非负矩阵分解(NMF)原理及算法实现
一、矩阵分解回想
矩阵分解是指将一个矩阵分解成两个或者多个矩阵的乘积。对于上述的用户-商品(评分矩阵),记为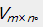 能够将其分解为两个或者多个矩阵的乘积,如果分解成两个矩阵
能够将其分解为两个或者多个矩阵的乘积,如果分解成两个矩阵 和
和 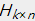 。我们要使得矩阵和 的乘积能够还原原始的矩阵
。我们要使得矩阵和 的乘积能够还原原始的矩阵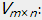

当中,矩阵表示的是m个用户于k个主题之间的关系,而矩阵表示的是k个主题与n个商品之间的关系
通常在用户对商品进行打分的过程中,打分是非负的,这就要求:

这便是非负矩阵分解(NMF)的来源。
二、非负矩阵分解
2.1、非负矩阵分解的形式化定义
上面介绍了非负矩阵分解的基本含义。简单来讲,非负矩阵分解是在矩阵分解的基础上对分解完毕的矩阵加上非负的限制条件。即对于用户-商品矩阵找到两个矩阵和 ,使得:
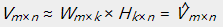
同一时候要求:

2.2、损失函数
为了能够定量的比较矩阵和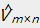 的近似程度,提出了两种损失函数的定义方式:
的近似程度,提出了两种损失函数的定义方式:
欧几里得距离:
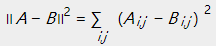
KL散度:
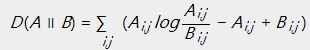
在KL散度的定义中, 。当且仅当
。当且仅当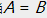 时取得等号。
时取得等号。
当定义好损失函数后,须要求解的问题就变成了例如以下的形式,相应于不同的损失函数:
求解例如以下的最小化问题:
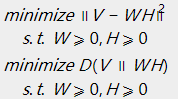
2.3、优化问题的求解
乘法更新规则,详细操作例如以下:
对于欧几里得距离的损失函数:

对于KL散度的损失函数:
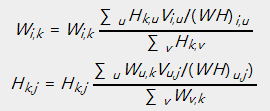
上述的乘法规则主要是为了在计算的过程中保证非负,而基于梯度下降的方法中,加减运算无法保证非负。事实上上述的惩罚更新规则与梯度下降的算法是等价的。以下以平方距离为损失函数说明上述过程的等价性:
平方损失函数能够写成:

使用损失函数对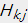 求偏导数:
求偏导数:
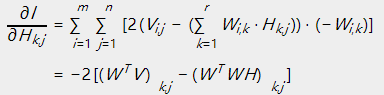
依照梯度下降法的思路:
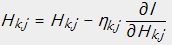
即为:

令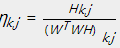 ,即能够得到上述的乘法更新规则的形式。
,即能够得到上述的乘法更新规则的形式。
2.4、非负矩阵分解的实现
from numpy import *
from pylab import *
from numpy import * def load_data(file_path):
f = open(file_path)
V = []
for line in f.readlines():
lines = line.strip().split("\t")
data = []
for x in lines:
data.append(float(x))
V.append(data)
return mat(V) def train(V, r, k, e):
m, n = shape(V)
#先随机给定一个W、H,保证矩阵的大小
W = mat(random.random((m, r)))
H = mat(random.random((r, n)))
#K为迭代次数
for x in range(k):
#error
V_pre = W * H
E = V - V_pre
#print E
err = 0.0
for i in range(m):
for j in range(n):
err += E[i,j] * E[i,j]
print(err)
data.append(err) if err < e:
break
#权值更新
a = W.T * V
b = W.T * W * H
#c = V * H.T
#d = W * H * H.T
for i_1 in range(r):
for j_1 in range(n):
if b[i_1,j_1] != 0:
H[i_1,j_1] = H[i_1,j_1] * a[i_1,j_1] / b[i_1,j_1] c = V * H.T
d = W * H * H.T
for i_2 in range(m):
for j_2 in range(r):
if d[i_2, j_2] != 0:
W[i_2,j_2] = W[i_2,j_2] * c[i_2,j_2] / d[i_2, j_2] return W,H,data if __name__ == "__main__":
#file_path = "./data_nmf"
# file_path = "./data1"
data = []
# V = load_data(file_path)
V=[[5,3,2,1],[4,2,2,1,],[1,1,2,5],[1,2,2,4],[2,1,5,4]]
W, H ,error= train(V, 2, 100, 1e-5 )
print (V)
print (W)
print (H)
print (W * H)
n = len(error)
x = range(n)
plot(x, error, color='r', linewidth=3)
plt.title('Convergence curve')
plt.xlabel('generation')
plt.ylabel('loss')
show()
这里需要注意训练时r值的选择:r可以表示和主题数或者你想要的到的特征数
K值的选择:k表示训练的次数,设置的越大模型的拟合效果越好,但是具体设置多少,要根据性价比看,看误差曲线的变化
非负矩阵分解(NMF)原理及算法实现的更多相关文章
- 非负矩阵分解NMF
http://blog.csdn.net/pipisorry/article/details/52098864 非负矩阵分解(NMF,Non-negative matrix factorization ...
- 文本主题模型之非负矩阵分解(NMF)
在文本主题模型之潜在语义索引(LSI)中,我们讲到LSI主题模型使用了奇异值分解,面临着高维度计算量太大的问题.这里我们就介绍另一种基于矩阵分解的主题模型:非负矩阵分解(NMF),它同样使用了矩阵分解 ...
- 【代码更新】单细胞分析实录(21): 非负矩阵分解(NMF)的R代码实现,只需两步,啥图都有
1. 起因 之前的代码(单细胞分析实录(17): 非负矩阵分解(NMF)代码演示)没有涉及到python语法,只有4个python命令行,就跟Linux下面的ls grep一样的.然鹅,有几个小伙伴不 ...
- 推荐算法——非负矩阵分解(NMF)
一.矩阵分解回想 在博文推荐算法--基于矩阵分解的推荐算法中,提到了将用户-商品矩阵进行分解.从而实现对未打分项进行打分. 矩阵分解是指将一个矩阵分解成两个或者多个矩阵的乘积.对于上述的用户-商品矩阵 ...
- 浅谈隐语义模型和非负矩阵分解NMF
本文从基础介绍隐语义模型和NMF. 隐语义模型 ”隐语义模型“常常在推荐系统和文本分类中遇到,最初来源于IR领域的LSA(Latent Semantic Analysis),举两个case加快理解. ...
- 单细胞分析实录(17): 非负矩阵分解(NMF)代码演示
本次演示使用的数据来自2017年发表于Cell的头颈鳞癌单细胞文章:Single-Cell Transcriptomic Analysis of Primary and Metastatic Tumo ...
- 数据降维-NMF非负矩阵分解
1.什么是非负矩阵分解? NMF的基本思想可以简单描述为:对于任意给定的一个非负矩阵V,NMF算法能够寻找到一个非负矩阵W和一个非负矩阵H,使得满足 ,从而将一个非负的矩阵分解为左右两个非负矩阵的乘积 ...
- 降维、特征提取与流形学习--非负矩阵分解(NMF)
非负矩阵分解(NMF)是一种无监督学习算法,目的在于提取有用的特征(可以识别出组合成数据的原始分量),也可以用于降维,通常不用于对数据进行重建或者编码. NMF将每个数据点写成一些分量的加权求和(与P ...
- 机器学习--K折交叉验证和非负矩阵分解
1.交叉验证 交叉验证(Cross validation),交叉验证用于防止模型过于复杂而引起的过拟合.有时亦称循环估计, 是一种统计学上将数据样本切割成较小子集的实用方法. 于是可以先在一个子集上做 ...
随机推荐
- hibernate课程 初探单表映射1-8 hibernate持久化类
java beans 的设计原则 1 公有的类 2 共有不带参数构造方法 3 私有属性 4 属性setter/getter方法 Studnet类: package com.ddwei.student; ...
- Linux常用操作2
第1章 find命令扩展 转自:https://www.cnblogs.com/clsn/p/7520333.html 1.1 方法一 |xargs 通过|xargs将前面命令的执行结果传给后面. [ ...
- php 出现空格,换行原因
1.空格:转换成utf-8无bom格式 2.空格:<?php ?>标签结尾有中文,英文空格 3.换行,一个文件中有多个<?php ?>标签,标签间隔中有换行符合
- 添加SAP_ALL权限
更新usr04,ust04,usrbf2这三张表 REPORT ZTESTCREATEUSER. data: l_USR04 LIKE USR04 , l_UST04 LIKE UST04 , l_P ...
- html的语法 3
<html> <head> <title>这是第一节课网页标题</title> <!--meta charset="UTF-8" ...
- mui蒙版使用例子
<!DOCTYPE html><html><head> <meta charset="utf-8"> <meta name=& ...
- 用C#来控制高级安全Windows防火墙
有的时候我们需要在自己的产品中检测<高级安全Windows防火墙>的状态,并有可能需要加入一些规则甚至需要关闭掉高级安全Windows防火墙. 下面就告诉如何来做: <高级安全Win ...
- chrome中清除dns缓存
chrome中清除dns缓存 http://rss.code-mire.com/item/1005.htm web开发经常要做各种host绑定的切换,firefox下有个DNS Flusher插件,但 ...
- linux常用工具
命令 功能应用 用法举例 free 查看内存使用情况,包括物理内存和虚拟内存 free -h或free -m vmstat 对系统的整体情况进行统计,包括内核进程.虚拟内存.磁盘.陷阱和 CPU 活动 ...
- 【Python音乐生成】可能有用的一些Python库
1,Python-MIDI,很多操作库的前置库.作者提供了一个python3的branch.git clone下来之后注意切换到这个branch之后再运行setup.py. 实际使用的时候,使用 im ...