大数据学习(1)Hadoop安装
集群架构
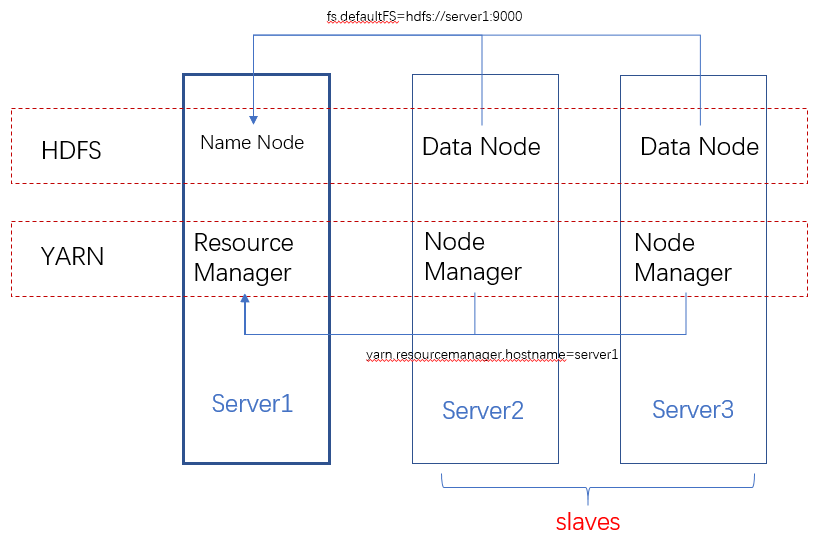
Hadoop的安装其实就是HDFS和YARN集群的配置,从下面的架构图可以看出,HDFS的每一个DataNode都需要配置NameNode的位置。同理YARN中的每一个NodeManager都需要配置ResourceManager的位置。
NameNode和ResourceManager的作用如此重要,在集群环境下,他们存在单点问题吗?在Hadoop1.0中确实存在,不过在2.0中已经得到解决,具体参考:
https://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-name-node/index.html
配置
因为每台机器上的配置都是一样的,所以配置时一般是配置好一台服务器,然后复制到其他服务器上。
JAVA_HOME
在hadoop-env.sh文件中配置JAVA_HOME.
core-site.xml
配置hdfs文件系统,通过fs.defaultFS配置hdfs的NameNode节点。
<property>
<name>fs.defaultFS</name>
<value>hdfs://{hdfs-name-node-server-host}:9000</value>
</property>
通过hadoop.tmp.dir配置hadoop运行时产生文件的存储目录
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-data/tmp</value>
</property>
hdfs-site.xml
配置文件副本数量和second namenode:
<property>
<name>dfs.replication</name>
<value>1</value>
</property> <property>
<name>dfs.secondary.http.address</name>
<value>{second-namenode-host}:50090</value>
</property>
yarn-site.xml
配置YARN的ResourceManager:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>{resource-manager-host}</value>
</property>
和reducer获取数据的方式:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
最后记得把hadoop的bin和sbin目录添加到环境变量中:
export HADOOP_HOME=/user/local/hadoop-2.6.5
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
格式化namenode
hdfs namenode -format (hadoop namenode -format)
启动Hadoop
先启动HDFS的NameNode:
hadoop-daemon.sh start datanode
在集群的DataNode上启动DataNode:
hadoop-daemon.sh start datanode
查看启动结果
[root@server1 ~]# jps
Jps
NameNode
如果启动成功,通过http://server1:50070,可以看到类似下面的页面:

再启动YARN
[root@vcentos1 sbin]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop-2.6./logs/yarn-root-resourcemanager-vcentos1.out
vcentos3: starting nodemanager, logging to /usr/local/hadoop-2.6./logs/yarn-root-nodemanager-vcentos3.out
vcentos2: starting nodemanager, logging to /usr/local/hadoop-2.6./logs/yarn-root-nodemanager-vcentos2.out
[root@server1 sbin]# jps
ResourceManager
Jps
NameNode
hadoop下的sbin目录下的文件是用来管理hadoop服务的:
hadoop-dameon.sh:用来单独启动namenode或datanode;
start/stop-dfs.sh:配合/etc/hadoop/slaves,可以批量启动/关闭NameNode和集群中的其他DataNode;
start/stop-yarn.sh:配合/etc/hadoop/slaves,可以批量启动/关闭ResourceManager和集群中的其他NodeManager;
bin目录下的文件可以提供hdfs、yarn和mapreduce服务:
[root@server1 bin]# hadoop fs
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] <localsrc> ... <dst>]
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] <path> ...]
[-cp [-f] [-p | -p[topax]] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] <path> ...]
[-expunge]
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] <src> <localdst>]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-usage [cmd ...]]
参考:
最新安装文档:http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/ClusterSetup.html
2.6.5安装文档:http://hadoop.apache.org/docs/r2.6.5/hadoop-project-dist/hadoop-common/SingleCluster.html
Secondary Namenode:http://blog.madhukaraphatak.com/secondary-namenode---what-it-really-do/
大数据学习(1)Hadoop安装的更多相关文章
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
- 大数据学习笔记——Hadoop编程实战之HDFS
HDFS基本API的应用(包含IDEA的基本设置) 在上一篇博客中,本人详细地整理了如何从0搭建一个HA模式下的分布式Hadoop平台,那么,在上一篇的基础上,我们终于可以进行编程实操了,同样,在编程 ...
- 大数据入门:Hadoop安装、环境配置及检测
目录 1.导包Hadoop包 2.配置环境变量 3.把winutil包拷贝到Hadoop bin目录下 4.把Hadoop.dll放到system32下 5.检测Hadoop是否正常安装 5.1在ma ...
- 大数据学习之Hadoop环境搭建
一.Hadoop的优势 1)高可靠性:因为Hadoop假设计算元素和存储会出现故障,因为它维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理. 2)高扩展性:在集群间分配任务数据,可方便的 ...
- 大数据学习笔记——Hadoop编程实战之Mapreduce
Hadoop编程实战——Mapreduce基本功能实现 此篇博客承接上一篇总结的HDFS编程实战,将会详细地对mapreduce的各种数据分析功能进行一个整理,由于实际工作中并不会过多地涉及原理,因此 ...
- 大数据学习之hadoop伪分布式集群安装(一)公众号undefined110
hadoop的基本概念: Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力进行高速运算和存储. Hadoo ...
- 大数据学习之Hadoop运行模式
一.Hadoop运行模式 (1)本地模式(默认模式): 不需要启用单独进程,直接可以运行,测试和开发时使用. (2)伪分布式模式: 等同于完全分布式,只有一个节点. (3)完全分布式模式: 多个节点一 ...
- 大数据学习笔记——Hadoop编程之SequenceFile
SequenceFile(Hadoop序列文件)基础知识与应用 上篇编程实战系列中本人介绍了基本的使用HDFS进行文件读写的方法,这一篇将承接上篇重点整理一下SequenceFile的相关知识及应用 ...
- 大数据学习笔记——Hadoop高可用完全分布式模式完整部署教程(包含zookeeper)
高可用模式下的Hadoop集群搭建 本篇博客将会在之前写过的Linux的完整部署的基础上进行,暂时不会涉及到伪分布式或者完全分布式模式搭建,由于HA模式涉及到的配置文件较多,维护起来也较为复杂,相信学 ...
- 大数据学习——yum练习安装mysql
1. 安装mysql 服务器端: yum install mysql-server yum install mysql-devel 2. 安装mysql客户端: yum install mysql 3 ...
随机推荐
- Ionic3 创建应用后,目录结构
ionic start myApp blank (空项目) hooks --编译cordova时自定义的脚本命令,方便整合到我们的编译系统和版本控制系统中 node_modules --node各类依 ...
- Javascript中的Trait与代码重用
Javascript中的Trait与代码重用 来源 http://www.ituring.com.cn/article/64103 我们知道,OOP中最普遍的代码重用方式是通过继承,但是,继承有一些缺 ...
- Winsock网络编程笔记(1)----入门
今天第一次接触winsock网络编程,看的资料是Windows网络编程第二版.通过博客记住自己的看书笔记.. 在这里贴出第一个程序,虽然程序什么都没做,但以此作为入门,熟悉其网络编程风格.. #inc ...
- javascript中原型链与instanceof 原理
instanceof:用来判断实例是否是属于某个对象,这个判断依据是什么呢? 首先,了解一下javascript中的原型继承的基础知识: javascript中的对象都有一个__proto__属性,这 ...
- cocos2d导入iOS原生项目
最近公司最新发下任务让融合一个cocos2dx写的游戏项目融合进现有项目,当看到要求时内心瞬间无数羊驼奔腾.------ 虽说内心是拒绝的,但是任务已经派发就必须要完成啊.所以在网上搜了大量的融入教程 ...
- layui数据表格以及传数据方式
数据表格一: <div style="margin:0px; background-color: white; margin:0 10px;"> <blockqu ...
- sql分区文件删不的可能解决方法
删除数据库分区的时候报错如下: ALTER DATABASE [ITMP2] remove FILE F20170427Msg 5042, Level 16, State 1, Line 1The f ...
- 用C#实现DES加密解密解决URL参数明文的问题
啥也不说,直接上代码. 加密解码,封装到一个类,key可以自己修改. using System; using System.Security.Cryptography; using System.Te ...
- org.springframework.web.filter.DelegatingFilterProxy的作用
一.类结构 DelegatingFilterProxy类继承GenericFilterBean,间接实现了Filter,故而该类属于一个过滤器.那么就会有实现Filter中init.doFilter. ...
- [转载] Java中动态加载jar文件和class文件
转载自http://blog.csdn.net/mousebaby808/article/details/31788325 概述 诸如tomcat这样的服务器,在启动的时候会加载应用程序中lib目录下 ...