亚马逊商品页面的简单爬取 --Pyhon网络爬虫与信息获取
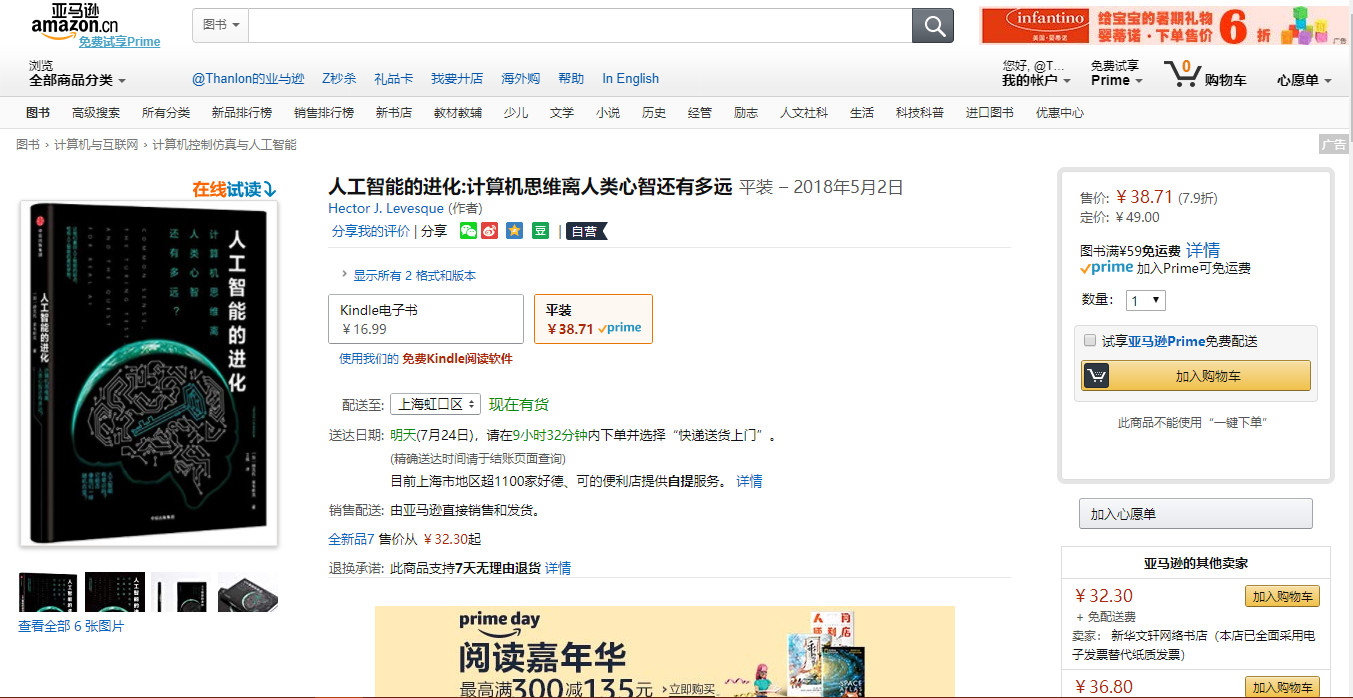
1、亚马逊商品页面链接地址(本次要爬取的页面url)
https://www.amazon.cn/dp/B07BSLQ65P/
2、代码部分
import requests
url = "https://www.amazon.cn/dp/B07BSLQ65P/"
try:
kv = {'user-agent': 'Mozilla/5.0'}
# 修改了发起请求的请求头中的user-agent的值,告诉目的url这是由浏览器发送的请求
r = requests.get(url, headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text)
except:
print("爬取页面失败!")
3、打印结果
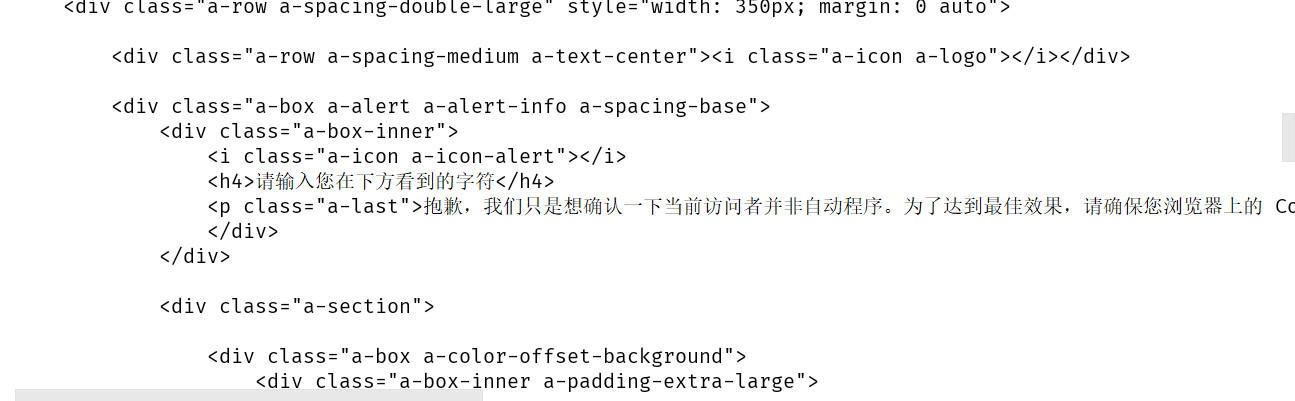
根据打印出的信息,很明显不是爬取到的目的url页面。可以将爬取到的页面在浏览器中打开,可以看到爬取到的其实是这样的页面:
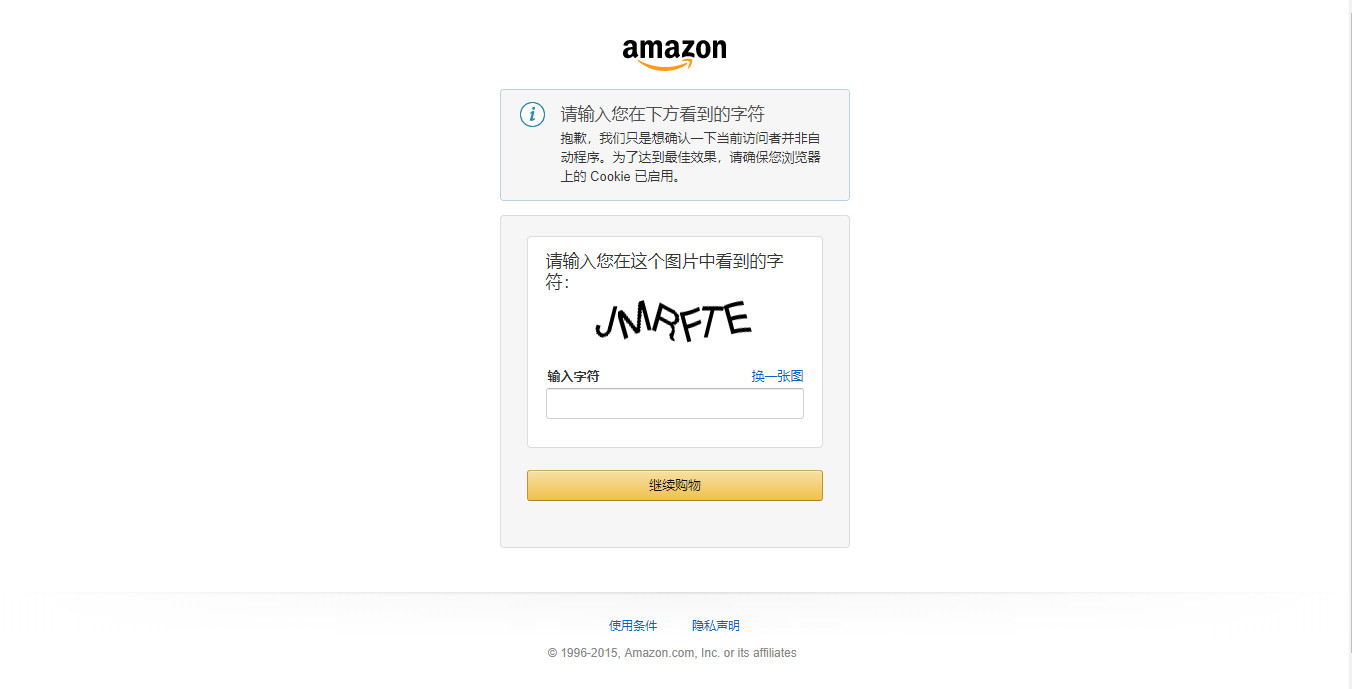
其实,这应该是亚马逊网站反爬虫的策略。对于如何爬取亚马逊商品页面,当然应该会有方法的,暂时先记录到这里吧!
亚马逊商品页面的简单爬取 --Pyhon网络爬虫与信息获取的更多相关文章
- 京东某商品页面的简单爬取 --Pyhon网络爬虫与信息获取
1.京东商品页面链接地址(本次要爬取的页面url) https://item.jd.hk/1953999200.html 2.代码部分 import requestsurl = "https ...
- 最简单的网络图片的爬取 --Pyhon网络爬虫与信息获取
1.本次要爬取的图片的url http://www.nxl123.cn/static/imgs/php.jpg 2.代码部分 import requestsimport osurl = "h ...
- python requests库网页爬取小实例:亚马逊商品页面的爬取
由于直接通过requests.get()方法去爬取网页,它的头部信息的user-agent显示的是python-requests/2.21.0,所以亚马逊网站可能会拒绝访问.所以我们要更改访问的头部信 ...
- 如何使用代理IP进行数据抓取,PHP爬虫抓取亚马逊商品数据
什么是代理?什么情况下会用到代理IP? 代理服务器(Proxy Server),其功能就是代用户去取得网络信息,然后返回给用户.形象的说:它是网络信息的中转站.通过代理IP访问目标站,可以隐藏用户的真 ...
- Python 网络爬虫与信息获取(二)—— 页面内容提取
1. 获取超链接 python获取指定网页上所有超链接的方法 links = re.findall(b'"((http|ftp)s?://.*?)"', html) links = ...
- JAVA爬取亚马逊的商品信息
在程序里面输入你想爬取的商品名字,就可以返回这件商品在亚马逊搜索中都所有相关商品的信息,包括名字和价格. 解决了在爬取亚马逊时候,亚马逊可以识别出你的爬虫,并返回503,造成只能爬取几个页面的问题. ...
- 基于Java实现简单亚马逊爬虫
前言:最近博主买了台Kindle,感觉亚马逊上的图书资源质量挺好,还时不时地会有价格低但质量高的书出售,但限于亚马逊并没有很好的优惠提醒功能,自己天天盯着又很累.于是,我自己写了一个基于Java的亚马 ...
- 最新亚马逊 Coupons 功能设置教程完整攻略!
最新亚马逊 Coupons 功能设置教程完整攻略! http://m.cifnews.com/app/postsinfo/18479 亚马逊总是有新的创意,新的功能.最近讨论很火的,就是这个 Coup ...
- 亚马逊开发者用户授权 AWS
在开发之前最好的方法是先拿到官网的API文档简单的预览一遍 这里有个中文文档:AWS 开发中文文档 需要准备: 注册成为开发者 创建 AWS 账户 创建 IAM 用户 创建 IAM 策略 创建 IAM ...
随机推荐
- 解决vi删除键和方向键奇怪的问题
sudo vi /etc/vim/vimrc.tiny 把 改为
- Testng测试报告
执行完测试用例之后,会在项目的test-output(默认目录)下生成测试报告
- Dart语言快速学习上手(新手上路)
Dart语言快速学习上手(新手上路) // 声明返回值 int add(int a, int b) { return a + b; } // 不声明返回值 add2(int a, int b) { r ...
- extjs的使用笔记2
系统的大部分资源(安装程序的除bin, lib, conf等之外的东西)都是放在 /usr/share/目录中的 在用户自己定义的, 一些关于系统资源的东西, 则放在目录 ~/.local/share ...
- MPU6050可以读取ID值,温度值和原始数据值为零问题解决
MPU6050可以读取ID值是0x68,但是读取到的原始数据为零(下面虚拟示波器图中温度值是36.529是单位转换公式中的值被打印出来了,实际值也是零).经论坛搜寻,发现MPU6050出现问题的原因有 ...
- 在 JSDOM v11 中使用jQuery
在JSDOM v11中使用jQuery 从v10开始,jsdom提供了更灵活的API. https://swashata.me/blog/use-jquery-jsdom-v11/ const tes ...
- SAP月结操作讲解
SAP月结操作讲解 https://wenku.baidu.com/view/ac6fe45d312b3169a451a4b9.html 步聚 操作内容 事务码 是否必须 操作时间 月/年结 1 ...
- HDU 5754 Life Winner Bo(各类博弈大杂合)
http://acm.hdu.edu.cn/showproblem.php?pid=5754 题意: 给一个国际象棋的棋盘,起点为(1,1),终点为(n,m),现在每个棋子只能往右下方走,并且有4种不 ...
- 集成算法——Ensemble learning
目的:让机器学习效果更好,单个不行,群殴啊! Bagging:训练多个分类器取平均 Boosting:从弱学习器开始加强,通过加权来进行训练 (加入一棵树,比原来要强) Stacking:聚合多个分类 ...
- C++类模板和模板类
C++ 中有一个重要特性,那就是模板类型.类似于Objective-C中的泛型.C++通过类模板来实现泛型支持. 1 基础的类模板 类模板,可以定义相同的操作,拥有不同数据类型的成员属性. 通常使用t ...