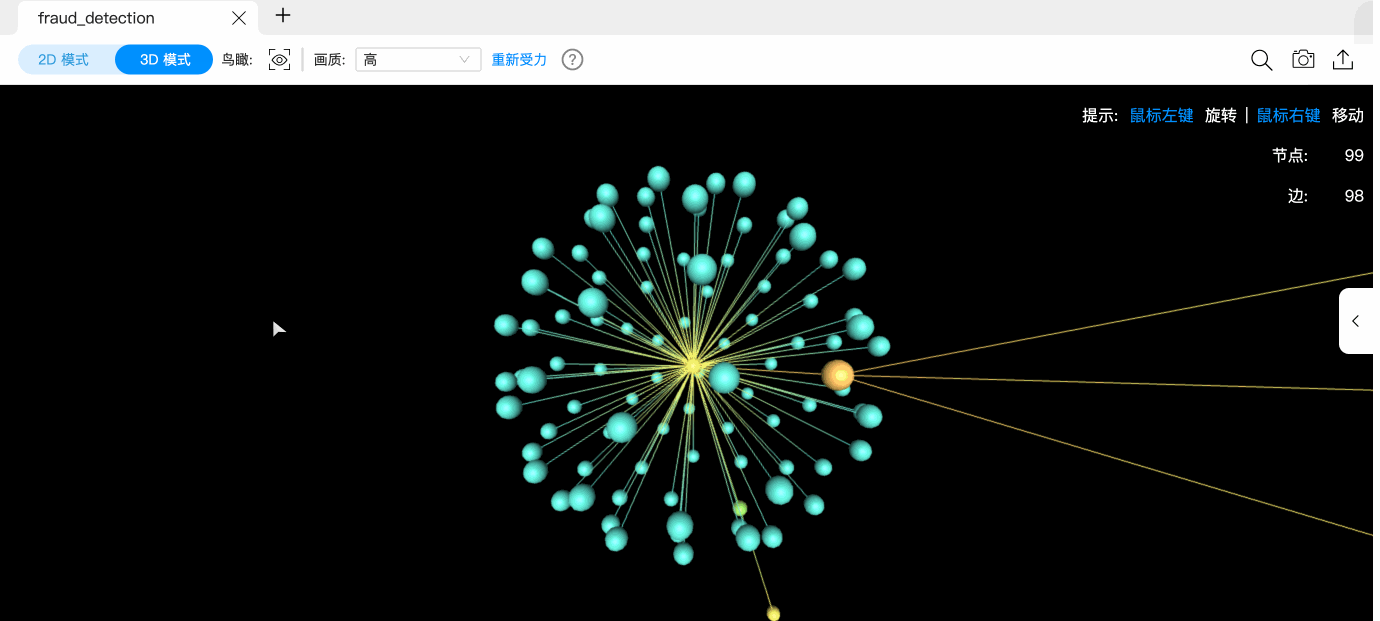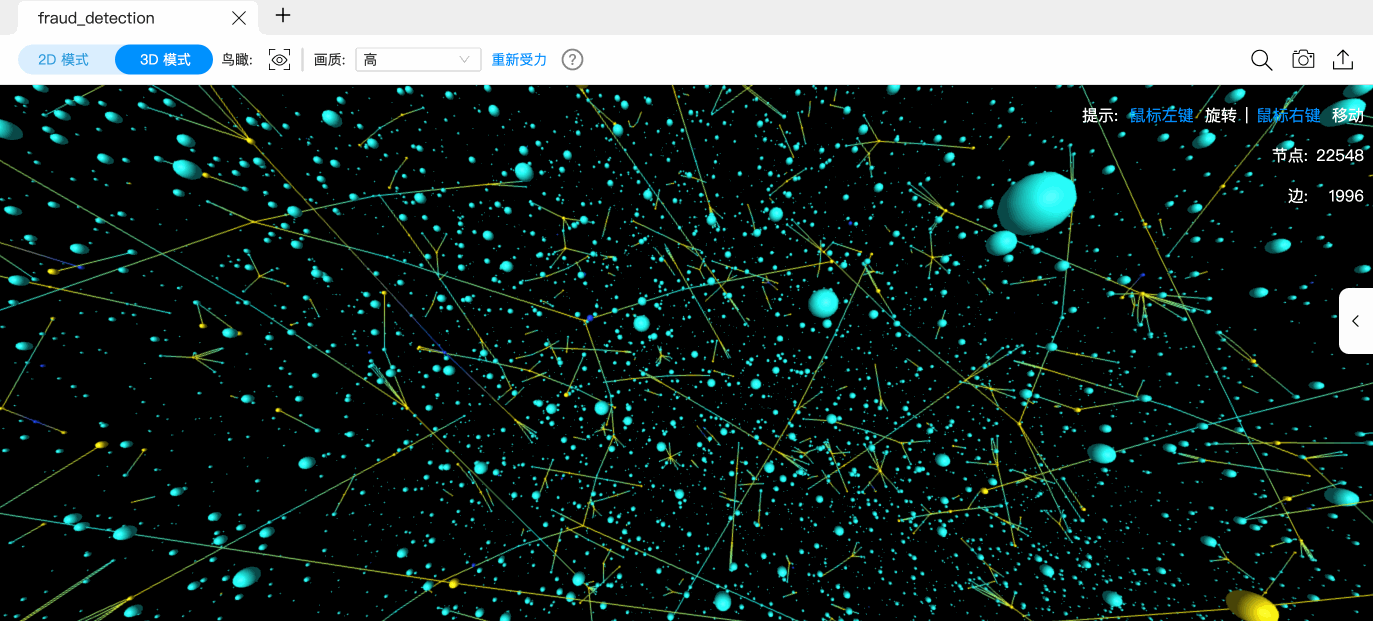
Nebula Explorer 是一款图探索工具,单个页面会面临节点数据展示的问题。社区也常有用户问及,单个画布页面能渲染多少个节点数据。针对可视化性能问题,核心产品开发苗壮说到:可视化性能并非是一个绝对性能,它往往伴随着用户体验。而用户体验和性能某种程度是成反比的,性能越好那用户的体验并非越佳,呈现的信息也会相对较少;而呈现更多的数据,则会消耗更多的硬件资源。这便是一项平衡问题。
而提高可视化性能的方法有二:一种是提高硬件配置,之前很流行的梗——分布式并发不够咋整?加台机器,没有什么是加机器解决不了的。但加机器这种简单粗暴的方法非良策,虽然解决了物理限制但是加入了成本问题,除了机器成本还有对应的系统维护成本。一台机器,或者多台机器加入之后必然会带来系统的复杂度增加。此外,加机器并非是通用解决方法,有些用户不一定能做到随心所欲地添加机器。另外一种是优化算法,相比加机器,方法二更难,本身目前算法都很完善,再继续优化也只是边际递减效应。
Nebula 可视化工具的优化实践
Nebula Explorer 优化性能也是从上面两个软硬件方向来展开。硬件方面,不同用户的硬件性能不一样,Explorer 开发过程中会选用比较好的硬件来实现酷炫特效的呈现;而针对硬件性能较差的用户,则提供高画质和普通画质两个模式,自适应适配用户硬件从而达到一个比较好的呈现效果。像 Explorer 的 3D 图探索模式虽然看过去很酷炫,很“吃”计算资源的样子,但是本身这个功能的硬件要求并非想象中高,任意一台手机的 GPU 配置都能运行 Explorer 3D 模式,相对而言的 CPU 性能更决定用户体验。
其实,除了软硬件上的性能优化,还有产品设计上的策略优化。像是一些比较难以解决的性能问题,可设法规避它。性能优化上,有个亘古不变的原则,这个原则就是要保证 1 秒钟渲染 60 帧。即便在特殊场景下,无法保证一秒钟 60 帧,做到 40 帧数以上也能保证系统的流畅度。这里就像是 React 的优化实现,它将很多大任务拆解成多个小任务,等系统空闲了再塞进去小任务。还有一种思路,如果是代码层面解决不了的问题,可以修改相对应的交互方式。比如一个长耗时任务,在跑,这时候如果页面不可点击,你会觉得很卡顿对吧?而,这时候加入一个 loading 动画,便会大大地降低用户的等待焦虑,会让用户觉得没那么卡顿。
这里,讲个亲身经历:Nebula Dashboard 刚上线可视化大屏时,踩过的性能坑。可视化大屏刚上线时,只是觉得是个简单大屏可能不会涉及太大的性能问题。结果,一上线 CPU 疯狂转,当时就懵逼了:Nebula Dashboard 可视化大屏只有 7、8 个图表。虽然界面酷炫,但是其实整个网络请求也就只有十几个,于是排除了 CPU 在请求计算耗资源过高的问题。此外,大屏上线时,并不存在很多并发情况…经过一轮的排查,最后定位是 SVG 过度消耗资源。所以我们调整了动画实现方案:对 CPU 要求比较高的动画,进行降级,减少渲染次数和渲染频率。这就有点像是图片压缩,你丢一个 1 MB 的图片到压缩网站,压缩完可能是 200 KB,这时候其实用户肉眼是无法察觉。
可视化技术选型
上面讲到硬件和软件能提升可视化性能,但是技术选型选的好不好,也能左右你的系统系能。
在 Nebula Explorer v2.2 版本之前,由于技术选型和业务逻辑组织问题,一旦遇到上百个节点显示问题,便会遭遇卡顿,动画明显不流畅。之后,便对 Nebula Explorer 进行重构,替换了当时的渲染引擎 G6。G6 是基于 G2 的一套图可视化引擎,可能由于 G6 过于专注业务场景,以及缺少高性能场景的验证,在 Nebula Explorer 这边表现差强人意。改用 Force Graph 之后,性能提升了差不多 10 倍左右。当然并非说 G6 的性能不行,而是 Nebula Explorer 自身的可视化需求和 G6 并不 MATCH。
同 Nebula Explorer 相反,Nebula Dashboard 不存在成千上万的点数据展示,而是数量相对固定的图表展示以及对应的运维操作执行。监控图表的话,目前来说市场比较认可的是 Grafana,而 Grafana 本身也是一款开源产品。于是,我们去研究了 Grafana 的实现,发现它底层用了轻量级的 uPlot https://github.com/leeoniya/uPlot。因为 uPlot 是个小于 40kb,特色是绘制时间序列图,方便做定制化开发。而 Nebula Dashboard 除了监控之外,还有一个比较重要的功能是针对集群的管理运维操作。这与 Grafana 专注于监控的设定是背离的,加上 Nebula Dashboard 选型的三个标准是:第一,易开发上手;第二,开源社区活跃;第三,基础库多可提升开发效率。最终,选用 G2 作为 Nebula Dashboard 的可视化底层工具,以便提高开发效率。
可视化产品设计
Nebula Explorer 有 2D 和 3D 两种图探索模式,当中涉及了页面如何布局的问题。在 Nebula Explorer 设计中,采用算法来实现特定点群的聚合和散列;以及全图鸟瞰模式在 3D 模式中进行展示,因为主流的电脑为 1920*1080,一个平面最多展示百万个像素点,然后这时候换个角度,我们采用 3D 模式所能呈现的数据便会比 2D 多。
可视化小知识
关于渲染
VR、监控指标、多点展示,在计算底层渲染时渲染图形的方式大多相同。举个例子,有些计算机系统使用 OpenGL 技术渲染的 3D 图形是由若干个三角形(triangle)拼接而成,而 Nebula Explorer 计算渲染方面也是如此,即,你看到的一个球形节点,其实是由若干个三角形构成并线性插值了不同的顶点颜色。除计算机的光栅化绘图法之外,近几年流行的光线追踪渲染也是一门效果较好的渲染技术,该技术利用光线射出,反射,损耗的物理模拟方式,得到像素点的最终颜色,在视觉上会更接近真实世界。
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~
可视化技术在 Nebula Graph 中的应用的更多相关文章
- 分布式图数据库 Nebula Graph 中的集群快照实践
1 概述 1.1 需求背景 图数据库 Nebula Graph 在生产环境中将拥有庞大的数据量和高频率的业务处理,在实际的运行中将不可避免的发生人为的.硬件或业务处理错误的问题,某些严重错误将导致集群 ...
- Nebula Graph 在网易游戏业务中的实践
本文首发于 Nebula Graph Community 公众号 当游戏上知识图谱,网易游戏是如何应对大规模图数据的管理问题,Nebula Graph 又是如何帮助网易游戏落地游戏内复杂的图的业务呢? ...
- Nebula Graph 在微众银行数据治理业务的实践
本文为微众银行大数据平台:周可在 nMeetup 深圳场的演讲这里文字稿,演讲视频参见:B站 自我介绍下,我是微众银行大数据平台的工程师:周可,今天给大家分享一下 Nebula Graph 在微众银行 ...
- 解析 Nebula Graph 子图设计及实践
本文首发于 Nebula Graph 公众号 NebulaGraphCommunity,Follow 看大厂图数据库技术实践. 前言 在先前的 Query Engine 源码解析中,我们介绍了 2.0 ...
- 图数据库|基于 Nebula Graph 的 BetweennessCentrality 算法
本文首发于 Nebula Graph Community 公众号 在图论中,介数(Betweenness)反应节点在整个网络中的作用和影响力.而本文主要介绍如何基于 Nebula Graph 图数据 ...
- macOS 安装 Nebula Graph 看这篇就够了
本文首发于 Nebula Graph Community 公众号 背景 刚学习图数据的内容,当前网上充斥大量的安装文档,参差不齐,部署起来令人十分头疼. 现整理一份比较完整的安装文档,供大家学习参考, ...
- [2]R语言在数据处理上的禀赋之——可视化技术
本文目录 Java的可视化技术 R的可视化技术 二维做图利器plot的参数配置 *权限机制 *plot独有的参数 *plot的type介绍 *title介绍 *公共参数集合--par *par的权限机 ...
- 图数据库 Nebula Graph 的数据模型和系统架构设计
Nebula Graph:一个开源的分布式图数据库.作为唯一能够存储万亿个带属性的节点和边的在线图数据库,Nebula Graph 不仅能够在高并发场景下满足毫秒级的低时延查询要求,而且能够提供极高的 ...
- 分布式图数据库 Nebula Graph 的 Index 实践
导读 索引是数据库系统中不可或缺的一个功能,数据库索引好比是书的目录,能加快数据库的查询速度,其实质是数据库管理系统中一个排序的数据结构.不同的数据库系统有不同的排序结构,目前常见的索引实现类型如 B ...
- 图数据库 Nebula Graph TTL 特性
导读 身处在现在这个大数据时代,我们处理的数据量需以 TB.PB, 甚至 EB 来计算,怎么处理庞大的数据集是从事数据库领域人员的共同问题.解决这个问题的核心在于,数据库中存储的数据是否都是有效的.有 ...
随机推荐
- 数据结构与算法 第二章线性表(48课时课程笔记)Data Structure and Algorithms
2.1 线性表的类型定义 一个线性表是n个数据元素的有限序列. (1)结构初始化 InitList(&L) 构造一个空的线性表L. (2)销毁结构 DestroyList(&L) (3 ...
- 如何优雅的写 css 代码
CSS(全称 Cascading Style Sheets,层叠样式表)为开发人员提供声明式的样式语言,是前端必备的技能之一,基于互联网上全面的资料和简单易懂的语法,CSS 非常易于学习,但其知识点广 ...
- 使用Visual Studio调试 .NET源代码
前言 在我们日常开发过程中常常会使用到很多其他封装好的第三方类库(NuGet依赖项)或者是.NET框架中自带的库.如果可以设置断点并在NuGet依赖项或框架本身上使用调试器的所有功能,那么我们的源码调 ...
- 洛谷P3101 题解
输入格式 第 \(1\) 行,三个整数 \(m,n,t\). 第 \(2\) 到 \(m+1\) 行,\(m\) 个整数,表示海拔高度. 第 \(2+m\) 到 \(2m+1\) 行,\(m\) 个整 ...
- 从零开始配置 vim(15)——状态栏配置
vim 下侧有一个状态栏,会显示当前打开的文件等一系列内容,只是我们很少去关注它.而且原生的vim也支持对状态栏进行自定义.这篇文章主要介绍如何自定义状态栏 设置状态栏 我们可以采用 set stat ...
- 【一】MADDPG-单智能体|多智能体总结(理论、算法)
相关文章: [一]MADDPG-单智能体|多智能体总结(理论.算法) [二]MADDPG--单智能体|多智能体总结算法实现--[追逐游戏] [一]-环境配置+python入门教学 [二]-Parl基础 ...
- RabbitMQ基础学习Full版
RabbitMQ 消息队列在软件中的应用场景 异步处理上(优于原先的方式) 为什么优于呢? 首先,通常情况下,如上图我们其实不用消息队列的情况下,其实也可以不用100ms,不用allof即可 那么优势 ...
- 探索C语言中的联合体与枚举:数据多面手的完美组合!
欢迎大家来到贝蒂大讲堂 养成好习惯,先赞后看哦~ 所属专栏:C语言学习 贝蒂的主页:Betty's blog 1. 联合体的定义 联合体又叫共用体,它是一种特殊的数据类型,允许您在相同的内存位置存 ...
- Pandas数据合并
目录 1) 在单个键上进行合并操作 2) 在多个键上进行合并操作 使用how参数合并 1) left join 2) right join 3) outer join(并集) 4) inner joi ...
- SAM题目合集
一些SAM的 基础 题目.(主要是我不想写SAM的原理啊啊啊) 有的题目是SA的思维题,但是可以用SAM平推,基本上可以不动脑子. 除非有特殊说明,否则将字符集看作所有小写字母,构造SAM复杂度记为 ...