Faster R-CNN
1.R-CNN
R-CNN网络架构图
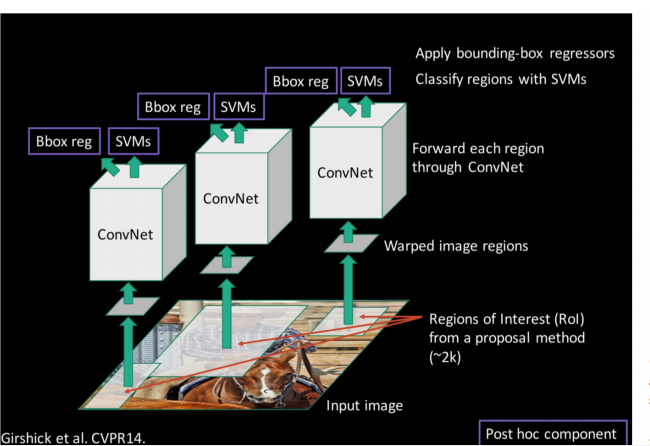
R-CNN网络框架流程
1)原图像经过 selective search算法提取约2000个候选框
2)候选框缩放到同一大小,原因是上图的ConvNet需要输入图片大小一致
3)通过ConvNet提取特征,原文ConvNet使用的是Alexnet,Alexnet需求的图片大小为(227*227),最后获得4096维特征向量
4)使用SVM对ConvNet提取的特征分类
使用4096维特征向量训练k个SVM分类器(k为分类数目),k个SVM分类器组成4096*k的矩阵N;把2000个候选框和4096维特征向量组合成2000*4096维矩阵M,
M和N做矩阵乘法得到2000*k的矩阵S,S中$s_{ij}$就是第i个候选框中属于第j个分类的概率
5)删除多余候选区域,边框回归
使用非极大值抑制NMS去除重叠候选区域,对SVM分好类的候选区域进行边框回归
2.SPP-Net
R-CNN存在2个大问题
- 大量重复计算,R-CNN要在2000个候选框中分别进行卷积提取特征
- 对候选框缩放,图像信息会丢失
SPP-Net就是为了解决这2个问题,SPP-Net架构图如下
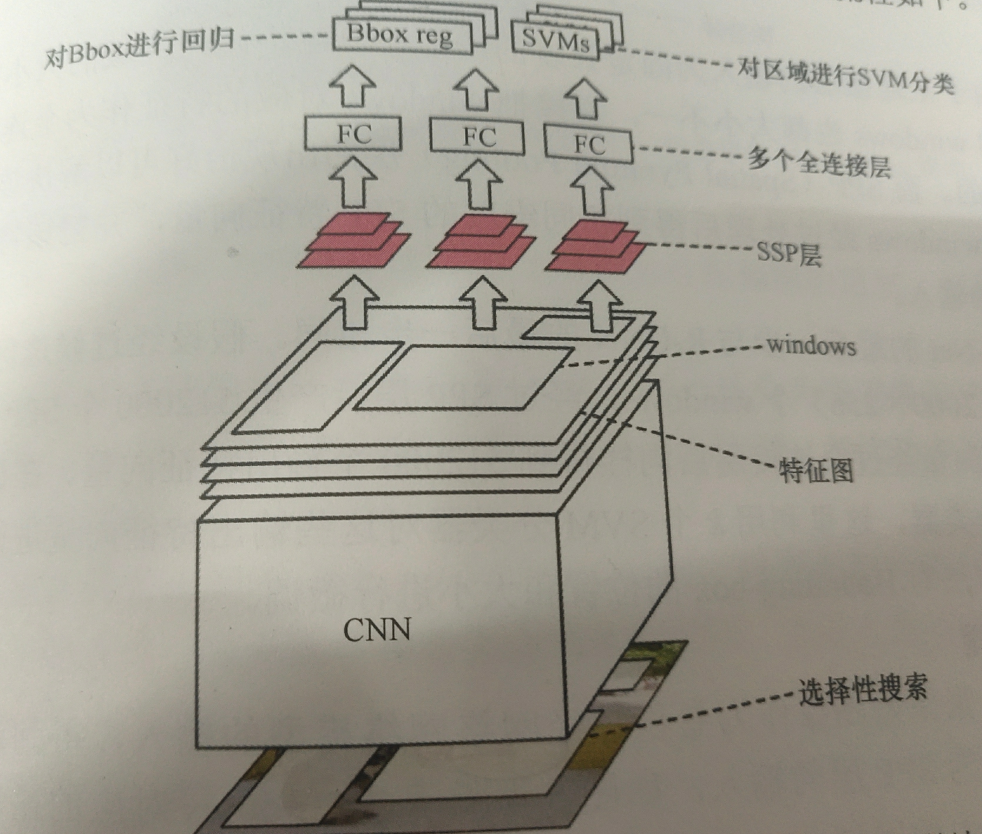
1)原图像经过 selective search算法提取约2000个候选框
2)通过CNN提取n个特征图
3)将 selective search算法提取的2000个候选框映射到n个feature map上,映射后的候选框叫windows,一共有2000*n个windows
4)把不同大小的windows经过SPP层处理为相同维度的特征向量,把特征向量作为FC的输入
SPP层架构图如下
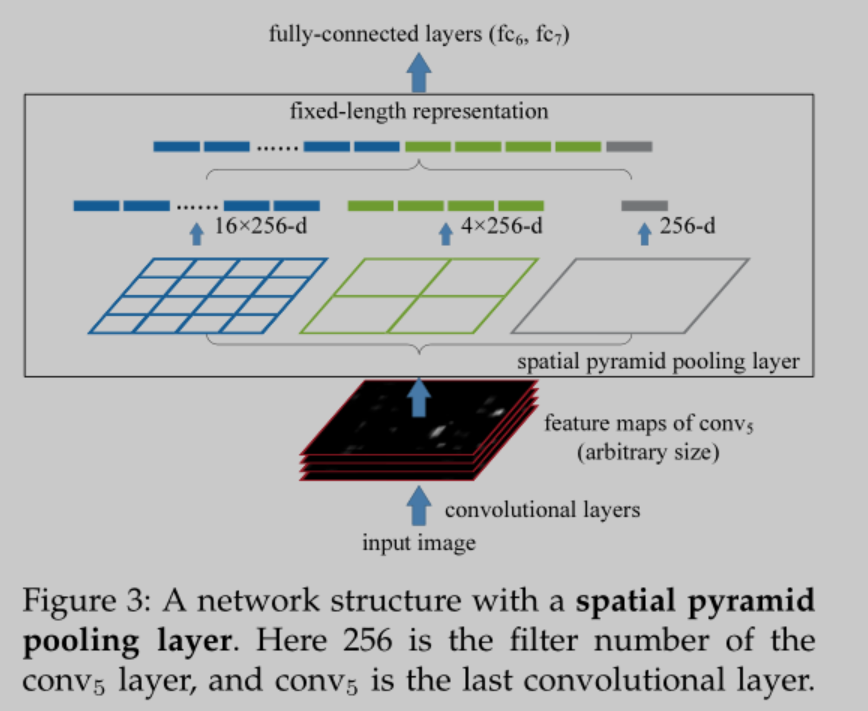
把每个w*h的window划分为4*4,2*2,1*1的网格,每个网格有(w/4,h/4)的特征,对每个网格进行Max Pooling,这样一个网格就只有1个最大的特征了。spatial pyramid pooling layer的第一个网格图有16维特征。3个网格图有21维特征,即一个window用21维向量表示,上图中feature map的深度n是256,256个feature map一共有256*2000个windows,最终2000个windows组成(2000,21,256)维特征向量输入到FC层
5)FC输出的特征向量使用SVM分类,并进行边框回归
3.Fast R-CNN
Fast R-CNN的创新主要体现在
- Rol Pooling层简化了SPP层,只使用了一个7*7的网格
- 用softmax替代SVM分类,把边框回归和分类合并为同一个多任务损失函数
Fast R-CNN架构图如下
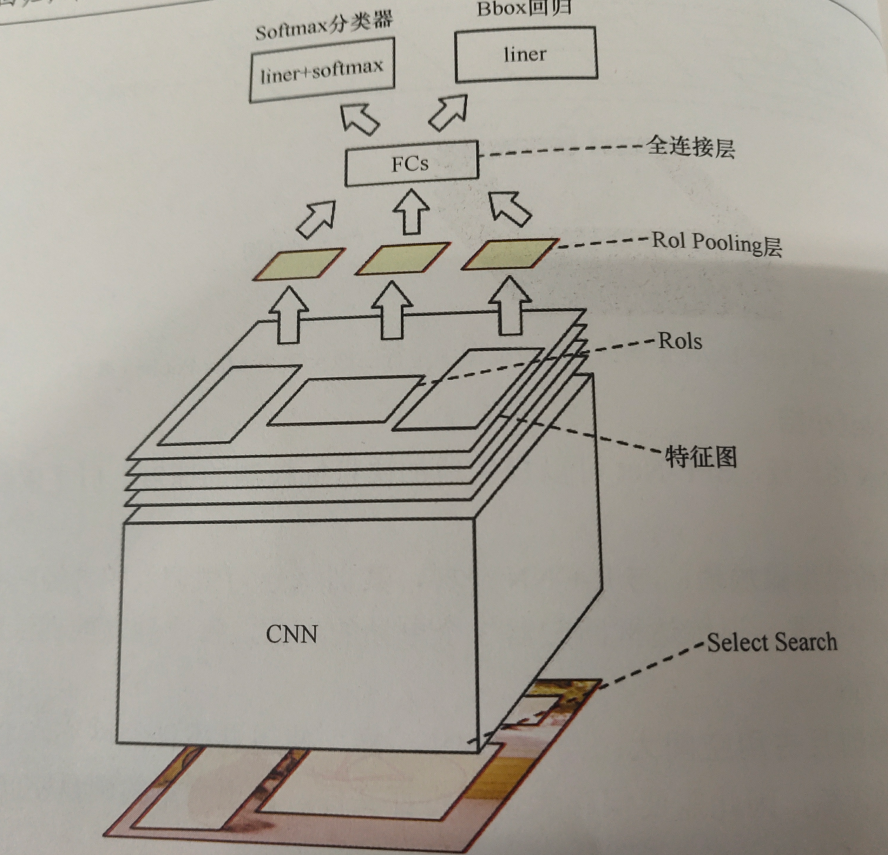
1)原图像经过 selective search算法提取约2000个候选框
2)通过ConvNet提取n个feature map
3)将 selective search算法提取的2000个候选框映射到n个feature map上,映射后的候选框叫Rols,一共有2000*n个Rols
4)把不同大小的Rols经过Rol Pooling层处理为相同维度的特征,此特征作为FC的输入
RoI Pooling层是一个简化版的spp layer,spp layer使用了4*4,2*2,1,*1的网格,RoI Pooling层只有一个7*7的网格。这样一个RoI就被表示成了一个(7*7,n)维特征,最终2000个候选框组成(2000,49,n)维特征作为FC输入
5)Rols通过FC后,用softmax分类,并进行边框回归
Fast R-CNN不在使用SVM分类,而是使用神经网络分类;同时利用多任务损失函数组合了分类和边框回归
Fast R-CNN的损失函数

其中$p_u$是softmax函数
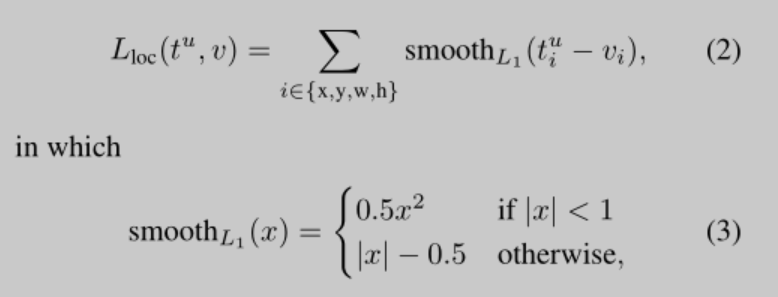

4.Faster R-CNN
Fast R-CNN的创新主要体现在
- 将之前网络的selective search算法提取候选框修改为使用RPN网络,真正实现了端到端训练
Faster R-CNN架构图
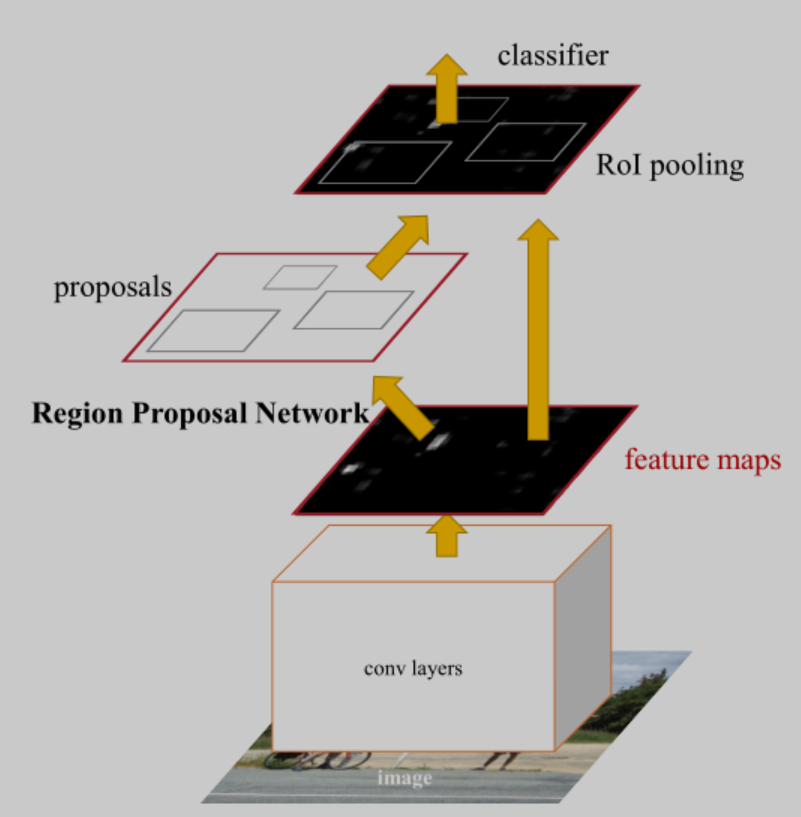
更加细节的图如下
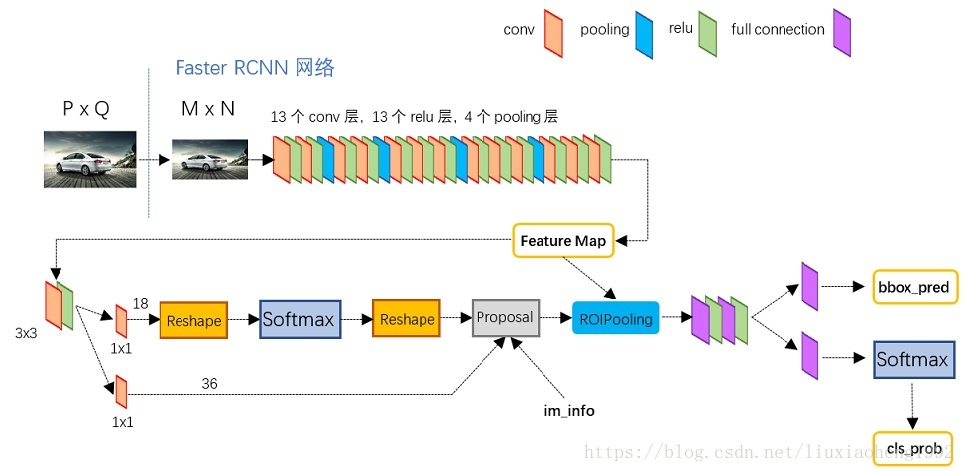
1)通过Conv layers提取n个feature map,这些feature map被RPN网络和Rol pooling层共享使用
Faster RCNN首先是支持输入任意大小的图片的,比如上图中输入的P*Q,进入网络之前对图片进行了规整化尺度的设定,如可设定图像短边不超过600,图像长边不超过1000,我们可以假定M*N=1000*600(如果图片少于该尺寸,可以边缘补0,即图像会有黑色边缘)
- 13个conv层:kernel_size=3,pad=1,stride=1;所以经过conv层不会改变图像尺寸
- 13个relu层:激活函数,不改变图片大小
- 4个pooling层:kernel_size=2,stride=2;pooling层会让输出图片是输入图片的1/2,
因此经过Conv layers,图片大小变成(M/16)*(N/16),即:60*40(1000/16≈60,600/16≈40);则
2)RPN网络以feature map为输入,输出候选区域框
RPN网络
输入RPN网络的60*40*512-d的feature map,首先使用kernel_size=3,pad=1,stride=1卷积,卷积完feature map尺寸不变,这样做的目的应该是进一步集中特征信息,原文中这个卷积核叫sliding window;一个sliding window的Receptive Field是228pixels ,各层feature map Receive Field
 $s_i$是stride
$s_i$是stride
知道了一个sliding window能看多大的区域后,就可以对sliding window里边的区域进行分类和边框回归了。
在分类和回归之前,首先要先在sliding window上生成一些框,用来框住其中的物体,这个框叫Anchor。
- Anchor的生成规则

这些anchor的面积分别为128*128,256*256,512*512
然后保持面积不变,改变长宽的比为1:1,1:2,2:1,最后生成9个anchor
- 分类和边框回归

如上图中标识:
① rpn_cls:60*40*512-d ⊕ 1*1*512*18 ==> 60*40*9*2
逐像素对其9个Anchor box进行二分类(foreground、background)
② rpn_bbox:60*40*512-d ⊕ 1*1*512*36==>60*40*9*4
逐像素得到其9个Anchor box四个坐标信息
如下图所示:

3)Rol Pooling层接收RPN网络输出的候选区域框和特征图,输出相同维度的特征给FC层
4)Rols通过FC后,用softmax分类,并进行边框回归
Reference
- https://www.cnblogs.com/skyfsm/p/6806246.html
- R-CNN:http://www.cnblogs.com/soulmate1023/p/5530600.html
- 深度学习原理与实践,陈钟铭
- Faster R-CNN:https://www.cnblogs.com/wangyong/p/8513563.html
- 感受野计算:https://blog.csdn.net/Kerrwy/article/details/82430530
Faster R-CNN的更多相关文章
- RCNN--对象检测的又一伟大跨越 2(包括SPPnet、Fast RCNN)(持续更新)
继续上次的学习笔记,在RCNN之后是Fast RCNN,但是在Fast RCNN之前,我们先来看一个叫做SPP-net的网络架构. 一,SPP(空间金字塔池化,Spatial Pyramid Pool ...
- 行为识别(action recognition)相关资料
转自:http://blog.csdn.net/kezunhai/article/details/50176209 ================华丽分割线=================这部分来 ...
- Should You Build Your Own Backtester?
By Michael Halls-Moore on August 2nd, 2016 This post relates to a talk I gave in April at QuantCon 2 ...
- [3 Jun 2015 ~ 9 Jun 2015] Deep Learning in arxiv
arXiv is an e-print service in the fields of physics, mathematics, computer science, quantitative bi ...
- 【计算机视觉】行为识别(action recognition)相关资料
================华丽分割线=================这部分来自知乎==================== 链接:http://www.zhihu.com/question/3 ...
- CVPR2020:三维实例分割与目标检测
CVPR2020:三维实例分割与目标检测 Joint 3D Instance Segmentation and Object Detection for Autonomous Driving 论文地址 ...
- [原]CentOS7安装Rancher2.1并部署kubernetes (二)---部署kubernetes
################## Rancher v2.1.7 + Kubernetes 1.13.4 ################ ##################### ...
- 利用python进行数据分析2_数据采集与操作
txt_filename = './files/python_baidu.txt' # 打开文件 file_obj = open(txt_filename, 'r', encoding='utf-8' ...
- Django项目:CRM(客户关系管理系统)--81--71PerfectCRM实现CRM项目首页
{#portal.html#} {## ————————46PerfectCRM实现登陆后页面才能访问————————#} {#{% extends 'king_admin/table_index.h ...
- [转]CNN目标检测(一):Faster RCNN详解
https://blog.csdn.net/a8039974/article/details/77592389 Faster RCNN github : https://github.com/rbgi ...
随机推荐
- django捡破烂
一 Django的model form组件 这是一个神奇的组件,通过名字我们可以看出来,这个组件的功能就是把model和form组合起来,先来一个简单的例子来看一下这个东西怎么用:比如我们的数据库 ...
- Python Threading问题:TypeError in Threading. function takes 1 positional argument but 100 were given
在使用python多线程module Threading时: import threading t = threading.Thread(target=getTemperature, args = ( ...
- Neutron: Load Balance as a Service(LBaaS)负载均衡
load balancer 负责监听外部的连接,并将连接分发到 pool member. LBaaS 有三个主要的概念: Pool Member,Pool 和 Virtual IP Pool M ...
- MediaManager配置公网访问功能
安装时设置传输本地地址及端口,如图: 路由器设置端口映射,如下图 使用时,打开公网地址http://IpAddress:8090/ContentManager/MainPage.aspx?zh-CN# ...
- Hyperscan-5.1.0 安装
安装依赖ragel ragel源码下载地址 编译安装 $ tar -xvf ragel-6.10.tar.gz $ cd ragel-6.10 $ ./configure $ make $ sudo ...
- JS学习笔记:(一)浏览器页面渲染机制
浏览器的内核主要分为渲染引擎和JS引擎.目前市面上常见的浏览器内核可以分为这四种:Trident(IE).Gecko(火狐).Blink(Chrome.Opera).Webkit(Safari).这里 ...
- Java 静态内部类的加载时机
参考文章:[https://www.cnblogs.com/maohuidong/p/7843807.html] 前言: 在看单例模式的时候,在网上找帖子看见其中有一种(IoDH) 实现单例的方式,其 ...
- TsinsenA1489 抽奖 【期望】
题目分析: 问题可以转化成将m个球放进n个盒子里,每个盒子的贡献为盒子中球数的平方. 第一问考虑增量. 对于一个原本有$x$个球的盒子,新加一个球的贡献是$2x+1$.期望条件下仍然满足. 第$i$个 ...
- 洛谷P5119 Convent 题解
题目 很好想的一道二分题,首先,二分一定满足单调性,而题目中非常明显的就是用的车越多,所用时间越少,所以可以枚举时间,判断是否可以比\(m\)少. 然后在二分时,更是要注意下标的一些问题,也要注意车和 ...
- AttributeError: 'NoneType' object has no attribute 'split' 报错处理
报错场景 social_django 组件对原生 django 的支持较好, 但是因为 在此DRF进行的验证为 JWT 方式 和 django 的验证存在区别, 因此需要进行更改自行支持 JWT 方式 ...