大数据学习——flume日志分类采集汇总
1. 案例场景
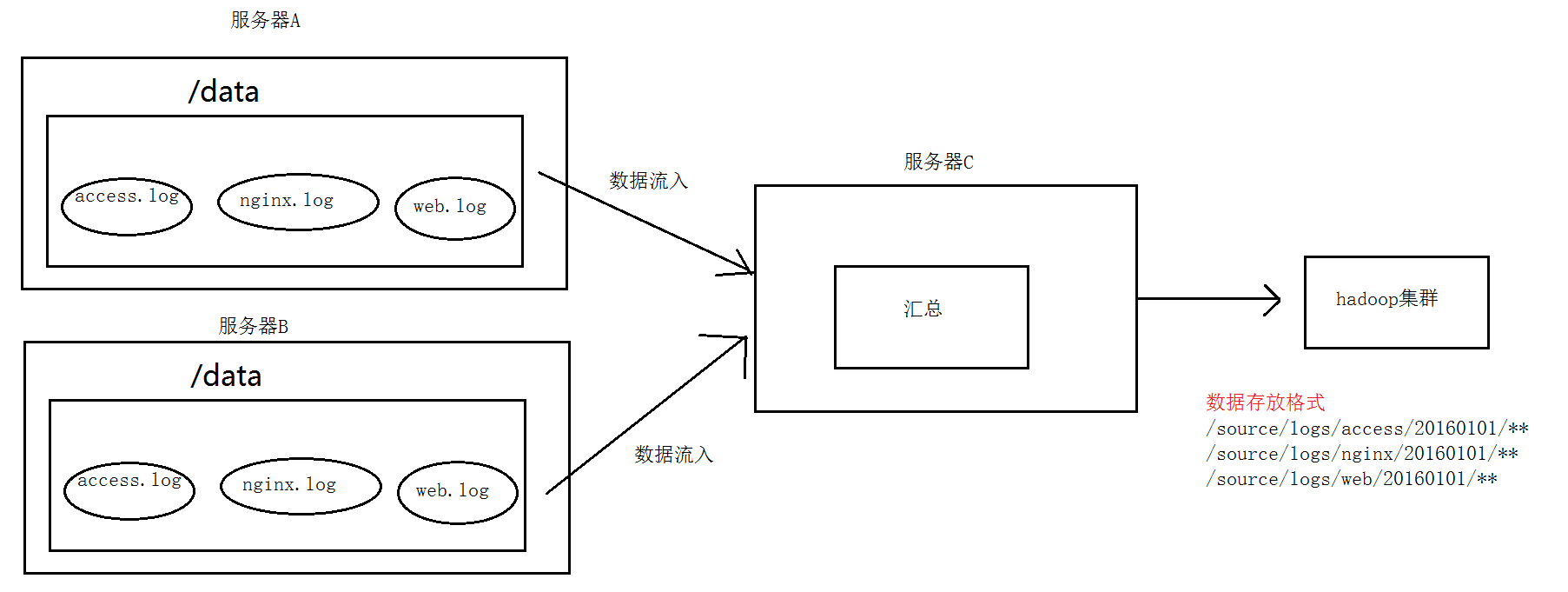
A、B两台日志服务机器实时生产日志主要类型为access.log、nginx.log、web.log
现在要求:
把A、B 机器中的access.log、nginx.log、web.log 采集汇总到C机器上然后统一收集到hdfs中。
但是在hdfs中要求的目录为:
/source/logs/access/20160101/**
/source/logs/nginx/20160101/**
/source/logs/web/20160101/**
2. 场景分析
3. 数据流程处理分析
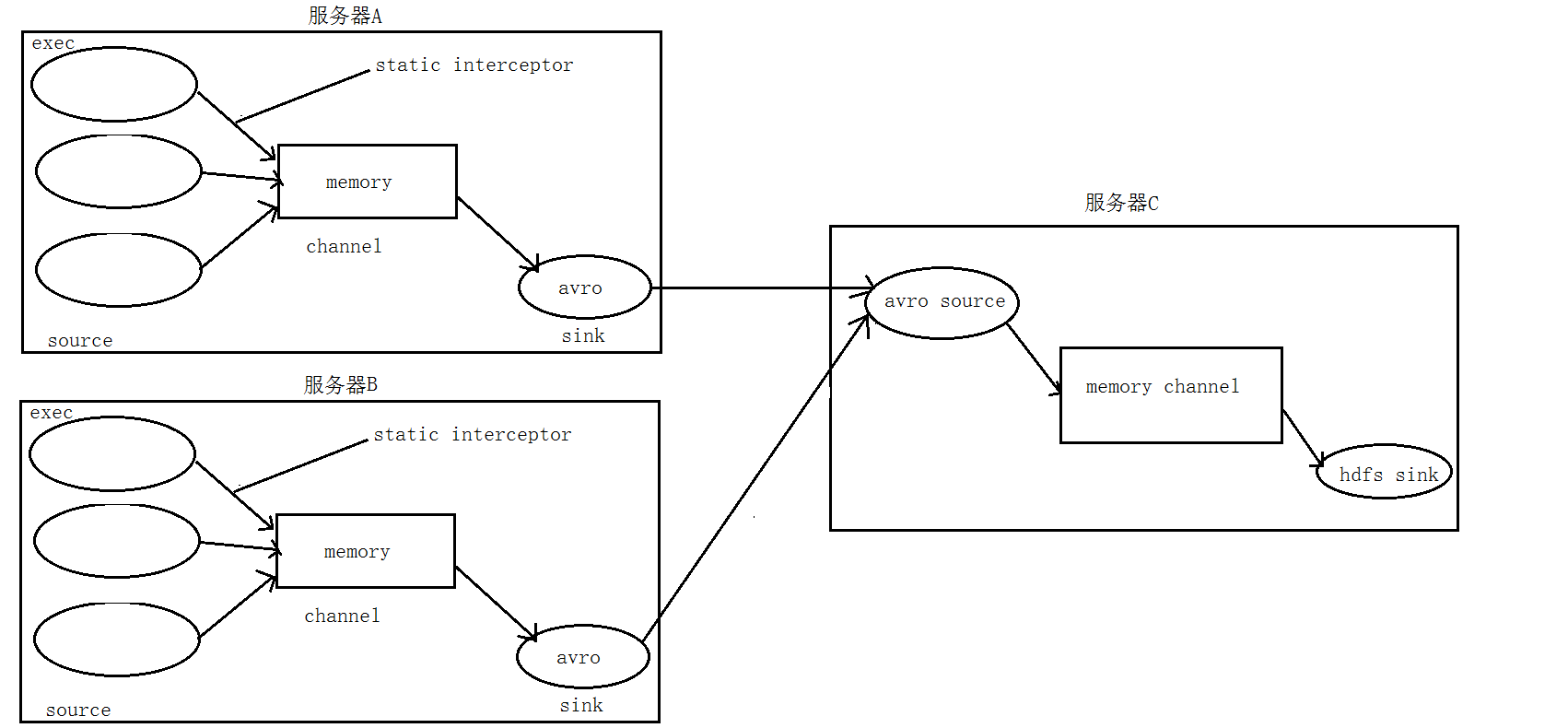
4. 实现
服务器A对应的IP为 192.168.200.102
服务器B对应的IP为 192.168.200.103
服务器C对应的IP为 192.168.200.101
① 在服务器A和服务器B上的$FLUME_HOME/conf 创建配置文件 exec_source_avro_sink.conf 文件内容为
exec_source_avro_sink.conf 文件内容为 # Name the components on this agent
a1.sources = r1 r2 r3
a1.sinks = k1
a1.channels = c1 # Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /root/data/access.log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
## static拦截器的功能就是往采集到的数据的header中插入自己定## 义的key-value对
a1.sources.r1.interceptors.i1.key = type
a1.sources.r1.interceptors.i1.value = access a1.sources.r2.type = exec
a1.sources.r2.command = tail -F /root/data/nginx.log
a1.sources.r2.interceptors = i2
a1.sources.r2.interceptors.i2.type = static
a1.sources.r2.interceptors.i2.key = type
a1.sources.r2.interceptors.i2.value = nginx a1.sources.r3.type = exec
a1.sources.r3.command = tail -F /root/data/web.log
a1.sources.r3.interceptors = i3
a1.sources.r3.interceptors.i3.type = static
a1.sources.r3.interceptors.i3.key = type
a1.sources.r3.interceptors.i3.value = web # Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 192.168.200.101
a1.sinks.k1.port = # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sources.r2.channels = c1
a1.sources.r3.channels = c1
a1.sinks.k1.channel = c1
② 在服务器C上的$FLUME_HOME/conf 创建配置文件 avro_source_hdfs_sink.conf 文件内容为
#定义agent名, source、channel、sink的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1 #定义source
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = #添加时间拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder #定义channels
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = #定义sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path=hdfs://192.168.200.101:9000/source/logs/%{type}/%Y%m%d
a1.sinks.k1.hdfs.filePrefix =events
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
#时间类型
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件不按条数生成
a1.sinks.k1.hdfs.rollCount =
#生成的文件按时间生成
a1.sinks.k1.hdfs.rollInterval =
#生成的文件按大小生成
a1.sinks.k1.hdfs.rollSize =
#批量写入hdfs的个数
a1.sinks.k1.hdfs.batchSize =
flume操作hdfs的线程数(包括新建,写入等)
a1.sinks.k1.hdfs.threadsPoolSize=
#操作hdfs超时时间
a1.sinks.k1.hdfs.callTimeout= #组装source、channel、sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
③ 配置完成之后,在服务器A和B上的/root/data有数据文件access.log、nginx.log、web.log。先启动服务器C上的flume,启动命令
在flume安装目录下执行 :
bin/flume-ng agent -c conf -f conf/avro_source_hdfs_sink.conf -name a1 -Dflume.root.logger=DEBUG,console
然后在启动服务器上的A和B,启动命令
在flume安装目录下执行 :
bin/flume-ng agent -c conf -f conf/exec_source_avro_sink.conf -name a1 -Dflume.root.logger=DEBUG,console
5. 项目实现截图


大数据学习——flume日志分类采集汇总的更多相关文章
- 大数据学习——flume拦截器
flume 拦截器(interceptor)1.flume拦截器介绍拦截器是简单的插件式组件,设置在source和channel之间.source接收到的事件event,在写入channel之前,拦截 ...
- 大数据学习——flume安装部署
1.Flume的安装非常简单,只需要解压即可,当然,前提是已有hadoop环境 上传安装包到数据源所在节点上 然后解压 tar -zxvf apache-flume-1.6.0-bin.tar.gz ...
- 大数据学习路线,来qun里分享干货,
一.Linux lucene: 全文检索引擎的架构 solr: 基于lucene的全文搜索服务器,实现了可配置.可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面. 推荐一个大数据学习群 ...
- 大数据学习系列之—HBASE
hadoop生态系统 zookeeper负责协调 hbase必须依赖zookeeper flume 日志工具 sqoop 负责 hdfs dbms 数据转换 数据到关系型数据库转换 大数据学习群119 ...
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
- 大数据(9) - Flume的安装与使用
Flume简介 --(实时抽取数据的工具) 1) Flume提供一个分布式的,可靠的,对大数据量的日志进行高效收集.聚集.移动的服务,Flume只能在Unix环境下运行. 2) Flume基于流式架构 ...
- 大数据学习day31------spark11-------1. Redis的安装和启动,2 redis客户端 3.Redis的数据类型 4. kafka(安装和常用命令)5.kafka java客户端
1. Redis Redis是目前一个非常优秀的key-value存储系统(内存的NoSQL数据库).和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
随机推荐
- Centos 6.5安装MySQL-python
报错信息: Using cached MySQL-python-1.2.5.zip Complete output from command python setup.py egg_info: ...
- CF982C Cut 'em all!
思路: 在深搜过程中,贪心地把树划分成若干个连通分支就可以了.划分的条件是某个子树有偶数个节点.注意到在一次划分之后并不需要重新计数,因为一个数加上一个偶数并不影响这个数的奇偶性. 实现: #incl ...
- ceph脚本-自动部署计算机节点
依然还在加班中,最近确实忙的脚打后脑勺! 又花了些时间丰富ceph脚本,可以连带着自动部署计算机节点了. 这一部分内容是后加的.可以关注我的公众号获取更多的项目代码和讲解!波神与你同行哦,加油!!!
- SQL中的笛卡儿积问题和多表连接操作
(使用scott用户) SELECT * FROM scott.dept;--4SELECT * FROM scott.emp;--14 /**笛卡尔积内连接(等值连接)外连接(非等值连接)自连接*/ ...
- log4j 日志分级处理
log4j 配置文件: log4j.rootLogger=debug,stdout,debug,info,errorlog4j.appender.stdout=org.apache.log4j.Con ...
- easybcd 支持 windows 10 和 ubuntu 14.04 双系统启动
家里计算机系统 windows 10 全新安装. 原本是双系统的,还有一个ubuntu. windows 10 安装以后,恢复ubuntu就是问题了. (事后经验:请不要立刻安装bcd修改工具) 最初 ...
- [整理]ADB命令行学习笔记
global driver# 元素定位driver.find_element_by_id("id") # id定位driver.find_element_by_name(" ...
- axios 里面 then 默认写的function里面没有this,改成箭头函数后就可以用this了
,methods:{ loadJson:function(){ //this.jsonTest = "jjj" this.$http.get('http://localhost:3 ...
- vue中状态管理vuex的使用分享
一.main.js中引入 store import store from './store' window.HMO_APP = new Vue({ router, store, render: h = ...
- Hibernate5.x版本HQL限定查询 Legacy-style query parameters (`?`) are no longer supported
在此版本的限定查询和4.0版本的限定查询: 如果查询语句是: String hql = "select u from User u where u.gender = ?"; 会出现 ...