Nebula 2.5.0安装过程及遇到的坑
2021年8月23日,Nebula 发布了最新版本:2.5.0,正好赶上新环境部署,记录一下安装过程及遇到的坑:
一、准备工作
以下安装使用nebula用户,搭建集群模式,一共三台机器:192.168.0.1、192.168.0.2、192.168.0.3
nebula主程序、nebula-console安装在/opt目录
nebula-studio安装在默认目录(/usr/local/nebula-graph-studio)
nebula的数据文件安装在/mnt/data/nebula目录
nebula的日志文件安装在/mnt/resource/nebula目录
将/opt、/mnt所有者改为nebula用户:
1 sudo chown -R nebula.nebula /opt
2 sudo chown -R nebula.nebula /mnt
二、Nebula
2.1 下载安装包
wget https://oss-cdn.nebula-graph.com.cn/package/2.5.0/nebula-graph-2.5.0.el7.x86_64.rpm
2.2 安装rpm包
如果不设置安装路径,默认安装路径为/usr/local/nebula/,此处修改为:/opt/nebula-2.5.0
sudo rpm -ivh --prefix=/opt/nebula-2.5.0 nebula-graph-2.5.0.el7.x86_64.rpm
2.3 建立软连接
切换到/opt目录,执行以下命令:
ln -s nebula-2.5.0 nebula
2.4 修改配置
配置文件在/opt/nebula/etc下:
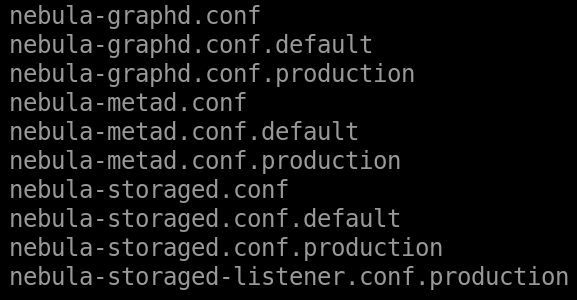
因为是生产环境,可以将其他的配置文件都删了,只保留带“.production”的配置文件,最后要把“.production”扩展名去掉,保证扩展名都是“.conf”

2.4.1 nebula-metad.conf
主要修改点(日志文件路径、日志级别、元数据服务地址、本机IP、数据文件路径):
# The directory to host logging files
--log_dir=/mnt/resource/nebula/meta # Log level, 0, 1, 2, 3 for INFO, WARNING, ERROR, FATAL respectively
--minloglevel=1 # Comma separated Meta Server addresses
--meta_server_addrs=192.168.0.1:9559,192.168.0.2:9559,192.168.0.3:9559
# Local IP used to identify the nebula-storaged process.
# Change it to an address other than loopback if the service is distributed or
# will be accessed remotely.
--local_ip=192.168.0.1(每个机器设置为本机的实际IP)
# Root data path, here should be only single path for metad
--data_path=/mnt/data/nebula/meta
2.4.2 nebula-graphd.conf
主要修改点(日志文件路径、日志级别、元数据服务地址、本机IP):
# The directory to host logging files
--log_dir=/mnt/resource/nebula/graph # Log level, 0, 1, 2, 3 for INFO, WARNING, ERROR, FATAL respectively
--minloglevel=1 # Comma separated Meta Server addresses
--meta_server_addrs=192.168.0.1:9559,192.168.0.2:9559,192.168.0.3:9559
# Local IP used to identify the nebula-storaged process.
# Change it to an address other than loopback if the service is distributed or
# will be accessed remotely.
--local_ip=192.168.0.1(每个机器设置为本机的实际IP)
2.4.3 nebula-storaged.conf
主要修改点(日志文件路径、日志级别、元数据服务地址、本机IP、数据文件路径):
# The directory to host logging files
--log_dir=/mnt/resource/nebula/storage # Log level, 0, 1, 2, 3 for INFO, WARNING, ERROR, FATAL respectively
--minloglevel=1 # Comma separated Meta Server addresses
--meta_server_addrs=192.168.0.1:9559,192.168.0.2:9559,192.168.0.3:9559
# Local IP used to identify the nebula-storaged process.
# Change it to an address other than loopback if the service is distributed or
# will be accessed remotely.
--local_ip=192.168.0.1(每个机器设置为本机的实际IP)
# Root data path. split by comma. e.g. --data_path=/disk1/path1/,/disk2/path2/
# One path per Rocksdb instance.
--data_path=/mnt/data/nebula/storage
2.5 启动Nebula
切换到每个机器的/opt/nebula/scripts下,执行如下命令:
./nebula.service start all
2.6 查看Nebula每个服务的状态
切换到每个机器的/opt/nebula/scripts下,执行如下命令:
./nebula.service status all
返回信息如下:

三、Nebula-Console
3.1 下载安装包
https://github.com/vesoft-inc/nebula-console/releases
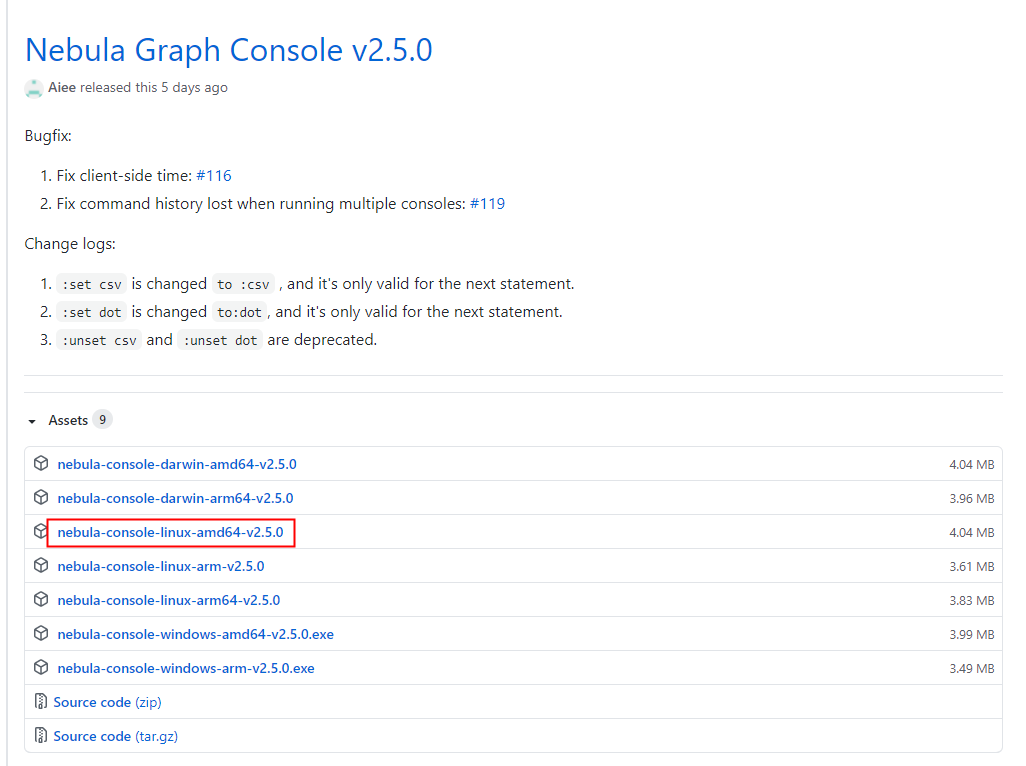
3.2 拷贝到/opt/nebula/scrpts下
3.3 重命名为nebula-console
mv nebula-console-linux-amd64-v2.5.0 nebula-console
3.4 添加可执行权限
chmod +x nebula-console
3.5 连接Nebula
切换到/opt/nebula/scrpts下,执行如下命令:
./nebula-console -addr 127.0.0.1 -port 9669 -u root -p password

四、Nebula-Studio
4.1 依赖安装
安装lsof、node.js,详见本文第五部分:依赖安装
4.2 下载Nebula Studio
https://oss-cdn.nebula-graph.com.cn/nebula-graph-studio/3.0.0/nebula-graph-studio-3.0.0-1.x86_64.rpm
4.3 通过rpm安装Nebula Studio
sudo rpm -i nebula-graph-studio-3.0.0-6.x86_64.rpm
4.4 访问Nebula Studio
在浏览器中访问:http://192.168.0.1:7001/
输入graphd的链接地址及用户名密码
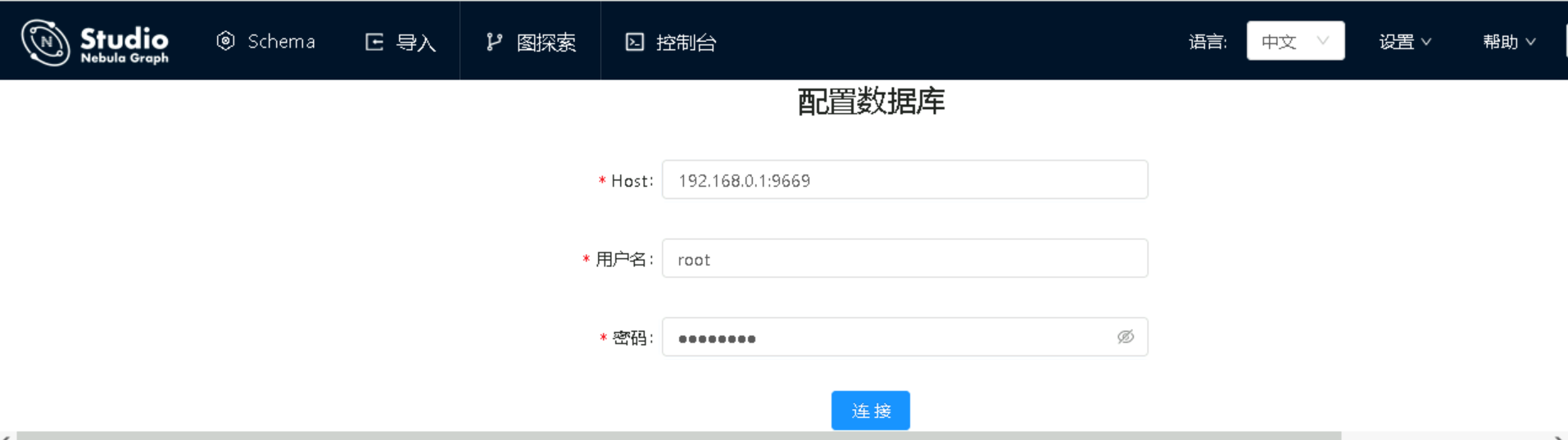
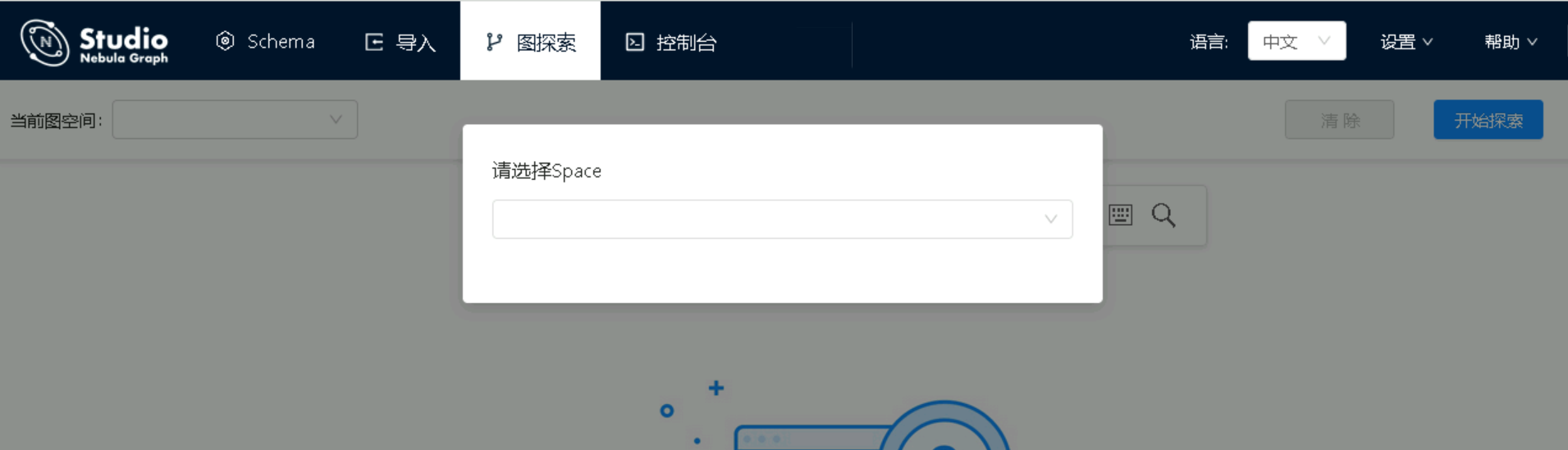
进入studio洁面后,可以选择Space,默认没有Space,需要单独创建一个
五、依赖安装
5.1 安装lsof
已经安装过,此步省略。
5.2 安装Node.js
5.2.1 下载Node.js
官网下载地址:https://nodejs.org/zh-cn/download/
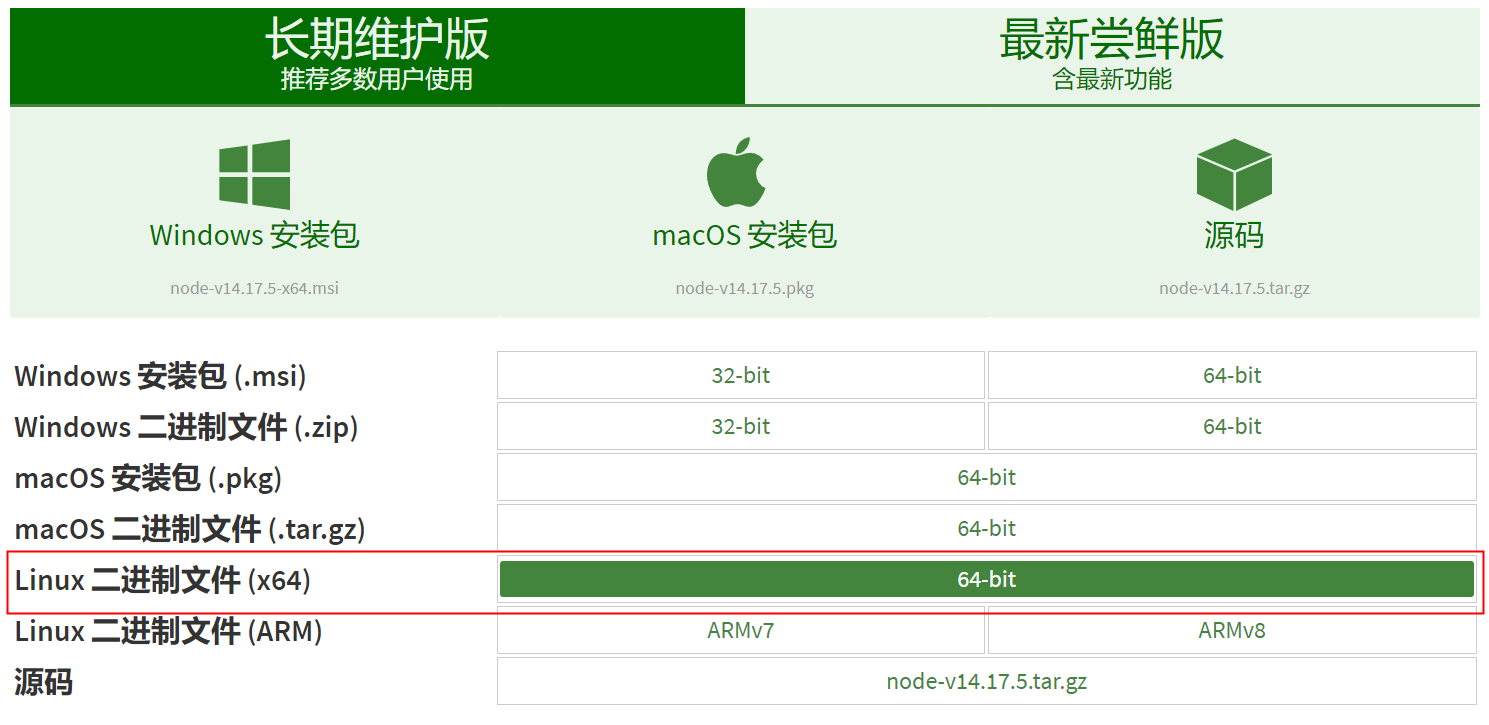
https://nodejs.org/dist/v14.17.5/node-v14.17.5-linux-x64.tar.xz
5.2.2 解压Node.js
需要分两步解压:
xz -d node-v14.17.5-linux-x64.tar.xz tar -xf node-v14.17.5-linux-x64.tar
5.2.2 将Node.js拷贝到/opt底下
5.2.3 对/opt底下的node建立软连接
ln -s node-14.17.5 node
5.2.4 将node添加到环境变量
sudo vi /etc/profile
添加如下:
#Node Env
NODE_HOME=/opt/node
PATH=$PATH:$NODE_HOME/bin
export NODE_HOME PATH
5.2.5 使环境变量生效
source /etc/profile
5.2.6 验证node是否可用
在命令行直接输入:node,返回信息如下:

5.2.7 在/usr/bin下建立对node、npm的软连接
ln -s /opt/node/bin/node /usr/bin/node ln -s /opt/node/bin/npm /usr/bin/npm
六、遇到的坑
6.1 rpm安装完后,不支持自动注册成Linux服务,需要手动切换到安装目录底下的scrpts中
6.2 通过rpm方式安装nebula,支持通过“--prefix”指定安装路径,但是安装nebula-studio时,不支持通过“--prefix”指定安装路径
6.3 安装nebula-studio时,必须得在/usr/bin下建立针对node、npm的软连接,即使将node加入到环境变量了也不认,安装脚本写的不够灵活
6.4 Nebula提供的nodejs的安装链接,不是nodejs的官网链接,不够通用,建议指向nodejs的官网链接:
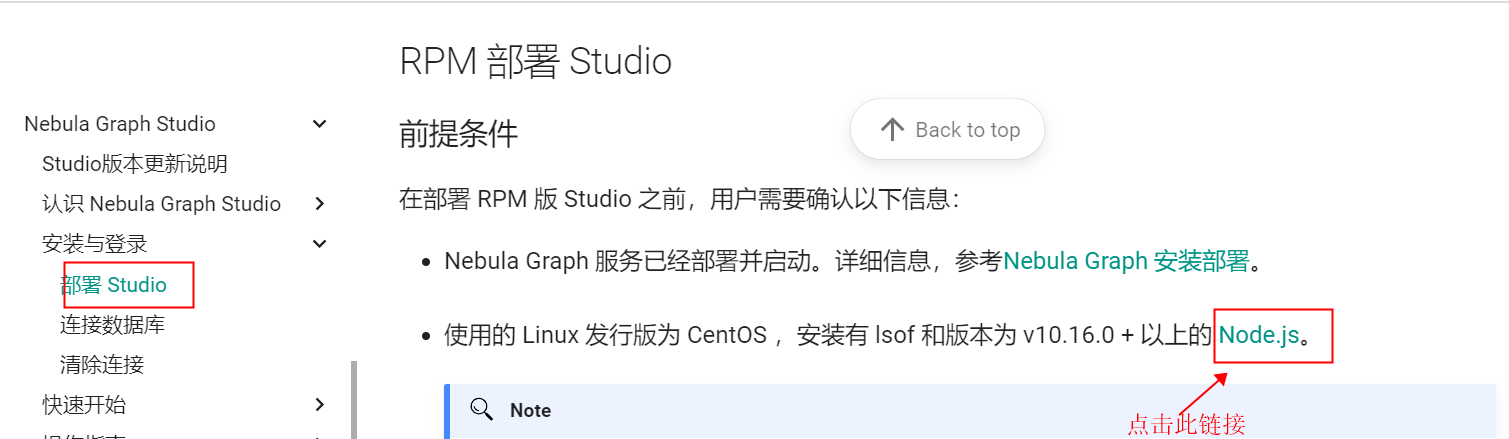
跳转到如下界面:
6.5 nebula-storaged-listener.confg可以不用配置,主要用于跨数据中心,暂时用不到
Nebula 2.5.0安装过程及遇到的坑的更多相关文章
- Oracle Data Integrator 12cR1 (12.1.3.0.0)安装过程
Oracle Data Integrator 12cR1 (12.1.3.0.0)安装过程 下载安装文件 Oracle Data Integrator 12cR1 (12.1.3.0.0) http: ...
- VMware VCSA 6.0安装过程 (转)
VMware VCSA 6.0安装过程(专版) 一.环境准备 VMware vCenter Server Appliance(VCSA)6.0的部署和之前的版本不同,在5.5及之前的版本可以通过 ...
- Mysql 6.0安装过程(截图放不上去)
由于免费,MySQL数据库在项目中用的越来越广泛,而且它的安全性能也特别高,不亚于oracle这样的大型数据库软件.可以简单的说,在一些中小型的项目中,使用MySQL ,PostgreSQL是最佳 ...
- VMware workstation16 中Centos7下MySQL8.0安装过程+Navicat远程连接
1.MySQL yum源安装 2.安装后,首次登录mysql以及密码配置3.远程登录问题(Navicat15为例) 一.CentOS7+MySQL8.0,yum源安装1.安装mysql前应卸载原有my ...
- 分享一下我在mysql5.6+mysql8数据库安装过程中的一些坑!
Mysql5.6安装 下载好安装包后,在bin目录下用cmd打开,输入mysqld install [服务名]新建个服务 在windows+r输入services.msc即可查看服务 怎样使用mysq ...
- HUE安装过程中的一些坑
1. gcc: error: krb5-config:: No such file or directory 执行安装krb5-devel yum provides krb5-config 得到提示: ...
- mini-ndn0.5.0 安装教程 (避免踩坑)
写在前面 首先需要确定一些配置,因为在安装的过程中需要编译一些内容,所以需要提前准备好. 本人之前ubuntu系统可能比较乱,在尝试很多次安装后,仍然失败,所以就直接重装了一下.说一下我自己的一些配置 ...
- Hadoop2.2.0安装过程记录
1 安装环境1.1 客户端1.2 服务端1.3 安装准备 2 操作系统安装2.1.1 BIOS打开虚拟化支持2.1.2 关闭防火墙2.1.3 安装 ...
- source insight 4.0.86.0 安装过程中出现的问题
1.sourceinsight_4.0.86.0-setup.exe 2.sourceinsight4.exe覆盖安装目录中的sourceinsight4.exe 3.导入lic文件 过程中360会将 ...
随机推荐
- 关于SOA和AOP
SOA:面向服务的架构(SOA)是一个组件模型,它将应用程序的不同功能单元(称为服务)通过这些服务之间定义良好的接口和契约联系起来.C/S端框架有WPF,服务端应用程序有WCF.asp.net web ...
- TCP/IP 5层协议簇/协议栈
TCP/IP 5层协议簇/协议栈 数据/PDU 应用层 PC.防火墙 数据段/段Fragment 传输层 防火墙 报文/包/IP包packet 网络层 路由器 帧Frame 数据链路层 交换机.网卡 ...
- dev c++自动添加初始源代码
1.打开 dec v++ 2.工具--编辑器属性 3."代码"选项卡,点击"缺省源" 7.选择"向项目初始源文件插入代码" 8.下面插入下面 ...
- python 读注册表 检测NET版本
from winreg import * import re def subRegKey(key, pattern, patchlist): # 个数 count = QueryInfoKey(key ...
- 大疆M3508、M2006必备CAN总线知识与配置方法
使用大疆M3508.M2006的CAN总线知识与配置方法 目录 使用大疆M3508.M2006的CAN总线知识与配置方法 前言: 0x00 需要额外的CAN收发器!!! 0x01 硬件层面分析 为什么 ...
- bash shell 遍历一个数组
var[@] 数组的一个元素 var=("first" "second" "three") for str in ${var[@]}; d ...
- Ubuntu 18.04 开启 root 账号并允许远程连接
转载:https://blog.csdn.net/u010766726/article/details/105376461 以普通用户登录系统 通过 "终端" 操作 普通用户 – ...
- MySQL中的redo log和undo log
MySQL中的redo log和undo log MySQL日志系统中最重要的日志为重做日志redo log和归档日志bin log,后者为MySQL Server层的日志,前者为InnoDB存储引擎 ...
- 第十三篇 -- 关于C++不支持int
如果是exe的程序的话,DWORD是非法字符,所以需要添加头文件"windows.h"
- js 原始数据类型、引用数据类型
js的数据类型划分方式为 原始数据类型和 引用数据类型 栈: 原始数据类型(Undefined,Null,Boolean,Number.String) 堆: 引用数据类型(对象.数组.函数) 两种类型 ...