[Distributed ML] Parameter Server & Ring All-Reduce
Resource
ParameterServer入门和理解【较为详细,涉及到另一个框架:ps-lite】
一文读懂「Parameter Server」的分布式机器学习训练原理

并行计算与机器学习【很有必要过一遍大佬的视频】
并行计算与机器学习课程所有视频:
1. 并行计算基础以及MapReduce: https://youtu.be/gVcnOe6_c6Q
2. 参数服务器、去中心化: https://youtu.be/Aga2Lxp3G7M
3. Ring All-Reduce: https://youtu.be/rj-hjS5L8Bw
4. 联邦学习: https://youtu.be/STxtRucv_zo
Why?
epoch 扫一遍大数据,太耗时了,需要并行计算。
To reduce wall clock time.
Linear Predictor
f(x) = xTw, 所谓训练就是通过收敛,求w的过程。
计算梯度
加速计算梯度,并行。How?

基本概念
一、大纲要点

通信 Communication
<Share memory> or <Message passing>
系统架构 Architecture
Client-Server Architecture or Peer-to-Peer Architecture
同步或异步 Synchronization
-- 同步 --
- Apache MapReduce, 另外采用同步的 bulk synchronous parallel
- Apache Spark, 容错,快,但机器学习不高效。
MapReduce模式 计算梯度。
broadcast --> reduce --> 更新参数。
但通信耗时的(communicaiton complexty, latency),且加速比的趋势会逐渐平滑。
straggler:导致“大家”都等最慢的那一个stragger。
-- 异步 --
Synchronous Parallel Gradient Descent.
Using Parameter Server
异步梯度下降 的 Parameter Server,
也是 client-server architecture, message-passing communication
但用的是 asynchronous。
典型的实现:Ray
- 同步与异步模型的比较
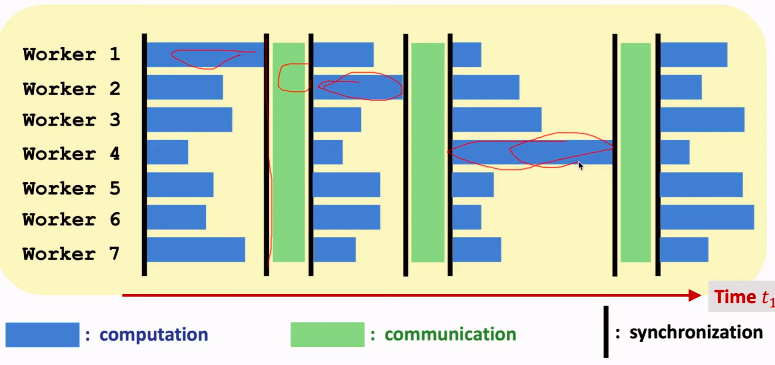
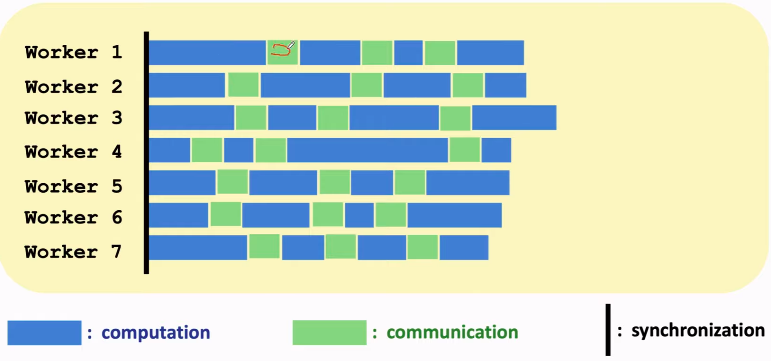
数据并行
其实就是分割数据为小份。
二、Parallel Programming Models

- MapReduce
- Parameter Server
- Decentralized Network
- 每个节点都有自己的一份完整数据。
- 图的连接越紧密,收敛越快。自然地,全连接最好。
与 Distributed Computing 的区别?
基本都在混用,没有明显的界限。
Parallel Computing in TensorFlow
TensorFlow Strategies
- MirroredStrategy【一机多个GPU,同步随机梯度下降】
- TPUStrategy
- MultiWorkerMirroredStrategy
- CentralStorageStrategy
- ParameterServerStrategy【适合分布式多台机器】
- OneDeviceStrategy
一、Parallel Training CNN on MNIST by MirroredStrategy
一机4个GPU,同步随机梯度下降。
from tensorflow.pyton.client import device_lib device_lib.list_local_device()
# 一块cpu,四块gpu
from tensorflow import distribute strategy = distribute.MirroredStrategy()
m = strategy.num_replicas_in_sync
print('Number of devices: {}'.format(m)) import tensorflow as tf def scale(image, label):
image = tf.cast(image, tf.float32)
image /= 255
return image, label import tensorflow_datasets as tfds datasets, info = tfds.load(name='mnist', with_info=True, as_supervised=True)
mnist_train = datasets['train'].map(scale).cache()
mnist_test = datasets['test'].map(scale)
sgd用比较小的batch 就好了。

这里在此遇到 strategy.scope(),提供了number of gpu的信息。

然后通过summary可看网络结构。
编译模型:
with strategy.scope():
model.compile(loss='sparse_categorical_crossentropy',
optimizer=keras.optimizers.RMSprop(learning_rate=1E-3),
metrics=['accuracy'])
二、Ring All-Reduce 原理
Horovod 是基于Ring-AllReduce方法的深度分布式学习插件,以支持多种流行架构包括TensorFlow、Keras、PyTorch等。这样平台开发者只需要为Horovod进行配置,而不是对每个架构有不同的配置方法。
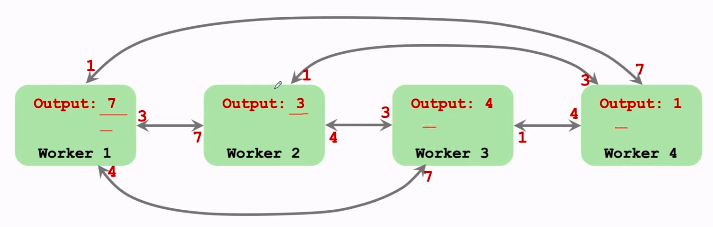
类似 MapReduce,但子节点不知道相加后的结果(15),但 ring all-reduce会让大家都知道。
E.g, all-reduce via reduce+broadcast(tf的内置)--> 通过转两圈,每个gpu都得到"梯度sum"。

E.g, all-reduce via all-to-all communication. (不是很流行)
优化后,跟gpu的块数无关。

Federated Learning 联邦学习
一、基本概念
属于 distributed learning。核心:如何减少通信次数,可以接受加大client端的计算量。
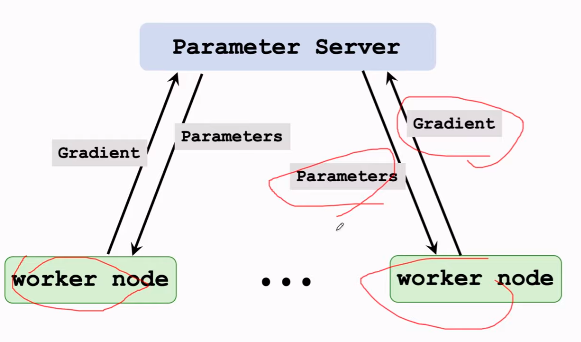
二、Federated Average Learning
FedAvg的有效性 已被证明。
On the Convergence of FedAvg on Non-IID Data
分布式随机梯度的“安全性”
Federated Average Learning 的"安全性”。
梯度 的本质就是原始数据做了一个变换而已,几乎携带了所有原始信息。
即使是 FedAvg也会被攻击有效。
三、总结
三个研究方向。

关于毒药样本
Data Evasion (test time) v.s. Data Poisoning(training time)
Parameter Server 专题
2014年分布式可扩展的Parameter Server被 沐神 @李沐提出,几乎完美的解决了机器模型的分布式训练问题,时至今日,parameter server不仅被直接应用在各大公司的机器学习平台上,而且也被集成在TensorFlow,MXNet等主流的深度框架中,作为机器学习分布式训练最重要的解决方案。
一、沐神出世
一致性与并行效率之间的取舍
在上篇文章介绍spark的并行梯度下降原理时,曾经提到spark并行梯度下降效率较低的原因就是每个节点都需要等待其他所有节点的梯度都计算完后,master节点汇总梯度,计算好新的模型参数后,才能开始下一轮的梯度计算,我们称这种方式为“同步阻断式”的并行梯度下降过程。
“同步阻断式“的并行梯度下降虽然是严格意义上的一致性最强的梯度下降方法,因为其计算结果和串行计算的过程一致,但效率过低,各节点的waiting时间过长,有没有办法提高梯度下降的并行度呢?
Paprameter Server采取的方法是用“异步非阻断式”的梯度下降替代原来的同步式方法。
异步梯度更新的方式虽然大幅加快了训练速度,但带来的是模型一致性的丧失,也就是说并行训练的结果与原来的单点串行训练的结果是不一致的,这样的不一致会对模型收敛的速度造成一定影响。所以最终选取同步更新还是异步更新取决于不同模型对于一致性的敏感程度。这类似于一个模型超参数选取的问题,需要针对具体问题进行具体的验证。
异步更新带来的梯度不一致性的影响没有想象中那么大
多server节点的协同和效率问题
采用了server group内多server的架构,每个server主要负责一部分的模型参数。模型参数使用key value的形式,每个server负责一个key的range就可以了。
权重管理平台
大家要清楚的是,Parameter Server仅仅是一个管理并行训练梯度的权重的平台,并不涉及到具体的模型实现,因此PS往往是作为MXNet,TensorFlow的一个组件,要想具体实现一个机器学习模型,还需要依赖于通用的,综合性的机器学习平台。
二、概念辨析
若干概念和工具的细节、使用搞清楚。
Ray可以实现 PS:https://docs.ray.io/en/master/auto_examples/plot_parameter_server.html
AWS-SAMPLE:Sagemaker Distributed Training with Parameter Server and Horovod
未来Uber的技术重点:Distributed Deep Learning with Horovod on Ray - Travis Addair, Uber

三、Challenges using DL at Scale (Horovod)

How Ray Can Help

horovod.ray allows users to leverage Horovod on a Ray cluster.
Currently, the Ray + Horovod integration provides a RayExecutor API.
基础例子
Executor Setup

Hello World

高级例子
Stateless API

Stateful API

更多例子,请见视频。
需要专题理解:horovod + ray。
End.
[Distributed ML] Parameter Server & Ring All-Reduce的更多相关文章
- 转:Parameter Server 详解
Parameter Server 详解 本博客仅为作者记录笔记之用,不免有很多细节不对之处. 还望各位看官能够见谅,欢迎批评指正. 更多相关博客请猛戳:http://blog.csdn.net/c ...
- 【分布式计算】MapReduce的替代者-Parameter Server
原文:http://blog.csdn.net/buptgshengod/article/details/46819051 首先还是要声明一下,这个文章是我在入职阿里云1个月以来,对于分布式计算的一点 ...
- [Distributed ML] Yi WANG's talk
王益,分布式机器学习的践行者,他的足迹值得后来者学习. 膜拜策略: LinkedIn高级分析师王益:大数据时代的理想主义和现实主义(图灵访谈)[心路历程] 分布式机器学习的故事-王益[历史由来] 分布 ...
- MXNet之ps-lite及parameter server原理
MXNet之ps-lite及parameter server原理 ps-lite框架是DMLC组自行实现的parameter server通信框架,是DMLC其他项目的核心,例如其深度学习框架MXNE ...
- parameter server学习
关于parameter server的学习: https://www.zybuluo.com/Dounm/note/517675 机器学习系统相比于其他系统而言,有一些自己的独特特点.例如: 迭代性: ...
- ROS参数服务器(Parameter Server)
操作演示,对参数服务器的理解:点击打开链接 rosparam使得我们能够存储并操作ROS 参数服务器(Parameter Server)上的数据.参数服务器能够存储整型.浮点.布尔.字符串.字典和列表 ...
- 百度DMLC分布式深度机器学习开源项目(简称“深盟”)上线了如xgboost(速度快效果好的Boosting模型)、CXXNET(极致的C++深度学习库)、Minerva(高效灵活的并行深度学习引擎)以及Parameter Server(一小时训练600T数据)等产品,在语音识别、OCR识别、人脸识别以及计算效率提升上发布了多个成熟产品。
百度为何开源深度机器学习平台? 有一系列领先优势的百度却选择开源其深度机器学习平台,为何交底自己的核心技术?深思之下,却是在面对业界无奈时的远见之举. 5月20日,百度在github上开源了其 ...
- Gazebo: Could not find parameter robot_description on parameter server
robot_state_publisher looks for the parameter "robot_description" by default. The robot_st ...
- parameter server
http://zeromq.org ZeroMQ \zero-em-queue\, \ØMQ\: Ø Connect your code in any language, on any platfo ...
随机推荐
- CentOS7 基本概念以及安装注意事项
什么是Linux发行版?发行版是什么意思? Linux本质上是操作系统内核,类似Chrome浏览器内核一样,Linux发行版CentOS.Redhat.Ubuntu等等都是基于Linux内核开发出来的 ...
- text-align: justify 文本对齐
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 【SpringBoot】Spring Boot
Spring Boot是由Pribotal团队提供,设计用来简化新Spring应用的初始搭建和开发过程的开源框架. 随着Spring体系越来越庞大,各种配置也是越来越复杂,Spring Boot就是解 ...
- 14.PHP_PHP与XML技术
PHP与XML技术 先把概念粘过来: 先来个基本模板: <?xml version="1.0" encoding="gb2312" standalone= ...
- Redis数据结构—跳跃表
目录 Redis数据结构-跳跃表 跳跃表产生的背景 跳跃表的结构 利用跳跃表查询有序链表 Redis跳跃表图示 Redis跳跃表数据结构 小结 Redis数据结构-跳跃表 大家好,我是白泽,最近学校有 ...
- Java中浮点数的坑
基本数据类型 浮点数存在误差 浮点数有一个需要特别注意的点就是浮点数是有误差的,比如以下这段代码你觉得输出的什么结果: public class Demo { public static void m ...
- Codeforces Round #712 (Div. 2)
A. Déjà Vu 题意:就是问能否加上字母a,使得字符串不中心对称 思路:只有一种情况不能加入,就是全部是a,剩下的都可以满足,找a的位置就找哪个字母不是a,然后让它的对称位置是新加的这个a 代码 ...
- QFNU 10-09 training
1.F - Three displays 题意:就是给出了两个数组,然后第一组数中找到i,j,k满足i<j<k,第二组数中找到a[i],a[j],a[k],满足a[i]<a[j]&l ...
- 【BUAA软工】团队任务拆解
项目 内容 班级:北航2020春软件工程 博客园班级博客 作业:团队任务拆解及时间规划 团队任务拆解 Alpha阶段总体规划 初步完成产品功能规格说明书中的基础功能 目前阶段仅支持本地上传文件至当前N ...
- 不融资、不上市、不快马圈地…“佛系”ZOHO的中国生意经
来源:钛媒体 作者:秦聪慧 "技术比肩SAP.直追微软的这家25岁"非典型"国际大厂会继续佛系下去吗? ZOHO研发中心大楼 在中国,有家相对低调的"舶来&qu ...