ELK学习之Logstash+Kafka篇
上一篇介绍了一下Logstash的数据处理过程以及一些基本的配置功能,同时也提到了Logstash作为一个数据采集端,支持对接多种输入数据源,其中就包括Kafka。那么这次的学习不妨研究一下Logstash如何接收Kafka输入的数据,并与日志中的数据进行统一的处理。
首先在Logstash的配置文件中配置Kafka的数据源(因为篇幅原因,Kafka和ZooKeeper的安装部署就不做介绍了):
input {
file {
path => "D:/logstash-7.14.1/test-log/test.log"
start_position => beginning
}
kafka {
bootstrap_servers => "localhost:9092"
topics => "test_topic"
}
}
如上方所示,我们在上一篇的配置文件中追加了Kafka的地址以及主题用来订阅与消费,input插件中kafka项的详细信息也如上一篇所说,可以在官网上进行查看,https://www.elastic.co/guide/en/logstash/current/plugins-inputs-kafka.html#plugins-inputs-kafka-topics
接下来需要一个生产者往Kafka推送数据以供Logstash端采集,那么新增一个Kafka的测试工程来实现,代码如下:
String server = "127.0.0.1:9092";
String topic = "test_topic"; Properties props = new Properties();
props.put("bootstrap.servers", server);
props.put("transactional.id", "my-transactional-id"); KafkaCallback callback = new KafkaCallback(); Producer<String, String> producer = new KafkaProducer<>(props, new StringSerializer(), new StringSerializer());
producer.initTransactions();
try {
producer.beginTransaction();
for (int i = 0; i < 5; i++) {
producer.send(new ProducerRecord<String, String>("test_topic", Integer.toString(i), "093124." + (597 + i) + "[0][28412]:[5]FindResponseByPage[fund_account=900010328]"), callback);
}
producer.commitTransaction();
} catch (KafkaException e) {
producer.abortTransaction();
}
producer.close();
回调类KafkaCallback的代码也贴一下,主要就是接收一下应答并打印分配的偏移量以及存储的分区信息:
public class KafkaCallback implements Callback {
public void onCompletion(RecordMetadata metadata, Exception e) {
if (e != null)
e.printStackTrace();
SimpleDateFormat df = new SimpleDateFormat("HH:mm:ss.SSS");
System.out.println("[" + df.format(new Date()) + "]partition: " + metadata.partition() + ", offset: " + metadata.offset());
}
}
启动Logstash后也把Kafka的生产者小程序给run起来:
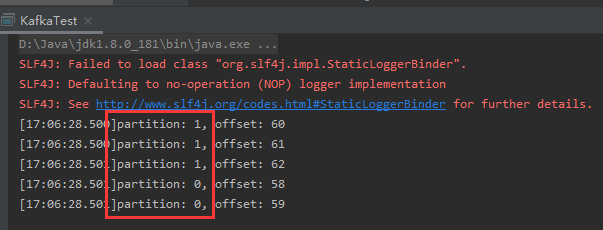
看到消息已经成功推送到Kafka,那么再看下Logstash是否成功收到:
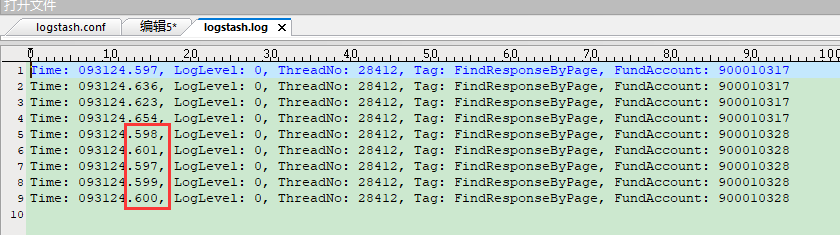
从输出日志中可以看到Logstash从Kafka消费成功,并且来自两个数据源的信息统一进行了输出。不过从上方的两张截图来看,Kafka的消息被发送到了不同的分区,因此Logstash消费时出现了乱序。
这时就引入了两个问题:
1. 从Kafka拉取的数据格式和日志中的数据格式不统一怎么办?
2. Kafka仅在分区内保证顺序,Logstash如果对顺序有着严格要求,怎么办?
首先我们来看第一个问题,不同的数据源数据格式不统一其实是个大概率的事情。那么是否可以针对不同的数据源进行不同的grok分析呢?没找到相关的资料能够支持这种区分的配置,只能通过grok的多match规则顺序执行(第一条失败了会执行第二条)来勉强达到要求。不过进一步考虑下来,架构上可以采用多个Logstash分别来进行不同数据源的信息采集,进行一个数据的初步整理后再分发到下游的ElasticSearch。这样部署上更加灵活,在对各个Logstash的节点进行配置时的限制也会更少。
要回答第二个问题,首先需要了解Kafka为什么会有分区的概念。Kafka对同一个topic支持设置多个分区,主要是为了能够将一个topic的数据处理水平扩展到位于多台服务器的broker中以此提升性能。那么如果说需要对接的系统仅仅是从侵入性考虑不愿意让日志采集直接对接日志或者数据库,而是通过Kafka这种消息中间件来进行解耦,那么专门用来进行日志采集的主题可以设置为只有1个分区。
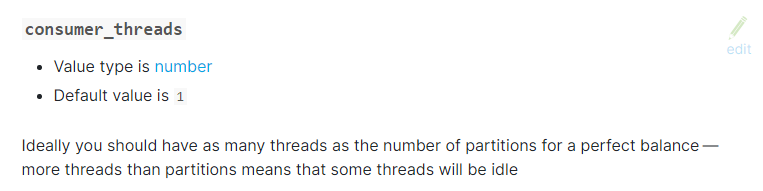
查看官网,发现input-kafka插件有一个配置项叫做consumer_threads,也就是消费者线程数。那么即便是Kafka的对应主题配置了1个分区,还需要将消费者线程数配置为1,否则同一个消费者组内的多个消费者来拉取同一分区内的数据也没有办法做到顺序。不过该配置项默认值就是1,不太容易踩到这个坑。
综上所述,如果对于消费的数据有严格的顺序要求,消息中间件不妨选用RabbiMQ,Logstash本身也提供了对接RabbitMQ的插件。另外,在对接不同数据源时可以采用多Logstash服务进行区分采集的部署方式。
ELK学习之Logstash+Kafka篇的更多相关文章
- ELK学习之Logstash篇
Logstash在ELK这一整套解决方案中作为数据采集终端,支持对接Kafka.数据库(MySQL.Oracle).文件等等. 而在Logstash内部的数据流转,主要经过三个环节:input -&g ...
- ELK学习笔记之Logstash详解
0x00 Logstash概述 官方介绍:Logstash is an open source data collection engine with real-time pipelining cap ...
- ELK 性能(1) — Logstash 性能及其替代方案
ELK 性能(1) - Logstash 性能及其替代方案 介绍 当谈及集中日志到 Elasticsearch 时,首先想到的日志传输(log shipper)就是 Logstash.开发者听说过它, ...
- ELK stack elasticsearch/logstash/kibana 关系和介绍
ELK stack elasticsearch 后续简称ES logstack 简称LS kibana 简称K 日志分析利器 elasticsearch 是索引集群系统 logstash 是日志归集集 ...
- kafka学习2:kafka集群安装与配置
在前一篇:kafka学习1:kafka安装 中,我们安装了单机版的Kafka,而在实际应用中,不可能是单机版的应用,必定是以集群的方式出现.本篇介绍Kafka集群的安装过程: 一.准备工作 1.开通Z ...
- Java工程师学习指南(中级篇)
Java工程师学习指南 中级篇 最近有很多小伙伴来问我,Java小白如何入门,如何安排学习路线,每一步应该怎么走比较好.原本我以为之前的几篇文章已经可以解决大家的问题了,其实不然,因为我写的文章都是站 ...
- 从零开始学习jQuery (一) 入门篇
本系列文章导航 从零开始学习jQuery (一) 入门篇 一.摘要 本系列文章将带您进入jQuery的精彩世界, 其中有很多作者具体的使用经验和解决方案, 即使你会使用jQuery也能在阅读中发现些 ...
- RabbitMQ学习总结 第三篇:工作队列Work Queue
目录 RabbitMQ学习总结 第一篇:理论篇 RabbitMQ学习总结 第二篇:快速入门HelloWorld RabbitMQ学习总结 第三篇:工作队列Work Queue RabbitMQ学习总结 ...
- [原]零基础学习视频解码之android篇系列文章
截止今天,<零基础学习视频解码系列文章>.<零基础学习在Android进行SDL开发系列文章>以及<零基础学习视频解码之android篇>系列文章基本算是告一段落了 ...
随机推荐
- 【Java经验分享篇01】小白如何开始学会看开源项目?
目录 前言 1.理解开源 1.1.什么是开源? 1.2.开源的定义 1.2.1.开源软件优点 1.2.2.经典开源软件案例 1.3.关于开源协议 1.3.1.如何选择开源协议 2.如何查找开源项目 2 ...
- Apereo CAS 4.1 反序列化命令执行漏洞
命令执行 java -jar apereo-cas-attack-1.0-SNAPSHOT-all.jar CommonsCollections4 "touch /tmp/success&q ...
- ClickHouse入门笔记
ClickHouse笔记 目录 ClickHouse笔记 第 1 章 ClickHouse 入门 列式储存的好处: 第 2 章 ClickHouse 的安装 第 3 章 数据类型 整型 浮点型 布尔型 ...
- 初探Docker CentOS 7.9 2009 Mini 操作系统环境初始化 和Docker初始化
初探docker 什么是docker?docker就是一种虚拟化技术,将一个服务虚拟化成一个拥有操作系统内核作为基石的快速使用服务.不用担心环境不同服务效果 不同. docker 官网可以从中央仓库中 ...
- shell的图形排列
目录 一.矩形 二.直角三角形 三.倒直角三角形 四.靠右的直角三角形 五.等腰三角形 六.平行四边形 七.等腰梯形 八.菱形 九.可变动菱形 一.矩形 二.直角三角形 三.倒直角三角形 四.靠右的直 ...
- 阿里面试官:Android中binder机制的实现原理及过程?
Binder 是 Android 系统中非常重要的组成部分.Android 系统中的许多功能建立在 Binder 机制之上.在这篇文章中,我们会对 Android 中的 Binder 在系统架构中的作 ...
- postman 常见异常问题的处理
1.postman一直转圈打不开的问题 一般这种问题是因为缓存过多,所以这里需要清理下缓存文件,即:删除%appdata%目录下的postman文件,删除之后可恢复正常. 这个文件夹是隐藏的,对于文件 ...
- Python爬虫学习——1.爬虫入门
HTTP和HTTPS HTTP协议(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收 HTML页面的方法. HTTPS(Hypertext Transfer ...
- chromium调试技巧
调试技巧: 1.多进程不方便跟踪渲染进程,单渲染进程的设置方法 command_line->AppendSwitchWithValue("--renderer-process- ...
- Lab: 2FA bypass using a brute-force attack:暴力破解双重验证靶场复盘(困难级别)
靶场内容: This lab's two-factor authentication is vulnerable to brute-forcing. You have already obtained ...