日志分类以及TFIDF
TF的概念是Term Frequent,是一个单词出现的频率,是一个局部概念,就是这个单词在指定文件中出现的频率,公式如下:
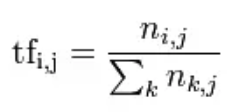
但是呢,这个TF其实很没有说服力,比如the,a之类的频率很高,但是其实不能实现很好地分类标志,尽管可以在停用词中进行禁用,但是很多单词还是无法全部禁用干净;这个时候就引入了IDF,Inverse Document Frequent,反向文档频率(我称之为区分度公式),公式是
idf = log(N/d)
N是文档数量,存在该单词的文档的个数,这里IDF是一个全局概念,是一个单词在全局的分布情况,分布的越少,idf的值越高;IDF实现了"对于出现频率低"的单词赋予比较高的权重,比如"越位",是一个专业术语,一般只是出现在足球相关的文章中,那么,这个词的IDF就会比较大,或者说这个词的区分度会比较大。
TFIDF = TF(t, d) * IDF(t)
这里强调一下,TFIDF是一种评分,TFIDF计算出来的结果是要作为特征值写入到稀疏矩阵的。
下面说一下对于新闻分类的套路;首先是加载所有的新闻训练样本,然后进行分词,将分词(term)放入到一张大表中,这是第一张大表:Term(特征)字典表;Term字典表的形成过程:计算每个Term的TFIDF(看到了,TFIDF是term的,在NPL中,每个term就是一个特征,或者说一个维度);这样就形成了一张key-value表,key就是term的hash值,value就是term的tfidf的值;这里解释一下,所谓的Hash算法,是指对于每个分词进行Hash取值,这个值就是分词的索引;在这个字典表的索引;在文本挖掘里面,每个分词就是特征,对于分词取Hash之后,其实就是特征索引值,然后找到对应的特征做统计;为什么要做这么做?简化流程,否则需要遍历整张表来查找匹配Term;如果采用Hash的方式,取要查找的分词的hansh值,直接过去到了索引,将term的比较转化为了索引值的定位,简化的查询的过程;
第一张字典表有了,下面就是形成第二张大表:样本表;新闻分类是要进行训练的;来了一条样本之后,需要进行分词,然后取各个分词的hash值,拿着hash值到字典表中找对应的tfidf值,然后把tfidf填充到样本表中同字典表索引的位置;如此形成一行;所以一条样本(新闻)其实不会填充几个term,很多单元格都是空着的;如果多条记录之后,形成了什么?形成了稀疏矩阵。
采用hash算法获取索引,那么碰撞了怎么办?所以这张哈希表一定要大,默认的是2.18,分析云用的是2.20
比如"美国",这个特征,取hash值为242,首先到字典表索引242中找到tfidf值;然后在样本(稀疏表)的列索引242的位置设置tfidf值;这样,就形成了一个特征向量(一个稀疏的向量/矩阵)。
train的这些样本都是可以作为未来比较的原始样本;设想新来了一条新闻记录,然后从任意类别中抽出来一个(特征向量),将两个特征向量基于余弦相似度衡量,根据余弦值来判断是否是同类新闻;什么是余弦相似度?
cos(x) = x * y / ||x|| * ||y||
对于稀疏矩阵场景,需要使用余弦定理,对于为0的特征,分子是0,所以适用(不过两者都是0就跪了)
对于新闻场景还可以继续进行训练,就是基于贝叶斯来计算一段文字是某个分类新闻的概率;这个原理就是,计算某段文字中各个单词是每一种分类的概率,然后把这些概率做相乘;那么怎么计算概率呢?这里采用其实是一半贝叶斯公式,我们知道贝叶斯公式如下:
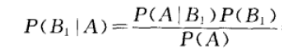
在这里,B代表类别,A代表具体的某个文档(由各个分词组成);在贝叶斯公式中,文档A是分类B的概率的计算是可以转化为P(A1|B) * P(A2|B) * P(A3|B)...*P(B),Ai是文档A的分词;根据条件我们是可以把类别B某个具体分词的概率统计出来,分类B占全局分类的概率P(B)也是可以求出来;对于P(A),因为所有的元素P(A)的概率都是一样的,所以这里可以忽略不记。直接比较分子,谁大,那么谁就是该分类。
在我们日志分析云中并没有采用这种(朴素贝叶斯)方式,因为该方式是应用于分类已经很清晰的场景下;而我们的场景下是会有新的日志类型产生。
日志分类以及TFIDF的更多相关文章
- mysql日志分类
mysql的日志分类: (1)错误日志:记录mysql服务的启动,运行,停止mysql服务时出现的问题 [mysqld] log_error=[/path/filename] (2)通用查询日志:记录 ...
- IntelliJ IDEA中日志分类显示设置
说明:很遗憾,IDEA中无法实现日志分类查看,比如只能显示INFO级别的,但是可以有搜索功能[Ctrl]+[F].好像找不到好用的插件,Andorid Studio好像有一个插件可以. 解决方式: 直 ...
- 美团店铺评价语言处理以及分类(tfidf,SVM,决策树,随机森林,Knn,ensemble)
第一篇 数据清洗与分析部分 第二篇 可视化部分, 第三篇 朴素贝叶斯文本分类 支持向量机分类 支持向量机 网格搜索 临近法 决策树 随机森林 bagging方法 import pandas as pd ...
- Log4Net日志分类和自动维护
背景 在程序中,我们调试运行时信息,Log4Net是一个不错的解决方案.不知道是我用的不好,用到最后反而都不想看日志了.原因是因为我n个功能使用的默认的Logger来记录日志,这样以来,所有功能记录的 ...
- 文本分类(TFIDF/朴素贝叶斯分类器/TextRNN/TextCNN/TextRCNN/FastText/HAN)
目录 简介 TFIDF 朴素贝叶斯分类器 贝叶斯公式 贝叶斯决策论的理解 极大似然估计 朴素贝叶斯分类器 TextRNN TextCNN TextRCNN FastText HAN Highway N ...
- tomcat日志分类
综合:Tomcat下相关的日志文件 Cataline引擎的日志文件,文件名catalina.日期.log Tomcat下内部代码丢出的日志,文件名localhost.日期.log(jsp页面内部错误的 ...
- 大数据学习——flume日志分类采集汇总
1. 案例场景 A.B两台日志服务机器实时生产日志主要类型为access.log.nginx.log.web.log 现在要求: 把A.B 机器中的access.log.nginx.log.web.l ...
- Oracle-归档日志详解(运行模式、分类)
一.Oracle日志分类 分三大类: Alert log files--警报日志,Trace files--跟踪日志(用户和进程)和 redo log 重做日志(记录数据库的更改 ...
- 文本分类四之权重策略:TF-IDF方法
接下来,目的就是要将训练集所有文本文件(词向量)统一到同一个词向量空间中.在词向量空间中,事实上不同的词,它的权重是不同的,它对文本分类的影响力也不同,为此我们希望得到的词向量空间不是等权重的空间,而 ...
随机推荐
- Spring源码窥探之:注解方式的AOP原理
AOP入口代码分析 通过注解的方式来实现AOP1. @EnableAspectJAutoProxy通过@Import注解向容器中注入了AspectJAutoProxyRegistrar这个类,而它在容 ...
- Laravel —— could not find driver
Laravel 中的数据库是以 PDO 的方式连接的 数据库连接失败时,先检查问题所在,再对症下药 本文以 pgsql 为例 1.判断 pgsql 是否启动 $ ps -ef | grep pgsql ...
- [Luogu 3794]签到题IV
Description 题库链接 给定长度为 \(n\) 的序列 \(A\).求有多少子段 \([l,r]\) 满足 \[ \left(\gcd_{l\leq i\leq r}A_i\right) \ ...
- 简述Python的深浅拷贝以及应用场景?
浅拷贝:copy.copy 深拷贝:copy.deepcopy 浅拷贝指仅仅拷贝数据集合的第一层数据,深拷贝指拷贝数据集合的所有层 主要应用在字符串,数字的 ...
- [CSS] prefers-reduced-motion
The prefers-reduced-motion CSS media feature is used to detect if the user has requested that the sy ...
- shell grep的基本用法
grep 1.-i 不区分大写小写 2.-n 区分大小写 3.-E 查找多个条件 4.-c 查找到的结果的行数 5.-w 精确查找 6.取反 7.-q 静默输出
- am335x system upgrade set/get current cpufreq(二十一)
1 Scope of Document This document describes am335x cpufreq technology insider. 2 Requireme ...
- cube.js 新版本试用preosto
cube.js 新的版本添加了更多的数据库的支持,但是目前cubejs-cli 以及官方文档问题还挺多,使用不清晰,文档有明显的错误 以下演示presto 数据库的使用 环境准备 安装新版本的cube ...
- testinfra 基础设施测试工具
testinfra 是基于python 开发的基础设施测试工具,我们可以用来方便的测试基础设施 是否符合我们的要求(系统,软件...) 一个参考demo def test_passwd_file( ...
- NetHack 备忘
NetHack 备忘 常用操作 操作均区分大小写 上下左右移动 y k u h l b j n / 查看地图上的东西 < 上楼 > 下楼 c 关门 部分怪不会开门 a 使用(工具) d 丢 ...