Scrapy教程--豆瓣电影图片爬取
一、先上效果

二、安装Scrapy和使用
官方网址:https://scrapy.org/。
安装命令:pip install Scrapy
安装完成,使用默认模板新建一个项目,命令:scrapy startproject xx
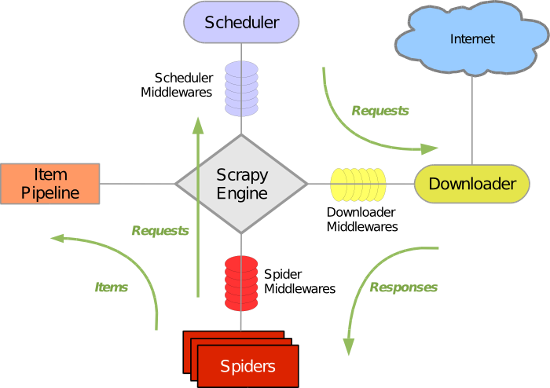
上图很形象的说明了,scrapy的运行机制。具体各部分的含义和作用,可自行百度,这里不再赘述。我们一般,需要做的是以下步骤。
1)配置settings,其他配置可根据自己的要求查看文档配置。
DEFAULT_REQUEST_HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.10 Safari/537.36'
}
DOWNLOAD_TIMEOUT = 30
IMAGES_STORE = 'Images'
2)定义items类,相当于Model类。如:
class CnblogImageItem(scrapy.Item):
image = scrapy.Field()
imagePath = scrapy.Field()
name = scrapy.Field()
3)配置下载中间件,下载中间件的作用是自定义,怎么发请求。一般有处理代理的中间件、PhantomJs的中间件等。这里,我们只用到代理中间件。
class GaoxiaoSpiderMiddleware(object):
def process_request(self, request, spider):
if len(request.flags) > 0 and request.flags[0] == 'img':
return None
driver = webdriver.PhantomJS()
# 设置全屏
driver.maximize_window()
driver.get(request.url)
content = driver.page_source
driver.quit()
return HtmlResponse(request.url, encoding='utf-8', body=content)
class ProxyMiddleWare(object):
def process_request(self, request, spider):
request.meta['proxy'] = 'http://175.155.24.103:808'
4)编写pipeline,作用是处理从Spider中传过来的item,保存excel、数据库、下载图片等。这里给出我的下载图片代码,使用的是官方的下载图片框架。
class CnblogImagesPipeline(ImagesPipeline):
IMAGES_STORE = get_project_settings().get("IMAGES_STORE") def get_media_requests(self, item, info):
image_url = item['image']
if image_url != '':
yield scrapy.Request(str(image_url), flags=['img']) def item_completed(self, result, item, info):
image_path = [x["path"] for ok, x in result if ok] if image_path:
# 重命名
if item['name'] != None and item['name'] != '':
ext = os.path.splitext(image_path[0])[1]
os.rename(self.IMAGES_STORE + '/' +
image_path[0], self.IMAGES_STORE + '/' + item['name'] + ext)
item["imagePath"] = image_path
else:
item['imagePath'] = ''
return item
5)编写自己的Spider类,Spider的作用是配置一些信息、起始url请求、处理响应数据。这里的下载中间件配置、pipeline,可以放在settings文件中。这里我放在,各自的Spider中,因为项目中包含多个Spider,相互之间用的下载中间件不同,因此分开配置了。
# coding=utf-8
import sys
import scrapy
import gaoxiao.items
import json
reload(sys)
sys.setdefaultencoding('utf-8') class doubanSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['movie.douban.com']
baseUrl = 'https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start='
start = 0
start_urls = [baseUrl + str(start)]
custom_settings = {
'DOWNLOADER_MIDDLEWARES': {
'gaoxiao.middlewares.ProxyMiddleWare': 1,
# 'gaoxiao.middlewares.GaoxiaoSpiderMiddleware': 544
},
'ITEM_PIPELINES': {
'gaoxiao.pipelines.CnblogImagesPipeline': 1,
}
} def parse(self, response):
data = json.loads(response.text)['subjects']
for i in data:
item = gaoxiao.items.CnblogImageItem()
if i['cover'] != '':
item['image'] = i['cover']
item['name'] = i['title']
else:
item['image'] = ''
yield item
if self.start < 400:
self.start += 20
yield scrapy.Request(self.baseUrl + str(self.start), callback=self.parse)
Scrapy教程--豆瓣电影图片爬取的更多相关文章
- 豆瓣电影信息爬取(json)
豆瓣电影信息爬取(json) # a = "hello world" # 字符串数据类型# b = {"name":"python"} # ...
- Python爬虫入门教程 8-100 蜂鸟网图片爬取之三
蜂鸟网图片--啰嗦两句 前几天的教程内容量都比较大,今天写一个相对简单的,爬取的还是蜂鸟,依旧采用aiohttp 希望你喜欢 爬取页面https://tu.fengniao.com/15/ 本篇教程还 ...
- Python爬虫入门教程 6-100 蜂鸟网图片爬取之一
1. 蜂鸟网图片--简介 国庆假日结束了,新的工作又开始了,今天我们继续爬取一个网站,这个网站为 http://image.fengniao.com/ ,蜂鸟一个摄影大牛聚集的地方,本教程请用来学习, ...
- Python爬虫入门教程 7-100 蜂鸟网图片爬取之二
蜂鸟网图片--简介 今天玩点新鲜的,使用一个新库 aiohttp ,利用它提高咱爬虫的爬取速度. 安装模块常规套路 pip install aiohttp 运行之后等待,安装完毕,想要深造,那么官方文 ...
- Python爬虫入门教程 5-100 27270图片爬取
27270图片----获取待爬取页面 今天继续爬取一个网站,http://www.27270.com/ent/meinvtupian/ 这个网站具备反爬,so我们下载的代码有些地方处理的也不是很到位, ...
- Python爬虫入门教程: 27270图片爬取
今天继续爬取一个网站,http://www.27270.com/ent/meinvtupian/ 这个网站具备反爬,so我们下载的代码有些地方处理的也不是很到位,大家重点学习思路,有啥建议可以在评论的 ...
- 豆瓣电影top250爬取并保存在MongoDB里
首先回顾一下MongoDB的基本操作: 数据库,集合,文档 db,show dbs,use 数据库名,drop 数据库 db.集合名.insert({}) db.集合名.update({条件},{$s ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- 第一个nodejs爬虫:爬取豆瓣电影图片
第一个nodejs爬虫:爬取豆瓣电影图片存入本地: 首先在命令行下 npm install request cheerio express -save; 代码: var http = require( ...
随机推荐
- 对数据缺失的处理(R)
在进行数据分析之前,我们往往需要对数据进行预处理,而最重要一部分就是怎么处理哪些缺失的数据. 通常的方法有四种: 删除这些缺失的数据. 用最高频数来补充缺失数据. 通过变量的相关关系来填充缺失值. 通 ...
- const常量类型
1.定义:const常量类型表示一个”常值变量“,其值是不能被修改的变量.即一旦变量被声明为const类型,编译器将禁止任何试图修改该变量的操作. 2.声明:const <声明数据类型> ...
- 火车站点城市查询(appserv 服务器练习)
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" ...
- HDU 2846 Trie查询
给出若干模式串,再给出若干询问串,求每个询问串作为多少个模式串的子串出现. 如果一个串是另一个串的子串,则一定是另一个串某个前缀的后缀或者某个后缀的前缀.根据字典树的性质,将模式串的每一个后缀插入字典 ...
- OnsenUI 前端框架(三)
上一章咱们学习了OnsenUI的工具栏.侧边栏和标签栏.通过对页面上这三部分的学习,咱们对混合应用的一个页面有了大体上的认识.从这一章开始,咱们学习OnsenUI混合项目开发过程中会用到的各种各样的组 ...
- Spring事务执行过程
先说一下启动过程中的几个点: 加载配置文件: AbstractAutowireCapableBeanFactory.doCreateBean --> initializeBean --> ...
- cmapx 保存绘制好的图层
研究了两天,如何保存一绘制好的图层,大致意思都说要使用mapInfo表,然后确定了可定和.TAB表有关.然而网上说的全是垃圾,也不能说全是垃圾,好歹我从中得到了一点点有用的信息,使用mapManage ...
- 最新的css3动画按钮效果
效果演示 插件下载
- 【算法系列学习】DP和滚动数组 [kuangbin带你飞]专题十二 基础DP1 A - Max Sum Plus Plus
A - Max Sum Plus Plus https://vjudge.net/contest/68966#problem/A http://www.cnblogs.com/kuangbin/arc ...
- 蓝桥杯-打印十字图-java
/* (程序头部注释开始) * 程序的版权和版本声明部分 * Copyright (c) 2016, 广州科技贸易职业学院信息工程系学生 * All rights reserved. * 文件名称: ...