Spark基础:(七)Spark Streaming入门
介绍
1、是spark core的扩展,针对实时数据流处理,具有可扩展、高吞吐量、容错.
数据可以是来自于kafka,flume,tcpsocket,使用高级函数(map reduce filter ,join , windows),
处理的数据可以推送到database,hdfs,针对数据流处理可以应用到机器学习和图计算中。
内部,spark接受实时数据流,分成batch(分批次)进行处理,最终在每个batch终产生结果stream.
2.discretized stream or DStream,
离散流,表示的是连续的数据流。
通过kafka、flume等输入数据流产生,也可以通过对其他DStream进行高阶变换产生。
在内部,DStream是表现为RDD序列。
体验
依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.1.0</version>
</dependency>scalaDeno
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
object SparkStreamingDemo {
def main(args: Array[String]): Unit = {
//local[n] n > 1
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
//创建Spark流上下文,批次时长是1s
val ssc = new StreamingContext(conf, Seconds(1))
//创建socket文本流
val lines = ssc.socketTextStream("localhost", 9999)
//压扁
val words = lines.flatMap(_.split(" "))
//变换成对偶
val pairs = words.map((_,1));
val count = pairs.reduceByKey(_+_) ;
count.print()
//启动
ssc.start()
//等待结束
ssc.awaitTermination()
}
}1.启动nc服务器
[win7]
cmd>nc -lL -p 9999
2.启动spark Streaming程序
3.在nc的命令行输入单词.
hello world
4.观察spark计算结果。
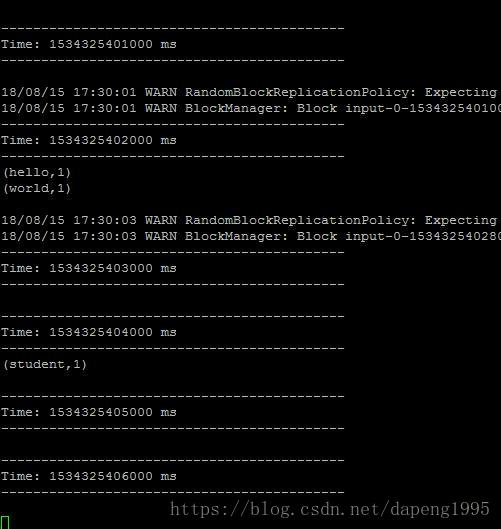
同样的丢到
Spark基础:(七)Spark Streaming入门的更多相关文章
- Spark 基础操作
1. Spark 基础 2. Spark Core 3. Spark SQL 4. Spark Streaming 5. Spark 内核机制 6. Spark 性能调优 1. Spark 基础 1. ...
- 【原创 Hadoop&Spark 动手实践 5】Spark 基础入门,集群搭建以及Spark Shell
Spark 基础入门,集群搭建以及Spark Shell 主要借助Spark基础的PPT,再加上实际的动手操作来加强概念的理解和实践. Spark 安装部署 理论已经了解的差不多了,接下来是实际动手实 ...
- spark streaming 入门例子
spark streaming 入门例子: spark shell import org.apache.spark._ import org.apache.spark.streaming._ sc.g ...
- Spark基础脚本入门实践3:Pair RDD开发
Pair RDD转化操作 val rdd = sc.parallelize(List((1,2),(3,4),(3,6))) //reduceByKey,通过key来做合并val r1 = rdd.r ...
- Spark基础脚本入门实践1
1.创建数据框架 Creating DataFrames val df = spark.read.json("file:///usr/local/spark/examples/src/mai ...
- spark基础知识(1)
一.大数据架构 并发计算: 并行计算: 很少会说并发计算,一般都是说并行计算,但是并行计算用的是并发技术.并发更偏向于底层.并发通常指的是单机上的并发运行,通过多线程来实现.而并行计算的范围更广,他是 ...
- 初步了解Spark生态系统及Spark Streaming
一. 场景 ◆ Spark[4]: Scope: a MapReduce-like cluster computing framework designed for low-laten ...
- spark基础知识介绍2
dataframe以RDD为基础的分布式数据集,与RDD的区别是,带有Schema元数据,即DF所表示的二维表数据集的每一列带有名称和类型,好处:精简代码:提升执行效率:减少数据读取; 如果不配置sp ...
- 最全的spark基础知识解答
原文:http://www.36dsj.com/archives/61155 一. Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduc ...
- Spark基础学习精髓——第一篇
Spark基础学习精髓 1 Spark与大数据 1.1 大数据基础 1.1.1 大数据特点 存储空间大 数据量大 计算量大 1.1.2 大数据开发通用步骤及其对应的技术 大数据采集->大数据预处 ...
随机推荐
- Ubuntu virtualenv 创建 python3 虚拟环境 激活 退出
首先默认安装了virtualenv 创建python3虚拟环境 your-name@node-name:~/virtual_env$ virtualenv -p /usr/bin/python3 py ...
- SQL*Loader-704: Internal error: ulconnect: OCIServerAttach [0] ORA-12541: TNS:no listener
使用/app/oracle/product/11.2.0/bin/sqlldr导入数据报错: 监听没有开启?检查发现监正常 猜测是监听端口不是默认的1521有关系,直接在sid里面加上数据库服务器的i ...
- pycharm基本使用与破解
一.pycharm基本使用 pycharm这款ide软件虽然功能强大,但正因为他的强大,所以小白在刚使用这款软件时上手会有点难度,今天我们就来介绍一下ptcharm的基本使用. 1.基本配置 我们安装 ...
- Vulnstack内网靶场4
环境 漏洞详情 (qiyuanxuetang.net) 仅主机模式内网网段192.168.183.0/24 外网网段192.168.157.0/24 其中Ubuntu作为对外的内网机器 攻击机kali ...
- 模块化开发 | es6模块暴露与引入
CommonJS模块开发 CommonJS定义 每个文件就一个模块,有自己的作用域.在一个文件里面定义的变量.函数.类,都是私有的,对其他文件不可见. 私有作用域不会污染全局作用域. 模块可加载多次, ...
- pipeline学习
目录 一.常用语法 二.基础使用 三.使用 Groovy 沙盒 四.参数化构建过程 五.pipeline script from SCM 六.参考 一.常用语法 1.拉取git仓库代码 checkou ...
- kubernetes笔记
如果pod包含多个container, 这些container不会跨机器分布 每个container只运行一个进程,而不是在一个container运行多个进程,这样更容易处理进程异常重启,进程日志等问 ...
- 在Jenkins中执行 PowerShell 命令实现高效的CD/CI部署
相比于cmd,powershell支持插件.语法扩展和自定义扩展名,是智能化部署中闪闪的新星,越来越多的开发者偏爱使用Powershell. 如何让Jenkins支持Powershell呢?本文即展开 ...
- 安装mysql会出现start service错误
安装MySQL时无法启动服务(could not start the service MYSQL .Error:0)安装mysql会出现start service错误安装mysql时 配置到start ...
- [hdu6598]Harmonious Army
网络流建图,首先将所有价值加起来,用最小割考虑要删掉多少个价值:源点向每一个士兵连流量为x的边,士兵向汇点连流量为y的边,每一对关系间连流量为z的边,考虑有方程x1+y2+z=x2+y1+z=a+c, ...