1.6 dropout正则化
除了L2正则化,还有一个非常实用的正则化方法----dropout(随机失活),下面介绍其工作原理。
假设你在训练下图左边的这样的神经网络,它存在过拟合情况,这就是dropout所要处理的。我们复制这个神经网络,dropout会遍历网络每一层,并设置一个消除神经网络中节点的概率。
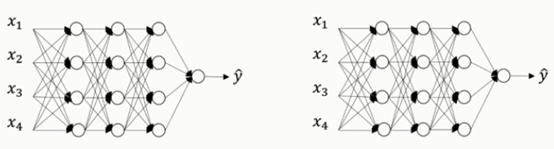
假设网络中的每一层,每个节点都以抛硬币的方式设置概率,每个节点得以保留和消除的概率都是0.5,设置完节点之后,我们会消除一些节点,然后删掉从该节点进出的连线,如下图,最后得到一个节点更少,规模更小的网络,然后用backprop方法进行训练。对于每个训练样本(每一个mini-batch),我们都将重复上述操作,以一定的概率消除网络节点,得到一个精简后的神经网络,然后训练这个神经网络。
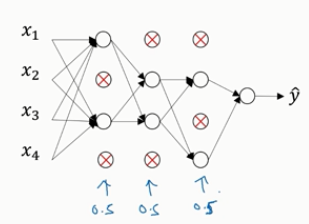
如何实施dropout呢?方法有几种,下面介绍最常见的,即inverted dropout(反向随机失活)。
下面我们用一个三层(L=3)的网络来举例说明。下面只举例说明如何在某一层中实施dropout。
首先要定义向量d,对d3表示第三层的dropout向量。
d3 = np.random.rand(a3.shape[0], a3.shape[1]) < keep_prob
看d3是否小于某个数keep_prob,keep_prob是一个具体数字,上面的示例中它是0.5,本例中设置keep_prob=0.8,它表示保留某个隐藏单元的概率,即此处意味着消除任意一个隐藏单元的概率是0.2。 它的作用是生成随机矩阵,如果对a3进行因子分解,效果也是一样的。d3是一个矩阵,其中d3中值为1的概率都是0.8,值为0的概率是20%。接下来要做的就是从第三层中获取激活函数,这里我们叫它a3,a3含有要计算的激活函数
a3=np.multiply(a3, d3) #a3*=d3
注:上面是对应元素相乘
它的作用就是过滤d3中所有等于0的元素。而各个元素等于0的概率只有20%,乘法运算最终把a3中相应的元素归零。
如果用python实现的话,d3就是一个布尔型数组,值为true或者false,而不是1或0。乘法运算依旧有效,python会把true和false翻译为1和0
最后我们向外扩展a3,即除以keep_prob参数
a3 /= keep_prob #所谓的dropout方法,功能是不论keep_prob的值时多少,反向随机失活(inverted dropout)方法通过除以keep_prob,以确保a3的期望值不变。
下面解释为什么要这么做
方便起见,假设第三层隐藏层有50个神经元,在一维上a3是50,我们通过因子分解将它拆分成50xm维的,保留和删除它们的概率分别是80%和20%,这意味着最后被删除或者归零的神经元平均有10个。
我们现在看看z4
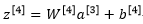
我们的预期是a3减少20%,也就是说a3中有20%的元素被归零,为了不影响z4的期望值,我们需要用w4*a3除以0.8,它将会修正或者说弥补我们所需的那20%,因此a3的期望值不会变。
事实证明,在测试阶段,当我们评估一个神经网络时,inverted dropout使得测试阶段变得更容易,因为它的数据扩展变得更容易。
目前实施dropout最常用的方法就是Inverted dropout
现在你使用的是d向量,你会发现不同的训练样本,清除不同的隐藏单元也不同,事实上,如果你通过相同训练集多次传递数据,每次训练数据的梯度不同,则随机对不同隐藏单元归零。
向量d或者d3用来决定第三层中哪些单元归零,无论在前向传播还是在反向传播的时候
如何在测试阶段训练算法?
在测试阶段,我们已经给出了x或者想预测变量,用的是标准计数法,a0表示第0层的激活函数标注为测试样本x,我们在测试阶段不使用dropout函数,尤其是像下面这种情况:
以此类推,直到最后一层预测值为y’
显然,在测试阶段,我们并没有使用dropout,自然也不需要随机将神经元失活,因为在测试阶段进行预测时,我们不期望输出的结果是随机的,如果在测试阶段应用dropout函数,预测会受到干扰,理论上,你只需要多次运行预测处理过程,每一次不同的隐藏单元会被随机归零,遍历它们并进行预测处理,这样得出的结果也几乎相同,但是计算效率低。
Inverted dropout函数除以keep_prob( /=keep_prob )这一操作,目的是确保即使是在测试阶段不执行dropout来调整数值范围,激活函数的预期结果也不会发生变化,所以没有必要在测试阶段额外添加尺度参数,这与训练阶段不同
内容主要来自与:
Andrew Ng的改善深层神经网络:超参数调试、正则化以及优化课程
1.6 dropout正则化的更多相关文章
- 吴恩达深度学习笔记(十一)—— dropout正则化
主要内容: 一.dropout正则化的思想 二.dropout算法流程 三.dropout的优缺点 一.dropout正则化的思想 在神经网络中,dropout是一种“玄学”的正则化方法,以减少过拟合 ...
- 9、改善深度神经网络之正则化、Dropout正则化
首先我们理解一下,什么叫做正则化? 目的角度:防止过拟合 简单来说,正则化是一种为了减小测试误差的行为(有时候会增加训练误差).我们在构造机器学习模型时,最终目的是让模型在面对新数据的时候,可以有很好 ...
- 【DeepLearning】深入理解dropout正则化
本文为转载,作者:Microstrong0305 来源:CSDN 原文:https://blog.csdn.net/program_developer/article/details/80737724 ...
- Dropout正则化和其他方法减少神经网络中的过拟合
1. 什么是Dropout(随机失活) 就是在神经网络的Dropout层,为每个神经元结点设置一个随机消除的概率,对于保留下来的神经元,我们得到一个节点较少,规模较小的网络进行训练. 标准网络和dro ...
- TensorFlow之DNN(三):神经网络的正则化方法(Dropout、L2正则化、早停和数据增强)
这一篇博客整理用TensorFlow实现神经网络正则化的内容. 深层神经网络往往具有数十万乃至数百万的参数,可以进行非常复杂的特征变换,具有强大的学习能力,因此容易在训练集上过拟合.缓解神经网络的过拟 ...
- (四) Keras Dropout和正则化的使用
视频学习来源 https://www.bilibili.com/video/av40787141?from=search&seid=17003307842787199553 笔记 使用drop ...
- 深度神经网络(DNN)的正则化
和普通的机器学习算法一样,DNN也会遇到过拟合的问题,需要考虑泛化,这里我们就对DNN的正则化方法做一个总结. 1. DNN的L1&L2正则化 想到正则化,我们首先想到的就是L1正则化和L2正 ...
- [DeeplearningAI笔记]改善深层神经网络1.4_1.8深度学习实用层面_正则化Regularization与改善过拟合
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.4 正则化(regularization) 如果你的神经网络出现了过拟合(训练集与验证集得到的结果方差较大),最先想到的方法就是正则化(re ...
- 机器学习中模型泛化能力和过拟合现象(overfitting)的矛盾、以及其主要缓解方法正则化技术原理初探
1. 偏差与方差 - 机器学习算法泛化性能分析 在一个项目中,我们通过设计和训练得到了一个model,该model的泛化可能很好,也可能不尽如人意,其背后的决定因素是什么呢?或者说我们可以从哪些方面去 ...
随机推荐
- laravel 原生 sql
1.插入数据 DB::insert('insert into users (id, name, email, password) values (?, ?, ? , ? )',[1, 'Laravel ...
- Android proguard (混淆)
混淆(Proguard)用法 最近项目中遇到一些混淆相关的问题,由于之前对proguard了解不多,所以每次都是面向Stackoverflow的编程.copy别人的答案内心还可以接受,但是copy了之 ...
- kill-mysql-sleep.sh
#!/bin/bash #while : #do n=`/usr/bin/mysqladmin -uroot -pXXXXX processlist | grep -i sleep | wc -l` ...
- Linux下导入SQL文件
导入数据库 一.首先建空数据库 格式: mysql>create database 数据库名;举例: mysql>create database abc; 二.导入数据库 方法一: 选择数 ...
- 多目标跟踪(MOT)论文随笔-SIMPLE ONLINE AND REALTIME TRACKING WITH A DEEP ASSOCIATION METRIC (Deep SORT)
网上已有很多关于MOT的文章,此系列仅为个人阅读随笔,便于初学者的共同成长.若希望详细了解,建议阅读原文. 本文是tracking by detection 方法进行多目标跟踪的文章,在SORT的基础 ...
- 作业07-Java GUI编程
1. 本周学习总结 1.1 思维导图:Java图形界面总结 1.2 可选:使用常规方法总结其他上课内容. 关于事件.事件源.事件监听器的总结: 事件:用户在GUI上进行的操作,如鼠标单击.输入文字.关 ...
- C语言——第四次作业
题目 题目一:计算分段函数 1.实验代码 #include <stdio.h> int main() { double x,y; scanf("%lf",&x) ...
- Linux下ftp和ssh详解
学习了几天Linux下ftp和ssh的搭建和使用,故记录一下.学习ftp和ssh的主要目的是为了连接远程主机,并且进行文件传输.废话不多说,直接开讲! ftp服务器 1. 环境搭建 本人的系统是Arc ...
- const volatile同时限定一个类型int a = 10
const和volatile放在一起的意义在于: (1)本程序段中不能对a作修改,任何修改都是非法的,或者至少是粗心,编译器应该报错,防止这种粗心: (2)另一个程序段则完全有可能修改,因此编译器最好 ...
- XCode Build Settings中几种Search Paths
Header search path:去查找头文件的路径,同在在你需要使用第三方库的时候,在这里设置你的头文件路径目录,如图 <code><span class="str& ...