【spring源码系列】之【xml解析】
1. 读源码的方法
java程序员都知道读源码的重要性,尤其是spring的源码,代码设计不仅优雅,而且功能越来越强大,几乎可以与很多开源框架整合,让应用更易于专注业务领域开发。但是能把spring的源码吃透,不仅需要花费大量时间与精力,更需要需要掌握一些方法。下面结合自己读源码与走过的一些弯路,结合网上知名博客专家的建议,整理出以下要点,与读者共勉。
1.1 重视官方英文文档
spring的官方文档写的非常全面,基本可以认为是spring源码思想的一手来源,上面有很多例子不仅帮助读者如何应用,更能帮助我们了解其背后的思想,官方也用大量描述性的文字进行了相关思想的解读,让读者从一个总览上看大致了解spring的核心功能与特性。截止到目前,官方的最新版本是5.3.6,地址如下:
https://docs.spring.io/spring-framework/docs/current/reference/html/core.html#spring-core。
1.2 写示例程序debug源码
通过简单的示例程序,找到源码的入口,通过debug而非仅仅看静态的源码,只有看到真实跑起来的程序以及运行时的值时,心里才大致清楚源码做了哪些事情。
1.3 抓大放小
抓住源码主要流程,而非陷入细节,如果一开始就抠细节,不仅会打消看源码的积极性,也理不清主要流程,最后只能半途而废。只有主流程非常熟悉的情况下,并有时间精力,有兴趣可以深究一些自己感兴趣的细节。
1.4 写源码注释、画流程图
源码的一些重要方法与主要流程可以通过写注释、画流程图来加深理解。
1.5 思考背后的设计思想
源码之所以经典,是因为设计思想优秀,spring的源码在设计模式的灵活应用、类的抽象与封装、框架的可扩展性都做到了极致,可以把该思想以及实践应用到自己的项目设计里面。
1.6 螺旋式学习
任何知识都是循序渐进,源码学习更是如此,因为源码很容易让人半途而废,只有通过刻意重复来逐步提升,每一次都不求甚解,能搞懂多少就搞懂多少,但是每一次都比上一次的理解提升一点,也可参考优质博客系列对比学习,最终将源码的精髓吃透。
2. xml文件解析
2.1 流程概览
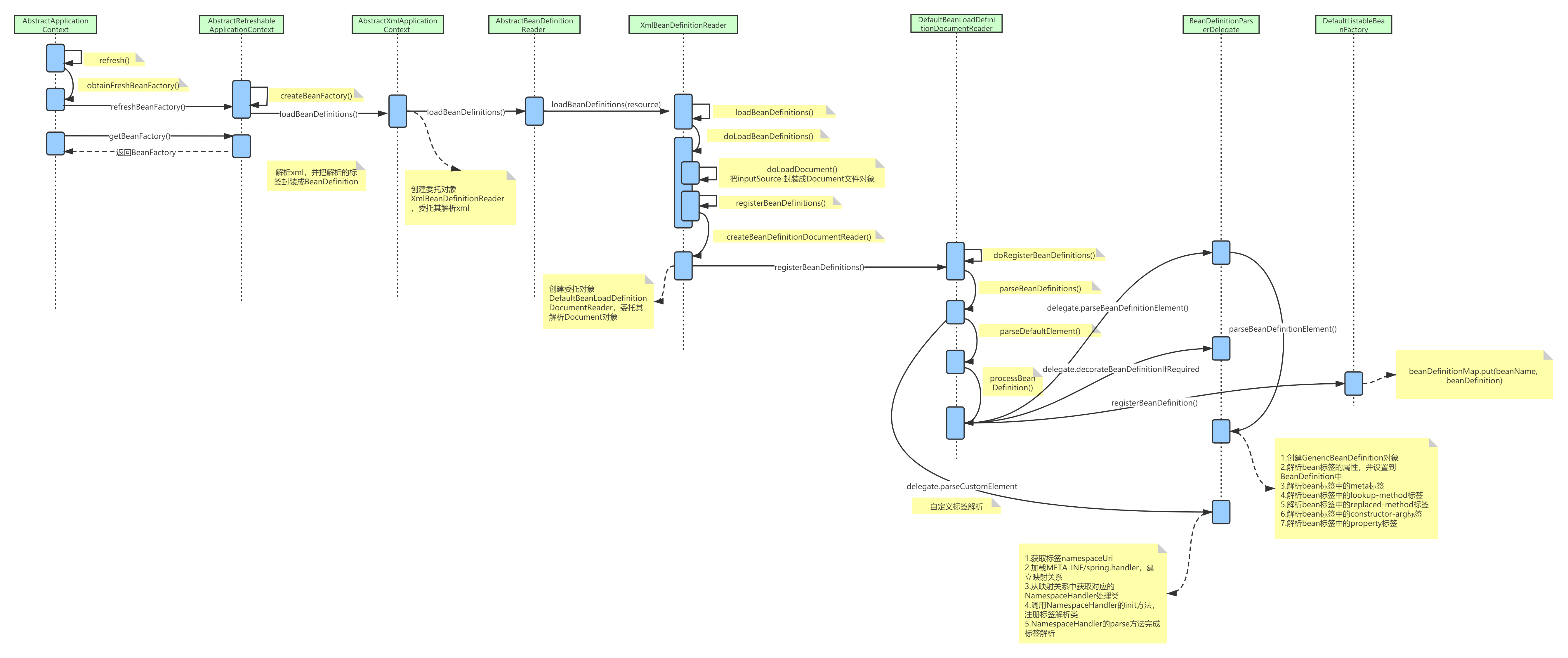
上图描述了xml的解析的主要流程,大致分为三个步骤:
step1: 创建BeanFactory对象;
step2: 解析xml标签,默认标签如bean、import,自定义标签<context:component-scan base-package=xxx>,把标签封装成BeanDefinition对象;
step3: 最后通过注册机BeanDefinitionRegistry注册到BeanFactory的实现类DefaultListableBeanFactory。
2.2 源码分析
AbstractApplicationContext类中最重要的方法refresh(),里面调用很多方法,本文先重点看xml解析相关的方法。
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
......
/*
1、创建BeanFactory对象
* 2、xml解析
* 默认标签解析:bean、import等
* 自定义标签解析 如:<context:component-scan base-package="com.xxx"/>
* 自定义标签解析流程:
* a、根据当前解析标签的头信息找到对应的namespaceUri
* b、加载spring所以jar中的spring.handlers文件。并建立映射关系
* c、根据namespaceUri从映射关系中找到对应的实现了NamespaceHandler接口的类
* d、调用类的init方法,init方法是注册了各种自定义标签的解析类
* e、根据namespaceUri找到对应的解析类,然后调用paser方法完成标签解析
*
* 3、把解析出来的xml标签封装成BeanDefinition对象
* */
// 告诉子类刷新内部beanFactory.
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
......
}
进入obtainFreshBeanFactory()方法,到refreshBeanFactory(),该方法是个抽象方法,由具体子类实现。
protected ConfigurableListableBeanFactory obtainFreshBeanFactory() {
// 刷新beanFactory
refreshBeanFactory();
// 获取beanFactory
return getBeanFactory();
}
子类AbstractRefreshableApplicationContext实现refreshBeanFactory()方法;
protected final void refreshBeanFactory() throws BeansException {
//如果BeanFactory不为空,则清除BeanFactory和里面的实例
if (hasBeanFactory()) {
destroyBeans();
closeBeanFactory();
}
try {
//创建beanFactory
DefaultListableBeanFactory beanFactory = createBeanFactory();
beanFactory.setSerializationId(getId());
customizeBeanFactory(beanFactory);
//传入beanFactory,并装载BeanDefinition对象
loadBeanDefinitions(beanFactory);
this.beanFactory = beanFactory;
}
catch (IOException ex) {
throw new ApplicationContextException("I/O error parsing bean definition source for " + getDisplayName(), ex);
}
}
上面方法主要做了两件事,一是创建beanFactory,二是beanFactory作为参数传入,并负责装载BeanDefinition对象。接下来进入loadBeanDefinitions(beanFactory)方法,该方法是个抽象方法,交给子类AbstractXmlApplicationContext去实现,子类方法如下。
protected void loadBeanDefinitions(DefaultListableBeanFactory beanFactory) throws BeansException, IOException {
//为给定的BeanFactory创建xml的解析器,这里是一个委托模式
XmlBeanDefinitionReader beanDefinitionReader = new XmlBeanDefinitionReader(beanFactory);
beanDefinitionReader.setEnvironment(this.getEnvironment());
//这里传一个this进去,因为ApplicationContext是实现了ResourceLoader接口的
beanDefinitionReader.setResourceLoader(this);
beanDefinitionReader.setEntityResolver(new ResourceEntityResolver(this));
// Allow a subclass to provide custom initialization of the reader,
// then proceed with actually loading the bean definitions.
initBeanDefinitionReader(beanDefinitionReader);
//传入解析器,装载BeanDefinitions
loadBeanDefinitions(beanDefinitionReader);
}
上述方法创建xml解析器XmlBeanDefinitionReader,并交由解析器完成BeanDefinitions的装载。再次进入AbstractXmlApplicationContext类的loadBeanDefinitions方法。
protected void loadBeanDefinitions(XmlBeanDefinitionReader reader) throws BeansException, IOException {
Resource[] configResources = getConfigResources();
if (configResources != null) {
reader.loadBeanDefinitions(configResources);
}
//获取需要加载的xml配置文件
String[] configLocations = getConfigLocations();
if (configLocations != null) {
// xml解析器完成装载
reader.loadBeanDefinitions(configLocations);
}
}
再次进入xml解析器的loadBeanDefinitions方法,
public int loadBeanDefinitions(String location, @Nullable Set<Resource> actualResources) throws BeanDefinitionStoreException {
......
//把字符串类型的xml文件路径,转换成Resource对象
Resource[] resources = ((ResourcePatternResolver) resourceLoader).getResources(location);
// 传入Resource对象装载BeanDefinitions
int count = loadBeanDefinitions(resources);
......
进入上述的loadBeanDefinitions(resources)方法;
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
try {
//把inputSource 封装成Document文件对象
Document doc = doLoadDocument(inputSource, resource);
//根据document对象,去注册BeanDefinitions
int count = registerBeanDefinitions(doc, resource);
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + count + " bean definitions from " + resource);
}
上述方法一是封装Document文件对象,二是用Document对象去注册BeanDefinitions,随后进入registerBeanDefinitions方法;
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
//创建BeanDefinitionDocumentReader
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
int countBefore = getRegistry().getBeanDefinitionCount();
//并委托BeanDefinitionDocumentReader这个类进行document的解析
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
return getRegistry().getBeanDefinitionCount() - countBefore;
}
该方法创建BeanDefinitionDocumentReader对象,并委托其解析document,进入registerBeanDefinitions方法。
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
if (delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
if (delegate.isDefaultNamespace(ele)) {
//默认标签解析
parseDefaultElement(ele, delegate);
}
else {
//自定义标签解析
delegate.parseCustomElement(ele);
}
}
}
}
else {
delegate.parseCustomElement(root);
}
}
上述方法主要完成默认标签解析,与自定义标签解析,默认标签如同import、alias、bean、beans,自定义标签比如<aop:aspectj-autoproxy />,默认标签重点分析bean标签的解析;
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
//bean签解析
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
if (bdHolder != null) {
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
try {
//完成document到BeanDefinition对象转换后,对BeanDefinition对象进行缓存注册
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
......
}
}
上述方法主要是bean标签的解析,最后对BeanDefinition对象进行缓存注册,先分析解析;
public AbstractBeanDefinition parseBeanDefinitionElement(
Element ele, String beanName, @Nullable BeanDefinition containingBean) {
......
//创建BeanDefinition
AbstractBeanDefinition bd = createBeanDefinition(className, parent);
//解析BeanDefinition里面的属性
parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);
bd.setDescription(DomUtils.getChildElementValueByTagName(ele, DESCRIPTION_ELEMENT));
//解析meta元素
parseMetaElements(ele, bd);
//解析Lookup方法
parseLookupOverrideSubElements(ele, bd.getMethodOverrides());
//解析ReplacedMethod方法
parseReplacedMethodSubElements(ele, bd.getMethodOverrides());
//解析构造参数方法
parseConstructorArgElements(ele, bd);
//解析属性元素方法
parsePropertyElements(ele, bd);
//解析Qualifier元素方法
parseQualifierElements(ele, bd);
bd.setResource(this.readerContext.getResource());
bd.setSource(extractSource(ele));
// 最后返回beanDefinition
return bd;
再分析注册BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry()),进入该方法,最后会进入DefaultListableBeanFactory类,
@Override
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
throws BeanDefinitionStoreException {
Assert.hasText(beanName, "Bean name must not be empty");
Assert.notNull(beanDefinition, "BeanDefinition must not be null");
if (beanDefinition instanceof AbstractBeanDefinition) {
try {
((AbstractBeanDefinition) beanDefinition).validate();
}
catch (BeanDefinitionValidationException ex) {
throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,
"Validation of bean definition failed", ex);
}
}
//先判断BeanDefinition是否已经注册
BeanDefinition existingDefinition = this.beanDefinitionMap.get(beanName);
if (existingDefinition != null) {
if (!isAllowBeanDefinitionOverriding()) {
throw new BeanDefinitionOverrideException(beanName, beanDefinition, existingDefinition);
}
else if (existingDefinition.getRole() < beanDefinition.getRole()) {
// e.g. was ROLE_APPLICATION, now overriding with ROLE_SUPPORT or ROLE_INFRASTRUCTURE
if (logger.isInfoEnabled()) {
logger.info("Overriding user-defined bean definition for bean '" + beanName +
"' with a framework-generated bean definition: replacing [" +
existingDefinition + "] with [" + beanDefinition + "]");
}
}
else if (!beanDefinition.equals(existingDefinition)) {
if (logger.isDebugEnabled()) {
logger.debug("Overriding bean definition for bean '" + beanName +
"' with a different definition: replacing [" + existingDefinition +
"] with [" + beanDefinition + "]");
}
}
else {
if (logger.isTraceEnabled()) {
logger.trace("Overriding bean definition for bean '" + beanName +
"' with an equivalent definition: replacing [" + existingDefinition +
"] with [" + beanDefinition + "]");
}
}
this.beanDefinitionMap.put(beanName, beanDefinition);
}
else {
if (hasBeanCreationStarted()) {
// Cannot modify startup-time collection elements anymore (for stable iteration)
synchronized (this.beanDefinitionMap) {
this.beanDefinitionMap.put(beanName, beanDefinition);
List<String> updatedDefinitions = new ArrayList<>(this.beanDefinitionNames.size() + 1);
updatedDefinitions.addAll(this.beanDefinitionNames);
updatedDefinitions.add(beanName);
this.beanDefinitionNames = updatedDefinitions;
removeManualSingletonName(beanName);
}
}
else {
//把beanDefinition缓存到map中
this.beanDefinitionMap.put(beanName, beanDefinition);
//把beanName放到beanDefinitionNames list中
this.beanDefinitionNames.add(beanName);
removeManualSingletonName(beanName);
}
this.frozenBeanDefinitionNames = null;
}
最终看出所谓的注册到BeanFactory的容器中的类,无非就是一个定义了ConcurrentHashMap类型的beanDefinitionMap。
自定义标签解析BeanDefinitionParserDelegate类,执行parseCustomElement方法;
public BeanDefinition parseCustomElement(Element ele, @Nullable BeanDefinition containingBd) {
// 获取namespaceURI
String namespaceUri = getNamespaceURI(ele);
if (namespaceUri == null) {
return null;
}
// 解析namespaceURI对应的handler类
NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);
if (handler == null) {
error("Unable to locate Spring NamespaceHandler for XML schema namespace [" + namespaceUri + "]", ele);
return null;
}
// 执行handler的解析方法
return handler.parse(ele, new ParserContext(this.readerContext, this, containingBd));
}
上述过程主要完成以下步骤:
step1:获取namespaceURI;
step2:解析namespaceURI对应的handler类;
step3:执行handler方法解析。
其中step2又分为几个步骤,代码进入如下方法
public NamespaceHandler resolve(String namespaceUri) {
// 从spring.handler里面获取映射关系
Map<String, Object> handlerMappings = getHandlerMappings();
// 根据namespaceURI从映射关系map中获取对应的处理类handler
Object handlerOrClassName = handlerMappings.get(namespaceUri);
if (handlerOrClassName == null) {
return null;
}
else if (handlerOrClassName instanceof NamespaceHandler) {
return (NamespaceHandler) handlerOrClassName;
}
else {
// 通过反射实例化namespaceHandler类
String className = (String) handlerOrClassName;
try {
Class<?> handlerClass = ClassUtils.forName(className, this.classLoader);
if (!NamespaceHandler.class.isAssignableFrom(handlerClass)) {
throw new FatalBeanException("Class [" + className + "] for namespace [" + namespaceUri +
"] does not implement the [" + NamespaceHandler.class.getName() + "] interface");
}
// 实例化namespaceHandler对象
NamespaceHandler namespaceHandler = (NamespaceHandler) BeanUtils.instantiateClass(handlerClass);
// 执行init方法
namespaceHandler.init();
// 把新的namespaceUri与namespaceHandler映射关系组装到map中
handlerMappings.put(namespaceUri, namespaceHandler);
return namespaceHandler;
}
上述解析namespaceURI对应的handler类,对应步骤又课分为如下几步,
step1:从spring.handler里面获取映射关系;
step2:根据namespaceURI从映射关系map中获取对应的处理类handler;
step3:通过反射获取handler对象,并执行init方法,完成自定义标签注册;
3. 总结
本文主要分析了xml标签的解析,主要步骤与流程图上述代码分析与时序图,通过调试可以清晰观察到解析过程,后续将通过示例分析beanDefinition类的相关属性。
【spring源码系列】之【xml解析】的更多相关文章
- spring源码-增强容器xml解析-3.1
一.ApplicationContext的xml解析工作是通过ClassPathXmlApplicationContext来实现的,其实看过ClassPathXmlApplicationContext ...
- Spring源码追踪2——xml解析入口
解析xml节点入口 org.springframework.beans.factory.xml.DefaultBeanDefinitionDocumentReader.doRegisterBeanDe ...
- Spring源码-IOC部分-Xml Bean解析注册过程【3】
实验环境:spring-framework-5.0.2.jdk8.gradle4.3.1 Spring源码-IOC部分-容器简介[1] Spring源码-IOC部分-容器初始化过程[2] Spring ...
- Ioc容器BeanPostProcessor-Spring 源码系列(3)
Ioc容器BeanPostProcessor-Spring 源码系列(3) 目录: Ioc容器beanDefinition-Spring 源码(1) Ioc容器依赖注入-Spring 源码(2) Io ...
- Ioc容器beanDefinition-Spring 源码系列(1)
Ioc容器beanDefinition-Spring 源码系列(1) 目录: Ioc容器beanDefinition-Spring 源码(1) Ioc容器依赖注入-Spring 源码(2) Ioc容器 ...
- Spring源码系列 — 注解原理
前言 前文中主要介绍了Spring中处理BeanDefinition的扩展点,其中着重介绍BeanDefinitionParser方式的扩展.本篇文章承接该内容,详解Spring中如何利用BeanDe ...
- Spring源码系列 — BeanDefinition扩展点
前言 前文介绍了Spring Bean的生命周期,也算是XML IOC系列的完结.但是Spring的博大精深,还有很多盲点需要摸索.整合前面的系列文章,从Resource到BeanDefinition ...
- Spring源码系列 — Bean生命周期
前言 上篇文章中介绍了Spring容器的扩展点,这个是在Bean的创建过程之前执行的逻辑.承接扩展点之后,就是Spring容器的另一个核心:Bean的生命周期过程.这个生命周期过程大致经历了一下的几个 ...
- Spring源码系列 — BeanDefinition
一.前言 回顾 在Spring源码系列第二篇中介绍了Environment组件,后续又介绍Spring中Resource的抽象,但是对于上下文的启动过程详解并未继续.经过一个星期的准备,梳理了Spri ...
- AOP执行增强-Spring 源码系列(5)
AOP增强实现-Spring 源码系列(5) 目录: Ioc容器beanDefinition-Spring 源码(1) Ioc容器依赖注入-Spring 源码(2) Ioc容器BeanPostProc ...
随机推荐
- NGK全球启动大会圆满落幕
加州时间2020年11月25日,NGK全球启动大会在美国硅谷圆满落幕.本次NGK全球启动大会为NGK正式在全球上线拉开了序幕. 百余位受邀嘉宾出席了本次NGK全球启动大会,其中包括NGK创始人.星盟投 ...
- yaml配置和ini配置的数据源配置和数据获取
1.前言 关于yaml和ini的相关理论暂不做记录,不影响代码编写,百度即可. 2.关于配置文件的选择 yaml 和 ini 都使用过, 但是yaml更符合人类使用,已要弃用ini,后期各项目均采用y ...
- Docker Elasticsearch 集群配置
一:选用ES原因 公司项目有些mysql的表数据已经超过5百万了,各种业务的查询入库压力已经凸显出来,初步打算将一个月前的数据迁移到ES中,mysql的老数据就物理删除掉. 首先是ES使用起来比较方便 ...
- Glibc堆管理机制基础
最近正在学习linux下堆的管理机制,收集了书籍和网络上的资料,以自己的理解做了整理,做个记录.如果有什么不对的地方欢迎指出! Memory Allocator 常见的内存管理机制 dlmalloc: ...
- Flannel和Calico网络插件工作流程对比
Flannel和Calico网络插件对比 Calico简介 Calico是一个纯三层的网络插件,calico的bgp模式类似于flannel的host-gw Calico方便集成 OpenStac ...
- 关于Java高并发编程你需要知道的“升段攻略”
关于Java高并发编程你需要知道的"升段攻略" 基础 Thread对象调用start()方法包含的步骤 通过jvm告诉操作系统创建Thread 操作系统开辟内存并使用Windows ...
- ArrayList源码分析笔记
ArrayList源码分析笔记 先贴出ArrayList一些属性 public class ArrayList<E> extends AbstractList<E> imple ...
- NumPy 将停止支持 Python 2
NumPy 项目宣布将停止支持 Python 2.Python 核心团队已经决定在 2020 年停止支持 Python 2,而 NumPy 项目自 2010 年以来同时支持 Python 2 和 Py ...
- Codeforces Round #699 (Div. 2)
A Space Navigation #include <bits/stdc++.h> using namespace std; typedef long long LL; #define ...
- ts装饰器的用法,基于express创建Controller等装饰器
TS TypeScript 是一种由微软开发的自由和开源的编程语言.它是 JavaScript 的一个超集,而且本质上向这个语言添加了可选的静态类 型和基于类的面向对象编程. TypeScript 扩 ...