Spark系列(八)Worker工作原理
工作原理图
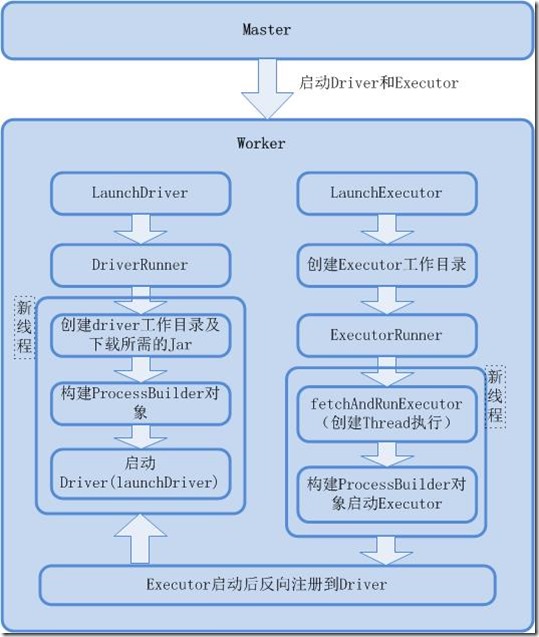
源代码分析
包名:org.apache.spark.deploy.worker
启动driver入口点:registerWithMaster方法中的case LaunchDriver
| 1 | ) => DriverState.FINISHED |
| 37 | case _ => DriverState.FAILED |
| 38 | } |
| 39 | } |
| 40 | |
| 41 | finalState = Some(state) |
| 42 | // 向Driver所属worker发送DriverStateChanged消息 |
| 43 | worker ! DriverStateChanged(driverId, state, finalException) |
| 44 | } |
| 45 | }.start() |
| 46 | } |
LaunchExecutor
管理LaunchExecutor的启动
| 1 | case LaunchExecutor(masterUrl, appId, execId, appDesc, cores_, memory_) => |
| 2 | if (masterUrl != activeMasterUrl) { |
| 3 | logWarning("Invalid Master (" + masterUrl + ") attempted to launch executor.") |
| 4 | } else { |
| 5 | try { |
| 6 | logInfo("Asked to launch executor %s/%d for %s".format(appId, execId, appDesc.name)) |
| 7 | |
| 8 | // Create the executor's working directory |
| 9 | // 创建executor本地工作目录 |
| 10 | val executorDir = new File(workDir, appId + "/" + execId) |
| 11 | if (!executorDir.mkdirs()) { |
| 12 | throw new IOException("Failed to create directory " + executorDir) |
| 13 | } |
| 14 | |
| 15 | // Create local dirs for the executor. These are passed to the executor via the |
| 16 | // SPARK_LOCAL_DIRS environment variable, and deleted by the Worker when the |
| 17 | // application finishes. |
| 18 | val appLocalDirs = appDirectories.get(appId).getOrElse { |
| 19 | Utils.getOrCreateLocalRootDirs(conf).map { dir => |
| 20 | Utils.createDirectory(dir).getAbsolutePath() |
| 21 | }.toSeq |
| 22 | } |
| 23 | appDirectories(appId) = appLocalDirs |
| 24 | // 创建ExecutorRunner对象 |
| 25 | val manager = new ExecutorRunner( |
| 26 | appId, |
| 27 | execId, |
| 28 | appDesc.copy(command = Worker.maybeUpdateSSLSettings(appDesc.command, conf)), |
| 29 | cores_, |
| 30 | memory_, |
| 31 | self, |
| 32 | workerId, |
| 33 | host, |
| 34 | webUi.boundPort, |
| 35 | publicAddress, |
| 36 | sparkHome, |
| 37 | executorDir, |
| 38 | akkaUrl, |
| 39 | conf, |
| 40 | appLocalDirs, ExecutorState.LOADING) |
| 41 | // executor加入本地缓存 |
| 42 | executors(appId + "/" + execId) = manager |
| 43 | manager.start() |
| 44 | // 增加worker已使用core |
| 45 | coresUsed += cores_ |
| 46 | // 增加worker已使用memory |
| 47 | memoryUsed += memory_ |
| 48 | // 通知master发送ExecutorStateChanged消息 |
| 49 | master ! ExecutorStateChanged(appId, execId, manager.state, None, None) |
| 50 | } |
| 51 | // 异常情况处理,通知master发送ExecutorStateChanged FAILED消息 |
| 52 | catch { |
| 53 | case e: Exception => { |
| 54 | logError(s"Failed to launch executor $appId/$execId for ${appDesc.name}.", e) |
| 55 | if (executors.contains(appId + "/" + execId)) { |
| 56 | executors(appId + "/" + execId).kill() |
| 57 | executors -= appId + "/" + execId |
| 58 | } |
| 59 | master ! ExecutorStateChanged(appId, execId, ExecutorState.FAILED, |
| 60 | Some(e.toString), None) |
| 61 | } |
| 62 | } |
| 63 | } |
总结
1、Worker、Driver、Application启动后都会向Master进行注册,并缓存到Master内存数据模型中
2、完成注册后发送LaunchExecutor、LaunchDriver到Worker
3、Worker收到消息后启动executor和driver进程,并调用Worker的ExecutorStateChanged和DriverStateChanged方法
4、发送ExecutorStateChanged和DriverStateChanged消息到Master的,根据各自的状态信息进行处理,最重要的是会调用schedule方法进行资源的重新调度
Spark系列(八)Worker工作原理的更多相关文章
- Spark系列(十)TaskSchedule工作原理
工作原理图 源码分析: 1.) 25 launchedTask = true 26 } 27 } catch { 28 ...
- Spark系列(九)DAGScheduler工作原理
以wordcount为示例进行深入分析 1 33 ) { 46 logInfo("Submitting " + tasks.size + " missi ...
- line-height系列——定义和工作原理总结
一.line-height的定义和工作原理总结 line-height的属性值: normal 默认 设置合理的行间距. number 设置数字,此数字会与当前的字体尺寸相乘来设置行间距li ...
- 源码分析八( hashmap工作原理)
首先从一条简单的语句开始,创建了一个hashmap对象: Map<String,String> hashmap = new HashMap<String,String>(); ...
- [Spark内核] 第32课:Spark Worker原理和源码剖析解密:Worker工作流程图、Worker启动Driver源码解密、Worker启动Executor源码解密等
本課主題 Spark Worker 原理 Worker 启动 Driver 源码鉴赏 Worker 启动 Executor 源码鉴赏 Worker 与 Master 的交互关系 [引言部份:你希望读者 ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
- How Javascript works (Javascript工作原理) (八) WebAssembly 对比 JavaScript 及其使用场景
个人总结: webworker有以下三种: Dedicated Workers 由主进程实例化并且只能与之进行通信 Shared Workers 可以被运行在同源的所有进程访问(不同的浏览的选项卡,内 ...
- 49、Spark Streaming基本工作原理
一.大数据实时计算介绍 1.概述 Spark Streaming,其实就是一种Spark提供的,对于大数据,进行实时计算的一种框架.它的底层,其实,也是基于我们之前讲解的Spark Core的. 基本 ...
- 46、Spark SQL工作原理剖析以及性能优化
一.工作原理剖析 1.图解 二.性能优化 1.设置Shuffle过程中的并行度:spark.sql.shuffle.partitions(SQLContext.setConf()) 2.在Hive数据 ...
随机推荐
- Android Intent个人介绍
在Android中要打开一个新的Activity, 不用说,肯定会用到Intent,Intent作为Android的四大组件之一,个人理解,Intent的作用就是用来在(其它三个不同组件)间进行通讯, ...
- 从输入 URL 到页面加载完的过程中都发生了什么---优化
这篇文章是转载自:安度博客,http://www.itbbu.com/1490.html 在很多地方看到,感觉不错,理清了自己之前的一些思路,特转过来留作记录. 一个HTTP请求的过程 为了简化我们先 ...
- C++STL之整理算法
这里主要介绍颠倒.旋转.随机排列和分类4中常见的整理算法 1.颠倒(反转) void reverse(_BidIt _First, _BidIt _Last) _OutIt reverse_copy( ...
- EXT 数据按F12,F11 显示问题
最近做关于EXT的项目,因为是刚开始接触EXT,对什么都不熟悉,所以把其他人写好的浏览页代码考过了来,换成自己需要的. 一切都做好了,然后数据不出来,就调试看,后台也出现数据了,然后就按F12调试前台 ...
- unison + inotify 实现文件实时双向同步部署步骤
unison + inotify 实现文件实时双向同步部署步骤 一. Unison简介 Unison是Windows.Linux以及其他Unix平台下都可以使用的文件同步工具,它能使两个文件夹(本地或 ...
- HDU 4607 Park Visit (DP最长链)
[题目]题意:N个城市形成一棵树,相邻城市之间的距离是1,问访问K个城市的最短路程是多少,共有M次询问(1 <= N, M <= 100000, 1 <= K <= N). [ ...
- Mysql,SqlServer,Oracle主键自动增长的设置
1.把主键定义为自动增长标识符类型 MySql 在mysql中,如果把表的主键设为auto_increment类型,数据库就会自动为主键赋值.例如: )); insert into customers ...
- Squid故障
1.COSS will not function without large file support (off_t is 4 bytes long. Please reconsider recomp ...
- Android平台下实现录音及播放录音功能的简介
录音及播放的方法如下: package com.example.audiorecord; import java.io.File; import java.io.IOException; import ...
- MyBatis学习 之 三、动态SQL语句
目录(?)[-] 三动态SQL语句 selectKey 标签 if标签 if where 的条件判断 if set 的更新语句 if trim代替whereset标签 trim代替set choose ...