MapReduce框架原理-MapTask和ReduceTask工作机制
MapTask工作机制
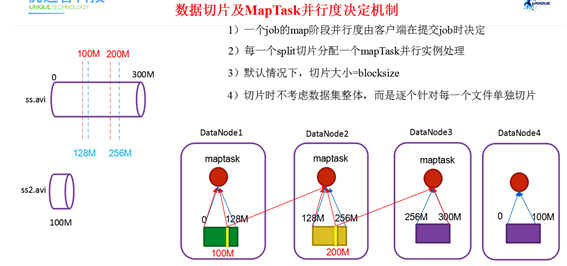
并行度决定机制
1)问题引出
maptask的并行度决定map阶段的任务处理并发度,进而影响到整个job的处理速度。那么,mapTask并行任务是否越多越好呢?
2)MapTask并行度决定机制
一个job的map阶段MapTask并行度(个数),由客户端提交job时的切片个数决定。
切片(逻辑上的切分)大小默认等于128M,和block大小相等,原因是如果不按照block大小进行切分,可能会涉及到一些不同节点之间数据的传输。
MapTask工作机制
总结
- read阶段:读取数并行度决定机制据成key-value
- map阶段:将读取的key-value进行处理,生成新的key-value
- collect阶段:将map的数据写到环形缓冲区(分区)中
- spill溢写阶段:环形缓冲区数据满80%后溢写磁盘,只不过溢写之前需要进行排序
- combine阶段:合并小文件(而不是执行Combiner业务逻辑):归并排序,将一些多次产生的小文件进行合并,形成一个大文件
【注意】MapTask的数量是由切片数决定的,虽然Maptask不能直接设置,但是我们可以通过设置切片个数去完成MapTask数量的指定
详细步骤
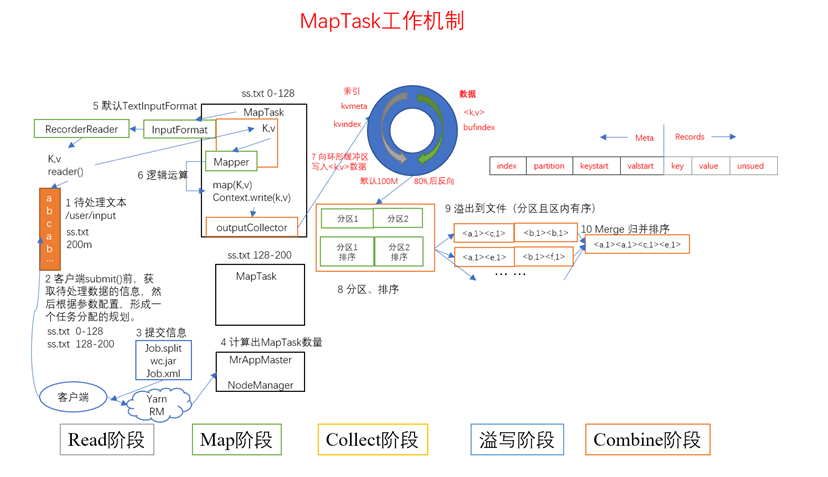
(1)Read阶段:Map Task通过用户编写的RecordReader,从输入InputSplit中解析出一个个key/value。
(2)Map阶段:该节点主要是将解析出的key/value交给用户编写map()函数处理,并产生一系列新的key/value。
(3)Collect收集阶段:在用户编写map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的key/value分区(调用Partitioner),并写入一个环形内存缓冲区中。
(4)Spill阶段:即"溢写",当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。
溢写阶段详情:
步骤1:利用快速排序算法对缓存区内的数据进行排序,排序方式是,先按照分区编号partition进行排序,然后按照key进行排序。这样,经过排序后,数据以分区为单位聚集在一起,且同一分区内所有数据按照key有序。
步骤2:按照分区编号由小到大依次将每个分区中的数据写入任务工作目录下的临时文件output/spillN.out(N表示当前溢写次数)中。如果用户设置了Combiner,则写入文件之前,对每个分区中的数据进行一次聚集操作。
步骤3:将分区数据的元信息写到内存索引数据结构SpillRecord中,其中每个分区的元信息包括在临时文件中的偏移量、压缩前数据大小和压缩后数据大小。如果当前内存索引大小超过1MB,则将内存索引写到文件output/spillN.out.index中。
(5)Combine阶段:当所有数据处理完成后,MapTask对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。
当所有数据处理完后,MapTask会将所有临时文件合并成一个大文件,并保存到文件output/file.out中,同时生成相应的索引文件output/file.out.index。
在进行文件合并过程中,MapTask以分区为单位进行合并。对于某个分区,它将采用多轮递归合并的方式。每轮合并io.sort.factor(默认100)个文件,并将产生的文件重新加入待合并列表中,对文件排序后,重复以上过程,直到最终得到一个大文件。
让每个MapTask最终只生成一个数据文件,可避免同时打开大量文件和同时读取大量小文件产生的随机读取带来的开销。
ReduceTask工作机制
ReduceTask工作机制
总结
- copy阶段:将不同的MapTask计算出来的数据拷贝到指定的ReduceTask,默认是放在内存中的。如果内存容量不足,那么写在磁盘中
- merge阶段:主要将从不同MapTask拷贝过来的数据文件进行一次合并,形成一个整体的大文件
- sort阶段:分组排序阶段。主要是用来保证key相同的逻辑判断。sort阶段可以不存在
- reduce阶段:将一组相同的key执行一次业务逻辑即可
【注意】ReduceTask的数量和MapTask的数量不一样,ReduceTask数量可以手动指定,但是数量指定是有一定要求的。一般默认情况下,ReduceTask的数量应该和map,collect阶段写出的分区数目对应。
详细步骤
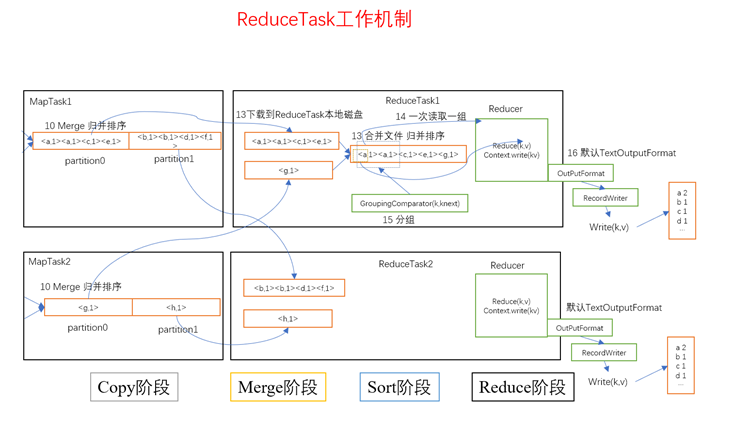
(1)Copy阶段:ReduceTask从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中。
(2)Merge阶段:在远程拷数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。
(3)Sort阶段:按照MapReduce语义,用户编写reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可。
(4)Reduce阶段:reduce()函数将计算结果写到HDFS上。
注意
从Map的collect阶段到reduce的sort阶段统称为shuffle阶段。
其中Map中的collect、spill、combine阶段称之为Map阶段的shuffle
Reduce中的copy、merge、sort阶段称之为Reduce阶段的shuffle
设置ReduceTask
reducetask的并行度同样影响整个job的执行并发度和执行效率,但与maptask的并发数由切片数决定不同,Reducetask数量的决定是可以直接手动设置:
|
//默认值是1,手动设置为4 job.setNumReduceTasks(4); |
实验:测试reducetask多少合适。
实验环境:1个master节点,16个slave节点:CPU:8GHZ,内存: 2G
实验结论:
表1 改变reduce task (数据量为1GB)
|
Map task =16 |
||||||||||
|
Reduce task |
1 |
5 |
10 |
15 |
16 |
20 |
25 |
30 |
45 |
60 |
|
总时间 |
892 |
146 |
110 |
92 |
88 |
100 |
128 |
101 |
145 |
104 |
注意事项
- 一旦setNumReduceTask设为0的话,就代表没有reduce阶段。也就意味着map阶段处理完成数据后,直接把数据放到最终结果文件中,不经过reduce处理了。在这种情况下,我们指定map阶段输出的key-value值的类型时就不能写如下这个方式了:
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
应该直接写:
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
此时结果数据输出文件就不再是part-r-00000了,而是part-m-00000。
- ReduceTask默认值就是1,所以输出文件个数为一个。
- 如果数据分布不均匀,就有可能在Reduce阶段产生数据倾斜
- ReduceTask数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能有1个ReduceTask。
- 具体多少个ReduceTask,需要根据集群性能而定。
- 如果分区数不是1,但是ReduceTask为1,是否执行分区过程。答案是:不执行分区过程。因为在MapTask的源码中,执行分区的前提是先判断ReduceNum个数是否大于1。不大于1肯定不执行。
MapReduce框架原理-MapTask和ReduceTask工作机制的更多相关文章
- Hadoop入门第三篇-MapReduce试手以及MR工作机制
MapReduce几个小应用 上篇文章已经介绍了怎么去写一个简单的MR并且将其跑起来,学习一个东西动手还是很有必要的,接下来我们就举几个小demo来体验一下跑起来的快感. demo链接请参照附件:ht ...
- MapReduce框架原理-MapTask工作机制
MapReduce框架原理-MapTask工作机制 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. maptask的并行度决定map阶段的任务处理并发度,进而影响到整个job的处理速 ...
- 【大数据】MapTask工作机制
1.MapTask工作机制 整个map阶段流程大体如上图所示.简单概述:input File通过getSplits被逻辑切分为多个split文件,通通过RecordReader(默认使用lineRec ...
- 浅谈MapReduce工作机制
1.MapTask工作机制 整个map阶段流程大体如上图所示.简单概述:input File通过getSplits被逻辑切分为多个split文件,通通过RecordReader(默认使用lineRec ...
- Hadoop MapReduce 一文详解MapReduce及工作机制
@ 目录 前言-MR概述 1.Hadoop MapReduce设计思想及优缺点 设计思想 优点: 缺点: 2. Hadoop MapReduce核心思想 3.MapReduce工作机制 剖析MapRe ...
- MapReduce06 MapReduce工作机制
目录 5 MapReduce工作机制(重点) 5.1 MapTask工作机制 5.2 ReduceTask工作机制 5.3 ReduceTask并行度决定机制 手动设置ReduceTask数量 测试R ...
- java大数据最全课程学习笔记(6)--MapReduce精通(二)--MapReduce框架原理
目前CSDN,博客园,简书同步发表中,更多精彩欢迎访问我的gitee pages 目录 MapReduce精通(二) MapReduce框架原理 MapReduce工作流程 InputFormat数据 ...
- MapReduce之MapTask工作机制
1. 阶段定义 MapTask:map----->sort map:Mapper.map()中将输出的key-value写出之前 sort:Mapper.map()中将输出的key-value写 ...
- hadoop MapReduce 工作机制
摸索了将近一个月的hadoop , 在centos上配了一个伪分布式的环境,又折腾了一把hadoop eclipse plugin,最后终于实现了在windows上编写MapReduce程序,在cen ...
随机推荐
- 4、基本数据类型(init、bool)
4.1.数字: 1.age = 21 weight = 64 fight = 5 2.数字的特点: (1)数字是不可变数据类型(不可以增加,删除,修改元素) (2)数字可以直接访问 (3)数字不可使用 ...
- 『无为则无心』Python序列 — 24、Python序列的推导式
目录 1.列表推导式 (1)快速体验 (2)带if的列表推导式 (3)多个for循环实现列表推导式 2.字典推导式 (1)创建一个字典 (2)将两个列表合并为一个字典 (3)提取字典中目标数据 3.集 ...
- CentOS-关闭防火墙和禁用安全策略
关闭防火墙 默认使用的是firewall作为防火墙 查看防火墙状态 $ firewall-cmd --state 停止firewall $ systemctl stop firewalld.servi ...
- 多元统计之因子分析模型及Python分析示例
1. 简介 因子分析是一种研究观测变量变动的共同原因和特殊原因, 从而达到简化变量结构目的的多元统计方法. 因子分析模型是主成分分析的推广, 也是利用降维的思想, 将复杂的原始变量归结为少数几个综合因 ...
- 资源:CentOS下载地址资源
新版本系统镜像下载(当前最新是CentOS 7.4版本) CentOS官网 官网地址 http://isoredirect.centos.org/centos/7.4.1708/isos/x86_64 ...
- [小工具] chrome上日语翻译工具
rikaikun -> 日语 "理解君" 下载地址: https://chrome.google.com/webstore/detail/rikaikun/jipdnfibh ...
- ReadyAPI 测试工具和创建管理
通过测试加速API质量APIs 和微服务正在改变组织在数字世界中开展业务的方式,对它们进行测试 比以往任何时候都更加重要 ReadyAPI测试工具是创建.管理.并运行自动化测试REST.SOAP.Gr ...
- 深入理解Java容器——HashMap
目录 存储结构 初始化 put resize 树化 get 为什么equals和hashCode要同时重写? 为何HashMap的数组长度一定是2的次幂? 线程安全 参考 存储结构 JDK1.8前是数 ...
- Docker以过时,看Containerd怎样一统天下
Docker作为非常流行的容器技术,之前经常有文章说它被K8S弃用了,取而代之的是另一种容器技术containerd!其实containerd只是从Docker中分离出来的底层容器运行时,使用起来和D ...
- dev c++自动添加初始源代码
1.打开 dec v++ 2.工具--编辑器属性 3."代码"选项卡,点击"缺省源" 7.选择"向项目初始源文件插入代码" 8.下面插入下面 ...