Hadoop- MapReduce分布式计算框架原理
分布式计算:
原则:移动计算而尽可能减少移动数据(减少网络开销)
分布式计算其实就是将单台机器上的计算拓展到多台机器上并行计算。
MapReduce分布式计算框架体系结构
首先理解几个概念:
Job&Task:在hadoop mapreduce中,一个 Job 它是一个任务,主业务。一个Job 可以拆分成多个Task,map Task与reduce Task。
JobTracker:JobTracker是一个后台服务进程,启动之后,会一直监听并接收来自各个TaskTracker发送的心跳信息,包括资源使用情况和任务运行情况等信息
MapReduce体系结构里有两类节点,第一个是JobTracker,它是一个master管理节点,另一个是TaskTracker。客户端(Client)提交一个任务(Job),JobTracker把他提交到候选列队里,将Job拆分成map任务(Task)和reduce任务(Task),把map任务和reduce任务分给TaskTracker执行。在mapreduce编程模型里,Task一般起在和DataNode所在的同一台物理机上。如下图(图片来自网络):
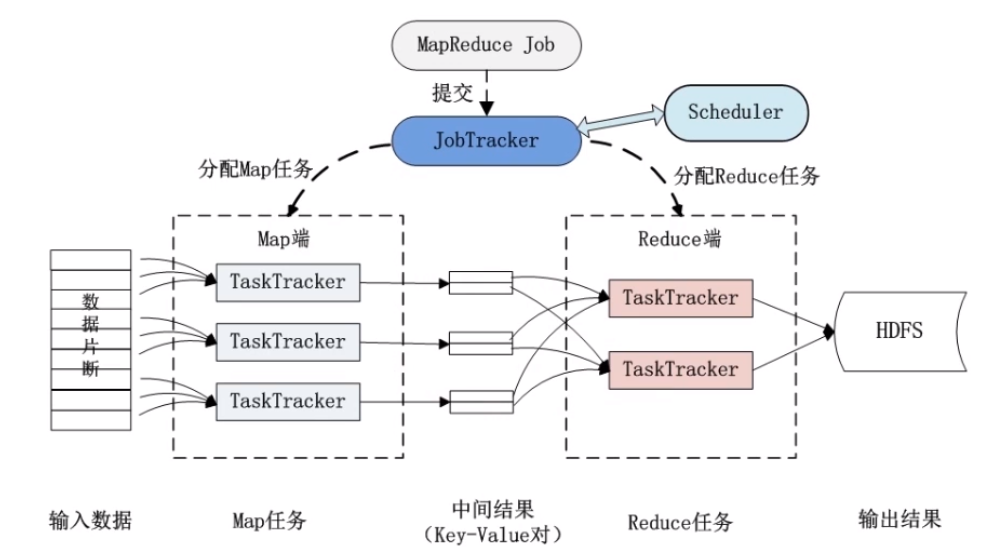
MapReduce分布式工作流程
1.分布式的运算程序往往需要分成至少2个阶段
MapReduce的第一阶段是Map,运行的实例叫Map Task,第二阶段是Reduce,运行的实例叫Reduce Task。每个Task只需要完成后把文件输出到自己的工作目录即可。
2.第一阶段的Task并发实例各司其职,各自为政,互不相干,完全并行
3.第二阶段的Task并发实例互不相干,但是他们的数据以来于上一阶段的所有Task并发实例的输出
4.MapReduce编程模型,只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能来多个mapreduce程序,串行运行
MapReduce容错机制
总结
以上知识体系基本能解决一下几个问题了:
Hadoop- MapReduce分布式计算框架原理的更多相关文章
- 【hadoop】MapReduce分布式计算框架原理
PS:实操部分就省略了哈,准备最近好好看下理论这块,其实我是比较懒得哈!!! <?>MapReduce的概述 MapReduce是一种计算模型,进行大数据量的离线计算.MapReduce实 ...
- hadoop MapReduce Yarn运行机制
原 Hadoop MapReduce 框架的问题 原hadoop的MapReduce框架图 从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路: 首先用户程序 (JobClient) ...
- [转载] Hadoop MapReduce
转载自http://blog.csdn.net/yfkiss/article/details/6387613和http://blog.csdn.net/yfkiss/article/details/6 ...
- python - hadoop,mapreduce demo
Hadoop,mapreduce 介绍 59888745@qq.com 大数据工程师是在Linux系统下搭建Hadoop生态系统(cloudera是最大的输出者类似于Linux的红帽), 把用户的交易 ...
- Hadoop mapreduce框架简介
传统hadoop MapReduce架构(老架构) 从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路: 1.首先用户程序 (JobClient) 提交了一个 job,job ...
- 简述MapReduce计算框架原理
1. MapReduce基本编程模型和框架 1.1 MapReduce抽象模型 大数据计算的核心思想是:分而治之.如下图所示.把大量的数据划分开来,分配给各个子任务来完成.再将结果合并到一起输出.注: ...
- [转] hadoop MapReduce实例解析-非常不错,讲解清晰
来源:http://blog.csdn.net/liuxiaochen123/article/details/8786715?utm_source=tuicool 2013-04-11 10:15 4 ...
- Hadoop MapReduce 一文详解MapReduce及工作机制
@ 目录 前言-MR概述 1.Hadoop MapReduce设计思想及优缺点 设计思想 优点: 缺点: 2. Hadoop MapReduce核心思想 3.MapReduce工作机制 剖析MapRe ...
- Hadoop MapReduce 保姆级吐血宝典,学习与面试必读此文!
Hadoop 涉及的知识点如下图所示,本文将逐一讲解: 本文档参考了关于 Hadoop 的官网及其他众多资料整理而成,为了整洁的排版及舒适的阅读,对于模糊不清晰的图片及黑白图片进行重新绘制成了高清彩图 ...
随机推荐
- 成功者的特点 VS 失败者的特点
- CentOS SVN 服务器搭建
源码目录:/home/user/project 工程名:project 工程目录:/source/svn/project 访问地址:svn://ip/project 一. 安装svn yum inst ...
- Hibernate4.3.6 Final+Spring3.0.5配置出错提示及解决方法
1. Caused by: org.hibernate.cache.NoCacheRegionFactoryAvailableException: Second-level cache is used ...
- (四)DOM对象和jQuery对象
学习jQuery,需要搞清楚DOM对象和jQuery对象的关系与区别,因为两者的方法并不共用,如果搞不清楚对象类型就会导致调用错误的方法. DOM(Document Object Model)称为文档 ...
- (二)关于jQuery
jQuery是一个快速.简洁的JavaScript框架,是继Prototype之后又一个优秀的JavaScript代码库(或JavaScript框架).jQuery设计的宗旨是“write Less, ...
- 【转载】ASP.Net请求处理机制初步探索之旅 - Part 3 管道
开篇:上一篇我们了解了一个ASP.Net页面请求的核心处理入口,它经历了三个重要的入口,分别是:ISAPIRuntime.ProcessRequest().HttpRuntime.ProcessReq ...
- 解决phpmyadmin导入大数据库出现一系列问题
在用phpmyadmin导入mysql数据库文件时,往往超过2M就会提示文件大,导入不成功.这时我们打开phpmyadmin-->libraries-->config.default.ph ...
- 个人笔记-CSS
http://localhost:1081/sdfsdfs/config-browser/actionNames.action 超出容器文字隐藏 .hiddenoverflowtext { width ...
- php通过curl下载远程图片实例
<?php $url = 'http://mf1905.com/upload/video_img/df3074c98ec5124ad47c52ff59f74e04_middle.jpeg'; f ...
- 8148之更换摄像头出现异常---REISZER OVERFLOW OCCURED: RESTARTING
my iss config as: rsz_reg->SRC_VSZ = 1079;//715; rsz_reg->SRC_HSZ = 1919;//1277; rszA_reg ...