Spark基础:(七)Spark Streaming入门
介绍
1、是spark core的扩展,针对实时数据流处理,具有可扩展、高吞吐量、容错.
数据可以是来自于kafka,flume,tcpsocket,使用高级函数(map reduce filter ,join , windows),
处理的数据可以推送到database,hdfs,针对数据流处理可以应用到机器学习和图计算中。
内部,spark接受实时数据流,分成batch(分批次)进行处理,最终在每个batch终产生结果stream.
2.discretized stream or DStream,
离散流,表示的是连续的数据流。
通过kafka、flume等输入数据流产生,也可以通过对其他DStream进行高阶变换产生。
在内部,DStream是表现为RDD序列。
体验
依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.1.0</version>
</dependency>scalaDeno
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
object SparkStreamingDemo {
def main(args: Array[String]): Unit = {
//local[n] n > 1
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
//创建Spark流上下文,批次时长是1s
val ssc = new StreamingContext(conf, Seconds(1))
//创建socket文本流
val lines = ssc.socketTextStream("localhost", 9999)
//压扁
val words = lines.flatMap(_.split(" "))
//变换成对偶
val pairs = words.map((_,1));
val count = pairs.reduceByKey(_+_) ;
count.print()
//启动
ssc.start()
//等待结束
ssc.awaitTermination()
}
}1.启动nc服务器
[win7]
cmd>nc -lL -p 9999
2.启动spark Streaming程序
3.在nc的命令行输入单词.
hello world
4.观察spark计算结果。
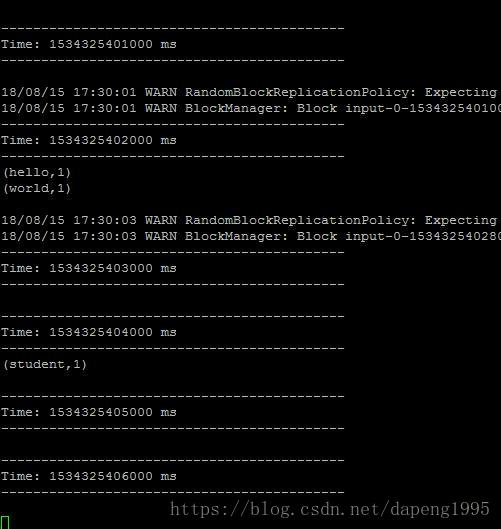
同样的丢到
Spark基础:(七)Spark Streaming入门的更多相关文章
- Spark 基础操作
1. Spark 基础 2. Spark Core 3. Spark SQL 4. Spark Streaming 5. Spark 内核机制 6. Spark 性能调优 1. Spark 基础 1. ...
- 【原创 Hadoop&Spark 动手实践 5】Spark 基础入门,集群搭建以及Spark Shell
Spark 基础入门,集群搭建以及Spark Shell 主要借助Spark基础的PPT,再加上实际的动手操作来加强概念的理解和实践. Spark 安装部署 理论已经了解的差不多了,接下来是实际动手实 ...
- spark streaming 入门例子
spark streaming 入门例子: spark shell import org.apache.spark._ import org.apache.spark.streaming._ sc.g ...
- Spark基础脚本入门实践3:Pair RDD开发
Pair RDD转化操作 val rdd = sc.parallelize(List((1,2),(3,4),(3,6))) //reduceByKey,通过key来做合并val r1 = rdd.r ...
- Spark基础脚本入门实践1
1.创建数据框架 Creating DataFrames val df = spark.read.json("file:///usr/local/spark/examples/src/mai ...
- spark基础知识(1)
一.大数据架构 并发计算: 并行计算: 很少会说并发计算,一般都是说并行计算,但是并行计算用的是并发技术.并发更偏向于底层.并发通常指的是单机上的并发运行,通过多线程来实现.而并行计算的范围更广,他是 ...
- 初步了解Spark生态系统及Spark Streaming
一. 场景 ◆ Spark[4]: Scope: a MapReduce-like cluster computing framework designed for low-laten ...
- spark基础知识介绍2
dataframe以RDD为基础的分布式数据集,与RDD的区别是,带有Schema元数据,即DF所表示的二维表数据集的每一列带有名称和类型,好处:精简代码:提升执行效率:减少数据读取; 如果不配置sp ...
- 最全的spark基础知识解答
原文:http://www.36dsj.com/archives/61155 一. Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduc ...
- Spark基础学习精髓——第一篇
Spark基础学习精髓 1 Spark与大数据 1.1 大数据基础 1.1.1 大数据特点 存储空间大 数据量大 计算量大 1.1.2 大数据开发通用步骤及其对应的技术 大数据采集->大数据预处 ...
随机推荐
- C++ 重载、重写、重定义的区别
C++ 中 重载.重写.重定义的区别 重载(overload) 定义: 在同一个作用域内,两函数的函数名相同, 参数不相同(可以是参数类型不同或者是参数个数不同), 那么就说这两个 函数重载. 分类: ...
- C 数组类型语法总结
数组类型语法总结 数组指针 和 指针数组 区分 数组指针是一个指针,只对应类型的数组.指针数组是一个数组,其中每个元素都是指针 数组指针遵循指针运算法则.指针数组拥有c语言数组的各种特性 数组类型重命 ...
- EF Core 小技巧:迁移已经应用到数据库,如何进行迁移回退操作?
场景描述:项目中存在两个迁移 Teacher 和 TeachingPlan ,TeachingPlan 在 Teacher 之后创建,并且已经执行 dotnet ef database update ...
- 【Java】数组Array
Java基础复习之:数组 简介 数组(Array):多个相同数据类型按照一定顺序排列的集合,并使用一个名字命名,通过编号的方式对这些数据进行统一管理 一维数组 一维数组的声明与初始化 int[] id ...
- MySQL——DML数据增、删、改
插入 方式一(经典) 语法: insert into 表名(列名,...) values(值,...); 若要一次插入多行 create table if NOT EXISTS user( name ...
- Vuex状态管理——任意组件间通信
核心概念 在Vue中实现集中式状态(数据)管理的一个Vue插件,对vue应用中多个组件的共享状态进行集中式的管理(读/写),也是一种组件间通信的方式,且适用于任意组件间通信. 每一个 Vuex 应用的 ...
- Vue3+Vue-cli4项目中使用腾讯滑块验证码
Vue3+Vue-cli4项目中使用腾讯滑块验证码 简介: 滑块验证码相比于传统的图片验证码具有以下优点: 验证码的具体验证不需要服务端去验证,服务端只需要核验验证结果即可. 验证码的实现不需要我们去 ...
- SSH服务器拒绝了密码。请再试一次。怎么改都不行
使用Xshell连接服务器,之前还好好的,突然之间就报"SSH服务器拒绝了密码.请再试一次"的错误. 1.检查 检查了IP.连接端口.用户.密码.网络是否正确? 本机情况:能够pi ...
- Python批量爬取谷歌原图,2021年最新可用版
文章目录 前言 一.环境配置 1.安装selenium 2.使用正确的谷歌浏览器驱动 二.使用步骤 1.加载chromedriver.exe 2.设置是否开启可视化界面 3.输入关键词.下载图片数.图 ...
- 彻底搞懂Spring状态机原理,实现订单与物流解耦
本文节选自<设计模式就该这样学> 1 状态模式的UML类图 状态模式的UML类图如下图所示. 2 使用状态模式实现登录状态自由切换 当我们在社区阅读文章时,如果觉得文章写得很好,我们就会评 ...