Hadoop 2.x安装
1、关闭防火墙
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
查看防火墙状态
firewall-cmd --state
systemctl status firewalld.service

2、设置免密钥
在master中生成密钥文件
ssh-keygen -t rsa
一直回车
将密钥文件同步到所有节点
ssh-copy-id master
ssh-copy-id node1
ssh-copy-id node2
3、上传hadoop安装包 上传到msater的/usr/local/moudle/
4、解压
tar -zxvf hadoop-2.7.6.tar.gz -C /usr/local/soft
5、配置环境变量
vim /etc/profile
增加hadoop环境变量,将bin和sbin都配置到PATh中
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171
export HADOOP_HOME=/usr/local/soft/hadoop-2.7.6
export PATH=.:$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin(PATH要在最后)
source /etc/profile

6、修改配置文件
hadoop 配置文件在/usr/local/soft/hadoop-2.7.6/etc/hadoop/
cd /usr/local/soft/hadoop-2.7.6/etc/hadoop/
6.1、slaves : 从节点列表(datanode)
vim slaves
增加node1, node2
6.2、hadoop-env.sh : Hadoop 环境配置文件
vim hadoop-env.sh
修改JAVA_HOME
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171
6.3、core-site.xml : hadoop核心配置文件
vim core-site.xml
在configuration中间增加以下内容
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/soft/hadoop-2.7.6/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
6.4、hdfs-site.xml : hdfs配置文件
vim hdfs-site.xml
在configuration中间增加以下内容
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
6.5、yarn-site.xml: yarn配置文件
vim yarn-site.xml
在configuration中间增加以下内容
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
6.6、mapred-site.xml: mapreduce配置文件
复制一个重命名
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
在configuration中间增加以下内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
7、将hadoop安装文件分发到子节点
scp -r /usr/local/soft/hadoop-2.7.6/ node1:/usr/local/soft/
scp -r /usr/local/soft/hadoop-2.7.6/ node2:/usr/local/soft
8、格式化namenode
hdfs namenode -format
9、启动和停止hadoop
start-all.sh(在sbin目录下)
stop-all.sh (在sbin目录下)
10、访问hdfs页面验证是否安装成功
http://master:50070

或者使用java中的jps
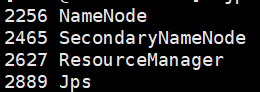
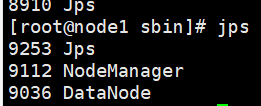
如果安装失败
stop-all.sh
再次重启的时候
1需要手动将每个节点的tmp目录删除: 所有节点都要删除
rm -rf /usr/local/soft/hadoop-2.7.6/tmp
然后执行将namenode格式化
2在主节点执行命令:
hdfs namenode -format
3启动hadoop
start-all.sh
Hadoop 2.x安装的更多相关文章
- Hadoop三种安装模式:单机模式,伪分布式,真正分布式
Hadoop三种安装模式:单机模式,伪分布式,真正分布式 一 单机模式standalone单 机模式是Hadoop的默认模式.当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守 ...
- Linux下Hadoop的简单安装
Hadoop 的安装极为简单,一共只有三步: 安装JDK 安装Hadoop 配置Hadoop 1,安装JDK 下载JDK,ftp传到linux或者linux中下载 切换 ...
- Hadoop单机模式安装
一.实验环境说明 1. 环境登录 无需密码自动登录,系统用户名shiyanlou,密码shiyanlou 2. 环境介绍 本实验环境采用带桌面的Ubuntu Linux环境,实验中会用到桌面上的程序: ...
- Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS
摘自:http://www.powerxing.com/install-hadoop-cluster/ 本教程讲述如何配置 Hadoop 集群,默认读者已经掌握了 Hadoop 的单机伪分布式配置,否 ...
- hadoop多机安装YARN
hadoop伪分布安装称为测试环境安装,多机分布称为生成环境安装.以下安装没有进行HA(热备)和Federation(联邦).除非是性能需要,否则没必要安装Federation,HA可以一试,涉及到Z ...
- Hadoop完全分布式安装教程
一.软件版本 Hadoop版本号:hadoop-2.6.0.tar: VMWare版本号:VMware-workstation-full-11.0.0-2305329 Ubuntu版本号:ubuntu ...
- 3-1.Hadoop单机模式安装
Hadoop单机模式安装 一.实验介绍 1.1 实验内容 hadoop三种安装模式介绍 hadoop单机模式安装 测试安装 1.2 实验知识点 下载解压/环境变量配置 Linux/shell 测试Wo ...
- Ubuntu16.04下Hadoop的本地安装与配置
一.系统环境 os : Ubuntu 16.04 LTS 64bit jdk : 1.8.0_161 hadoop : 2.6.4 部署时使用的用户名为hadoop,下文中需要使用用户名的地方请更改为 ...
- Hadoop完全分布式安装
一.软件版本 Hadoop版本号:hadoop-2.6.0.tar: VMWare版本号:VMware-workstation-full-11.0.0-2305329 Ubuntu版本号:ubuntu ...
- hadoop伪分布式安装之Linux环境准备
Hadoop伪分布式安装之Linux环境准备 一.软件版本 VMare Workstation Pro 14 CentOS 7 32/64位 二.实现Linux服务器联网功能 网络适配器双击选择VMn ...
随机推荐
- Adaptive AUTOSAR 学习笔记 14 - 车辆诊断
本系列学习笔记基于 AUTOSAR Adaptive Platform 官方文档 R20-11 版本 AUTOSAR_EXP_PlatformDesign.pdf.作者:Zijian/TENG 原文地 ...
- Special Forms and Syntax Sugars in Clojure
(...): function literals, p40, 64; '(...): suppress evaluation, p24; _(...): comments, p18; ".. ...
- 【笔记】求数据前n个主成分以及对高维数据映射为低维数据
求数据前n个主成分并进行高维数据映射为低维数据的操作 求数据前n个主成分 先前的将多个样本映射到一个轴上以求使其降维的操作,其中的样本点本身是二维的样本点,将其映射到新的轴上以后,还不是一维的数据,对 ...
- dockerfile中ENTRYPOINT与CMD的结合
一.写在前面 我们在上篇小作文docker容器dockerfile详解对中dockerfile有了比较全面的认识,我们也提到ENTRYPOINT和CMD都可以指定容器启动命令.因为这两个命令是掌握do ...
- mongoose 更新数据时不验证数据(忽略设定的集合规则)的问题
问题: mongoose 更新数据时不验证数据(忽略设定的集合规则)的问题 参考: http://www.mongoosejs.net/docs/api.html#updateone_updateOn ...
- 浅谈 asp.net core web api
希望通过本文能够了解如下内容: ControllerBase Attributes Action的返回值类型 ControllerBase 当我们开始实际上项目, 真正实操 anc 时, 肯定会用到 ...
- 【springcloud】服务熔断与降级(Hystrix)
转自:https://blog.csdn.net/pengjunlee/article/details/86688858 服务熔断 服务熔断的作用类似于我们家用的保险丝,当某服务出现不可用或响应超时的 ...
- mfc HackerTools防止程序双开
来自:https://github.com/TonyChen56/HackerTools 1 HANDLE hMutex = CreateMutexA(NULL, FALSE, "GuiSh ...
- Playwright-python 教程
安装 pip install playwright -i https://mirrors.aliyun.com/pypi/simple/ 使用阿里源,下载速度快一点. python -m playwr ...
- k8s 探针 exec多个判断条件条件 多个检测条件
背景 1,之前我们的yaml文件里面有就绪探针. 2,探针是检测一个文件是否生成,生成了说明服务正常. 3,现在要加一个检测,也是一个文件是否存在并且不为空. 4,只有两个条件同时满足了 服务才算正常 ...