[BD] Storm
什么是实时计算
- 离线计算:批处理,代表MapReduce、Spark Core,采集数据Sqoop、Flume
- 实时计算:源源不断,代表Storm等,采集数据Flume
- 框架
- Apache Storm
- Spark Streaming:把流式数据转换成离散数据,本质是离线计算
- JStrom:阿里基于Strom开发
- Flink
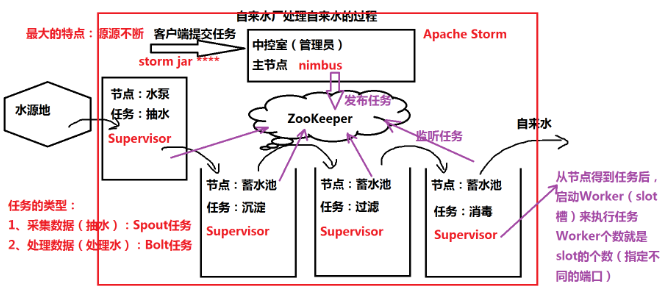
环境搭建
- 伪分布
- storm nimbus &
- storm supervisor &
- storm ui &
- 全分布
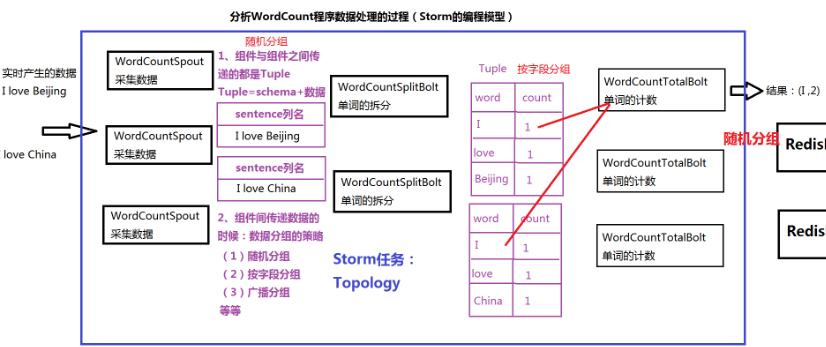
编程案例 WordCount
- 启用Debug,日志查看器,在网页上查看数据
- "topology.eventlogger.executors": 1
- /root/training/apache-storm-1.0.3/examples/storm-starter
- storm jar storm-starter-topologies-1.0.3.jar org.apache.storm.starter.WordCountTopology MyWC
- storm logviewer &
WordCountTopology.java


1 package demo.wc;
2
3 import org.apache.storm.Config;
4 import org.apache.storm.LocalCluster;
5 import org.apache.storm.StormSubmitter;
6 import org.apache.storm.generated.StormTopology;
7 import org.apache.storm.hdfs.bolt.HdfsBolt;
8 import org.apache.storm.hdfs.bolt.format.DefaultFileNameFormat;
9 import org.apache.storm.hdfs.bolt.format.DelimitedRecordFormat;
10 import org.apache.storm.hdfs.bolt.rotation.FileSizeRotationPolicy;
11 import org.apache.storm.hdfs.bolt.rotation.FileSizeRotationPolicy.Units;
12 import org.apache.storm.hdfs.bolt.sync.CountSyncPolicy;
13 import org.apache.storm.redis.bolt.RedisStoreBolt;
14 import org.apache.storm.redis.common.config.JedisPoolConfig;
15 import org.apache.storm.redis.common.mapper.RedisDataTypeDescription;
16 import org.apache.storm.redis.common.mapper.RedisStoreMapper;
17 import org.apache.storm.topology.IRichBolt;
18 import org.apache.storm.topology.TopologyBuilder;
19 import org.apache.storm.tuple.Fields;
20 import org.apache.storm.tuple.ITuple;
21
22
23 //任务的主程序,创建任务:Topology
24 public class WordCountTopology {
25
26 public static void main(String[] args) throws Exception {
27 TopologyBuilder builder = new TopologyBuilder();
28
29 //设置任务的spout组件
30 builder.setSpout("wordcount_spout", new WordCountSpout());
31
32 //设置任务的单词拆分的bolt组件,是随机分组
33 builder.setBolt("wordcount_split", new WordCountSplitBolt()).shuffleGrouping("wordcount_spout");
34
35 //设置任务的单词计数的bolt组件,是按字段分组
36 builder.setBolt("wordcount_total", new WordCountTotalBolt()).fieldsGrouping("wordcount_split", new Fields("word"));
37
38 //设置任务的第三个Bolt组件,将结果保存到Redis,直接使用Storm提供的BOlt
39 //builder.setBolt("wordcount_redis", createRedisBolt()).shuffleGrouping("wordcount_total");
40
41 //设置任务的第三个Bolt组件,将结果保存到HDFS(文件),直接使用Storm提供的Bolt
42 builder.setBolt("wordcount_hdfs", createHDFSBolt()).shuffleGrouping("wordcount_total");
43
44 //设置任务的第三个Bolt组件,将结果保存到HBase中
45 //builder.setBolt("wordcount_hbase", new WordCountHBaseBolt()).shuffleGrouping("wordcount_total");
46
47
48 //创建一个任务:Topology
49 StormTopology topology = builder.createTopology();
50
51 //创建一个Config对象,保存配置信息
52 Config conf = new Config();
53
54 /*
55 * 提交Storm的任务有两种方式
56 * 1、本地模式
57 * 2、集群模式
58 */
59 LocalCluster cluster = new LocalCluster();
60 cluster.submitTopology("MyWordCount", conf, topology);
61
62 // StormSubmitter.submitTopology("MyWordCount", conf, topology);
63
64 }
65
66 private static IRichBolt createHDFSBolt() {
67 // 将结果保存到HDFS 文件
68
69 HdfsBolt bolt = new HdfsBolt();
70 //设置HDFS的相关配置信息
71 //HDFS的位置:NameNode的地址
72 bolt.withFsUrl("hdfs://192.168.174.111:9000");
73
74 //设置保存的HDFS的目录
75 bolt.withFileNameFormat(new DefaultFileNameFormat().withPath("/stormdata"));
76
77 //保存的是<key value>,设置数据保存到文件的时候,分隔符 |
78 //举例:<Beijing,10> ----> 结果: Beijing|10
79 bolt.withRecordFormat(new DelimitedRecordFormat().withFieldDelimiter("|"));
80
81 //流式处理,多大的数据生成一个文件?
82 //每5M的数据生成一个文件
83 bolt.withRotationPolicy(new FileSizeRotationPolicy(5.0f, Units.MB));
84
85 //当输出tuple达到了一定大小,就会跟HDFS进行一次同步
86 bolt.withSyncPolicy(new CountSyncPolicy(1000));
87
88
89 return bolt;
90 }
91
92 private static IRichBolt createRedisBolt() {
93 //把单词计数是结果保存到Redis
94
95 //创建Redis的连接池
96 JedisPoolConfig.Builder builder = new JedisPoolConfig.Builder();
97 builder.setHost("192.168.174.111");
98 builder.setPort(6379);
99 JedisPoolConfig poolConfig = builder.build();
100
101 //参数:StoreMapper:用于指定存入Redis中的数据格式
102 return new RedisStoreBolt(poolConfig, new RedisStoreMapper() {
103
104 @Override
105 public RedisDataTypeDescription getDataTypeDescription() {
106 //定义Redis中的数据类型:WordCount采用什么数据类型?
107 //使用Hash集合
108 return new RedisDataTypeDescription(RedisDataTypeDescription.RedisDataType.HASH,
109 "wordcount");
110 }
111
112 @Override
113 public String getValueFromTuple(ITuple tuple) {
114 // 从上一个Tuple中取出值:频率
115 return String.valueOf(tuple.getIntegerByField("total"));
116 }
117
118 @Override
119 public String getKeyFromTuple(ITuple tuple) {
120 // 从上一个Tuple中取出key:单词
121 return tuple.getStringByField("word");
122 }
123 });
124 }
125 }
WordCountSpout.java
1 package demo.wc;
2
3 import java.util.Map;
4 import java.util.Random;
5
6 import org.apache.storm.spout.SpoutOutputCollector;
7 import org.apache.storm.task.TopologyContext;
8 import org.apache.storm.topology.OutputFieldsDeclarer;
9 import org.apache.storm.topology.base.BaseRichSpout;
10 import org.apache.storm.tuple.Fields;
11 import org.apache.storm.tuple.Values;
12 import org.apache.storm.utils.Utils;
13
14 //第一级组件,作为任务的Spout组件,来采集数据
15 //模拟一些数据,随机产生数据
16 public class WordCountSpout extends BaseRichSpout {
17
18 //定义我们要产生的数据
19 private String[] datas = {"I love Beijing","I love China","Beijing is the capital of China"};
20
21 //定义一个变量来保存输出流
22 private SpoutOutputCollector collector;
23
24 @Override
25 public void nextTuple() {
26 //每隔2秒采集一次
27 Utils.sleep(2000);
28
29 // 由Storm的框架调用,用于如何接受数据
30 //产生一个3以内的随机数
31 int random = (new Random()).nextInt(3);
32 //数据
33 String data = datas[random];
34
35 //把数据发送给下一个组件
36 //数据一定要遵循schema的结构
37 System.out.println("采集的数据是:" + data);
38 this.collector.emit(new Values(data));
39 }
40
41 @Override
42 public void open(Map arg0, TopologyContext arg1, SpoutOutputCollector collector) {
43 //相当于Spout初始化方法
44 //参数:SpoutOutputCollector collector 相当于是输出流
45 this.collector = collector;
46 }
47
48 @Override
49 public void declareOutputFields(OutputFieldsDeclarer declare) {
50 // 申明Tuple的格式,是Schema
51 declare.declare(new Fields("sentence"));
52 }
53 }
WordCountSplitBolt.java
1 package demo.wc;
2
3 import java.util.Map;
4
5 import org.apache.storm.task.OutputCollector;
6 import org.apache.storm.task.TopologyContext;
7 import org.apache.storm.topology.OutputFieldsDeclarer;
8 import org.apache.storm.topology.base.BaseRichBolt;
9 import org.apache.storm.tuple.Fields;
10 import org.apache.storm.tuple.Tuple;
11 import org.apache.storm.tuple.Values;
12
13 //第二级组件,是bolt组件,用于单词的拆分
14 public class WordCountSplitBolt extends BaseRichBolt{
15
16 private OutputCollector collector;
17
18 @Override
19 public void execute(Tuple tuple) {
20 //如何处理上一级组件发来的数据: I love Beijing
21 String data = tuple.getStringByField("sentence");
22
23 //分词
24 String[] words = data.split(" ");
25
26 //输出
27 for(String w:words){
28 collector.emit(new Values(w,1));
29 }
30 }
31
32 @Override
33 public void prepare(Map arg0, TopologyContext arg1, OutputCollector collector) {
34 // 对Bolt进行初始化
35 this.collector = collector;
36 }
37
38 @Override
39 public void declareOutputFields(OutputFieldsDeclarer declare) {
40 //申明Tuple的格式
41 declare.declare(new Fields("word","count"));
42
43 }
44 }
WordCountTotalBolt.java
1 package demo.wc;
2
3 import java.util.HashMap;
4 import java.util.Map;
5
6 import org.apache.storm.task.OutputCollector;
7 import org.apache.storm.task.TopologyContext;
8 import org.apache.storm.topology.OutputFieldsDeclarer;
9 import org.apache.storm.topology.base.BaseRichBolt;
10 import org.apache.storm.tuple.Fields;
11 import org.apache.storm.tuple.Tuple;
12 import org.apache.storm.tuple.Values;
13
14 //第三级组件,是bolt组件,用于单词的计数
15 public class WordCountTotalBolt extends BaseRichBolt {
16
17 private OutputCollector collector;
18
19 //定义一个Map集合来保存结果
20 private Map<String, Integer> result = new HashMap<>();
21
22 @Override
23 public void execute(Tuple tuple) {
24 // 对每个单词进行计数
25 //取出数据
26 String word = tuple.getStringByField("word");
27 int count = tuple.getIntegerByField("count");
28
29 if(result.containsKey(word)){
30 //如果包含,进行累加
31 int total = result.get(word);
32 result.put(word, total+count);
33 }else{
34 //这个单词第一次出现
35 result.put(word, count);
36 }
37
38 //打印在屏幕上
39 System.out.println("统计的结果是: " + result);
40
41 //把结果继续发送给下一个bolt组件: (单词,频率)
42 this.collector.emit(new Values(word,result.get(word)));
43 }
44
45 @Override
46 public void prepare(Map arg0, TopologyContext arg1, OutputCollector collector) {
47 // TODO Auto-generated method stub
48 this.collector = collector;
49 }
50
51 @Override
52 public void declareOutputFields(OutputFieldsDeclarer declare) {
53 // TODO Auto-generated method stub
54 declare.declare(new Fields("word","total"));
55 }
56 }

编程模型
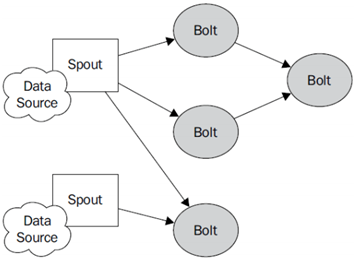
- Topology:Storm中运行的一个实时应用程序
- Stream:数据流向
- Spout:在一个Topology中获取源数据流的组件
- Bolt:接收数据然后执行处理的组件,可级联
- Tuple:一次消息传递的基本单元
- StreamGroup:数据分组策略
- 随机分组:1-2之间
- 按字段分组:2-3之间
- 广播分组
流式计算架构
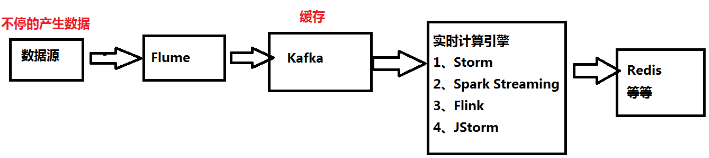
- Flume:获取数据
- Kafka:临时保存数据
- Storm:计算数据
- Redis:保存数据
原理分析
- Storm在ZK中保存的数据

- Storm提交任务的过程
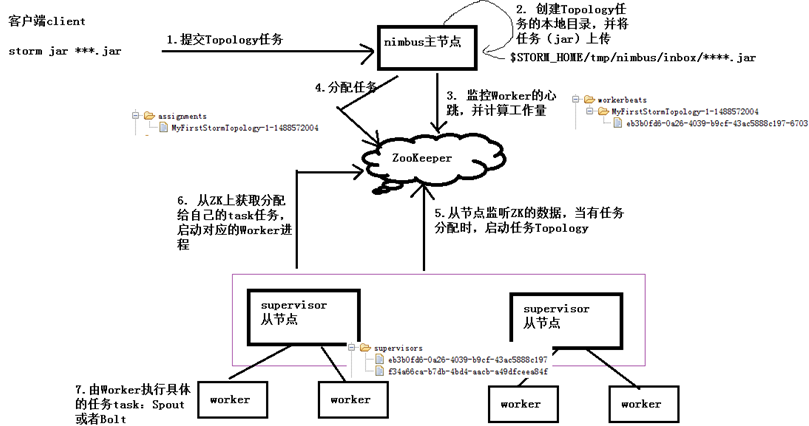
- Storm内部通信的机制
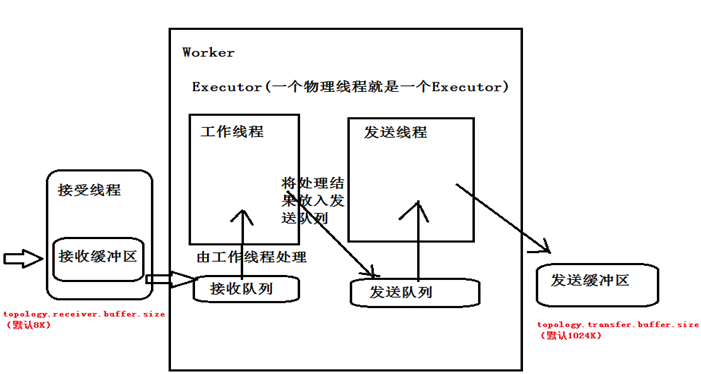
外部集成
- Redis
- 添加依赖jar包,在WordCountTopology中编写Bolt组件
- 创建连接池
- JDBC
- HDFS:storm-hdfs***.jar
- HBase:自己开发一个Bolt组件
- Kafka
- Hive
参考
大数据实时计算框架
https://www.csdn.net/gather_21/MtTacgxsMDI1Mi1ibG9n.html
[BD] Storm的更多相关文章
- Redis安装,mongodb安装,hbase安装,cassandra安装,mysql安装,zookeeper安装,kafka安装,storm安装大数据软件安装部署百科全书
伟大的程序员版权所有,转载请注明:http://www.lenggirl.com/bigdata/server-sofeware-install.html 一.安装mongodb 官网下载包mongo ...
- 三:Storm设计一个Topology用来统计单词的TopN的实例
Storm的单词统计设计 一:Storm的wordCount和Hadoop的wordCount实例对比
- Storm如何保证可靠的消息处理
作者:Jack47 PS:如果喜欢我写的文章,欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 本文主要翻译自Storm官方文档Guaranteeing messag ...
- Storm
2016-11-14 22:05:29 有哪些典型的Storm应用案例? 数据处理流:Storm可以用来处理源源不断流进来的消息,处理之后将结果写入到某个存储中去.不像其它的流处理系统,Storm不 ...
- Storm介绍(一)
作者:Jack47 PS:如果喜欢我写的文章,欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 内容简介 本文是Storm系列之一,介绍了Storm的起源,Storm ...
- 理解Storm并发
作者:Jack47 PS:如果喜欢我写的文章,欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 注:本文主要内容翻译自understanding-the-parall ...
- Storm构建分布式实时处理应用初探
最近利用闲暇时间,又重新研读了一下Storm.认真对比了一下Hadoop,前者更擅长的是,实时流式数据处理,后者更擅长的是基于HDFS,通过MapReduce方式的离线数据分析计算.对于Hadoop, ...
- Storm内部的消息传递机制
作者:Jack47 转载请保留作者和原文出处 欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 一个Storm拓扑,就是一个复杂的多阶段的流式计算.Storm中的组件 ...
- Storm介绍(二)
作者:Jack47 转载请保留作者和原文出处 欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 本文是Storm系列之一,主要介绍Storm的架构设计,推荐读者在阅读 ...
随机推荐
- oCPC中转化率模型与校准
翻看日历时间已经来到了2021年,也是共同战役的第二年,许久没有更新文章了,在与懒惰进行过几次斗争都失利之后,今天拿出打工人最后的倔强,终于收获了一场胜利.闲话不多说,今天咱们重点聊聊oCPC中转化率 ...
- 201871030102_崔红梅 实验三 结对项目—《D{0-1}KP 实例数据集算法实验平台》项目报告
项目 内容 课程班级博客链接 班级博客 这个作业要求链接 作业要求 我的课程学习目标 1.体验软件项目开发中的两人合作,练习结对编程2. 掌握Github协作开发程序的操作方法.3.阅读<现代软 ...
- 【2w字干货】ArrayList与LinkedList的区别以及JDK11中的底层实现
1 概述 本文主要讲述了ArrayList与LinkedList的相同以及不同之处,以及两者的底层实现(环境OpenJDK 11.0.10). 2 两者区别 在详细介绍两者的底层实现之前,先来简单看一 ...
- [ERROR]: gitstatus failed to initialize.
1 问题描述 Manjaro升级后,zsh的主题p10k出现的问题. Your git prompt may disappear or become slow. Run the following c ...
- 4. Linux-startx命令
Linux系统startx命令的功能和使用方法 Linux系统命令startx的功能很简单,就是启动X Window的服务这一项,没有其他的了.其实startx命令启动的是xinit,然后再由xini ...
- 嗨,你知道吗,Spring还有这些高级特性!
目录 Spring介绍 设计理念 核心组件的协同工作 设计模式的应用 代理模式 策略模式 特性应用 事件驱动编程 异步执行 定时任务 日常开发使用非常多的Spring,它的设计理念是什么呢?有哪些核心 ...
- zabbix容器化安装及监控docker应用
一.zabbix agent2 介绍 从Zabbix 4.4之后,官方推出了Zabbix Agent 2,意味着zabbix 不在只是物理机监控的代名词,现在你可以使用Go为Zabbix编写插件,来监 ...
- 已知a=a
高中时酷爱经济学. 薄薄的纸片竟然决定着整个社会的运转趋势,整个人生的起伏也是靠着纸片来衡量的. 可笑的是你怎么闹腾也逃不过康波周期等一系列命中注定的路线,即,已知a=a,那么a等于且仅等于a. 所有 ...
- 02- linux目录和文件的基础操作
本博文纲要 linux目录结构 绝对路径与相对路径 linux目录常用操作 linux文件常用操作 Q/A Windows文件系统特点 -文件系统是操作系统的一个功能,用户管理目录和文件 -Windo ...
- 1.5.1- HTML之相对路径
网页需要图片,首先需要找到它.实际工作中,通常新建一个文件夹专门用于存放图像文件,这时插入图像,就需要采用"路径"的方式来制定图像文件的位置.路径可以分为相对路径与绝对路径. 相对 ...