django博客项目8:文章详情页
首页展示的是所有文章的列表,当用户看到感兴趣的文章时,他点击文章的标题或者继续阅读的按钮,应该跳转到文章的详情页面来阅读文章的详细内容。现在让我们来开发博客的详情页面,有了前面的基础,开发流程都是一样的了:首先配置 URL,即把相关的 URL 和视图函数绑定在一起,然后实现视图函数,编写模板并让视图函数渲染模板。
设计文章详情页的 URL
回顾一下我们首页视图的 URL,在 blog\urls.py 文件里,我们写了:
blog/urls.py from django.conf.urls import url from . import views urlpatterns = [
url(r'^$', views.index, name='index'),
]
首页视图匹配的 URL 去掉域名后其实就是一个空的字符串。对文章详情视图而言,每篇文章对应着不同的 URL。比如我们可以把文章详情页面对应的视图设计成这个样子:当用户访问 <网站域名>/post/1/ 时,显示的是第一篇文章的内容,而当用户访问 <网站域名>/post/2/ 时,显示的是第二篇文章的内容,这里数字代表了第几篇文章,也就是数据库中 Post 记录的 id 值。下面依照这个规则来绑定 URL 和视图:
blog/urls.py from django.conf.urls import url from . import views app_name = 'blog'
urlpatterns = [
url(r'^$', views.index, name='index'),
url(r'^post/(?P<pk>[0-9]+)/$', views.detail, name='detail'),
]
Django 使用正则表达式来匹配用户访问的网址。这里 r'^post/(?P<pk>[0-9]+)/$' 整个正则表达式刚好匹配我们上面定义的 URL 规则。这条正则表达式的含义是,以 post/ 开头,后跟一个至少一位数的数字,并且以 / 符号结尾,如 post/1/、 post/255/ 等都是符合规则的,[0-9]+ 表示一位或者多位数。此外这里 (?P<pk>[0-9]+) 表示命名捕获组,其作用是从用户访问的 URL 里把括号内匹配的字符串捕获并作为关键字参数传给其对应的视图函数 detail。比如当用户访问 post/255/ 时(注意 Django 并不关心域名,而只关心去掉域名后的相对 URL),被括起来的部分 (?P<pk>[0-9]+) 匹配 255,那么这个 255 会在调用视图函数 detail 时被传递进去,实际上视图函数的调用就是这个样子:detail(request, pk=255)。我们这里必须从 URL 里捕获文章的 id,因为只有这样我们才能知道用户访问的究竟是哪篇文章。
from django.shortcuts import render,redirect
from .models import Post def index(request):
.................. #详细页面视图
def detail(request,pk):
post =Post.objects.filter(id=pk).first() #通过filter函数取得数据第一条数据,不存在则返回空。
if not post:
#当数据不存在是,则跳转到首页,使用redirect, '/'--表示网站首页
return redirect('/')
else:
return render(request,'blog/detail.html',{'post':post})
视图函数很简单,它根据我们从 URL 捕获的文章 id(也就是 pk,这里 pk 和 id 是等价的)获取数据库中文章 id 为该值的记录,然后传递给模板。注意这里我们用到了从 django.shortcuts 模块导入的 redirect 方法,其作用就是当传入的 pk 对应的 Post 在数据库存在时,页面重新跳转到网站首页地址
编写详情页模板
接下来就是书写模板文件,从下载的博客模板(如果你还没有下载,请 点击这里 下载)中把 single.html 拷贝到 templates\blog 目录下(和 index.html 在同一级目录),然后改名为 detail.html。此时你的目录结构应该像这个样子:
blogproject\
manage.py
blogproject\
__init__.py
settings.py
...
blog/
__init__.py
models.py
,,,
templates\
blog\
index.html
detail.html
在 index 页面博客文章列表的标题和继续阅读按钮写上超链接跳转的链接,即文章 post 对应的详情页的 URL,让用户点击后可以跳转到 detail 页面:
{% for post in post_list%}
<article class="post post-{{ post.id }}">
<header class="entry-header">
<h1 class="entry-title">
<a href="/post/{{post.id}}/">{{post.title}}</a>
</h1>
<div class="entry-meta">
。。。。。。。
</div>
</header>
<div class="entry-content clearfix">
<p>{{post.excerpt}}</p>
<div class="read-more cl-effect-14">
<a href="{% url 'detail' post.id %}" class="more-link">继续阅读 <span class="meta-nav">→</span></a>
</div>
</div>
</article>
{% empty %}
<div class="no-post">暂时还没有发布的文章!</div>
{% endfor %}
这里我们修改两个地方,第一个是文章标题处:(自己拼接的方式,将地址拼接成路由urls.py相对应的地址格式,赋值给a标签的href属性)
<h1 class="entry-title">
<a href="/post/{{post.id}}/">{{post.title}}</a>
</h1>
同样,第二处修改的是继续阅读按钮的链接:(这里使用template url方式,动态生成地址{% url 'detail' post.id %} 中的‘detail’ 是url()中定义的第三个参数name='detail')
<div class="read-more cl-effect-14">
<a href="{% url 'detail' post.id %}" class="more-link">继续阅读 <span class="meta-nav">→</span></a>
</div>
这样当我们点击首页文章的标题或者继续阅读按钮后就会跳转到该篇文章对应的详情页面了。然而如果你尝试跳转到详情页后,你会发现样式是乱的。这在 真正的 Django 博客首页 时讲过,由于我们是直接复制的模板,还没有正确地处理静态文件。我们可以按照介绍过的方法修改静态文件的引入路径,但很快你会发现在任何页面都是需要引入这些静态文件,如果每个页面都要修改会很麻烦,而且代码都是重复的。下面就介绍 Django 模板继承的方法来帮我们消除这些重复操作。
模板继承
我们看到 index.html 文件和 detail.html 文件除了 main 标签包裹的部分不同外,其它地方都是相同的,我们可以把相同的部分抽取出来,放到 base.html 里。首先在 templates\blog 目录下新建一个 base.html 文件,这时候你的项目目录应该变成了这个样子:
blogproject\
manage.py
blogproject\
__init__.py
settings.py
...
blog\
__init__.py
models.py
,,,
templates\
blog\
index.html
detail.html base.html
把 index.html 的内容全部拷贝到 base.html 文件里,然后删掉 main 标签包裹的内容,替换成如下的内容。
templates/base.html ...
<main class="col-md-8">
{% block main %}
{% endblock main %}
</main>
<aside class="col-md-4">
{% block toc %}
{% endblock toc %}
...
</aside>
...
这里 block 也是一个模板标签,其作用是占位。比如这里的 {% block main %}{% endblock main %} 是一个占位框,main 是我们给这个 block 取的名字。下面我们会看到 block 标签的作用。同时我们也在 aside 标签下加了一个 {% block toc %}{% endblock toc %} 占位框,因为 detail.html 中 aside 标签下会多一个目录栏。当 {% block toc %}{% endblock toc %} 中没有任何内容时,{% block toc %}{% endblock toc %} 在模板中不会显示。但当其中有内容是,模板就会显示 block 中的内容。
在 index.html 里,我们在文件最顶部使用 {% extends 'base.html' %} 继承 base.html,这样就把 base.html 里的代码继承了过来,另外在 {% block main %}{% endblock main %} 包裹的地方填上 index 页面应该显示的内容:
templates/blog/index.html
{% extends 'base.html' %}
{% block main %}
{% for post in post_list %}
<article class="post post-1">
...
</article>
{% empty %}
<div class="no-post">暂时还没有发布的文章!</div>
{% endfor %}
<!-- 简单分页效果
<div class="pagination-simple">
<a href="#">上一页</a>
<span class="current">第 6 页 / 共 11 页</span>
<a href="#">下一页</a>
</div>
-->
<div class="pagination">
...
</div>
{% endblock main %}
这样 base.html 里的代码加上 {% block main %}{% endblock main %} 里的代码就和最开始 index.html 里的代码一样了。这就是模板继承的作用,公共部分的代码放在 base.html 里,而其它页面不同的部分通过替换 {% block main %}{% endblock main %} 占位标签里的内容即可。
如果你对这种模板继承还是有点糊涂,可以把这种继承和 Python 中类的继承类比。base.html 就是父类,index.html 就是子类。index.html 继承了 base.html 中的全部内容,同时它自身还有一些内容,这些内容就通过 “覆写” {% block main %}{% endblock main %}(把 block 看做是父类的属性)的内容添加即可。
detail 页面处理起来就简单了,同样继承 base.html ,在 {% block main %}{% endblock main %} 里填充 detail.html 页面应该显示的内容,以及在 {% block toc %}{% endblock toc %} 中填写 base.html 中没有的目录部分的内容。不过目前的目录只是占位数据,我们在以后会实现如何从文章中自动摘取目录。
templates/blog/detail.html
{% extends 'base.html' %}
{% block main %}
<article class="post post-1">
...
</article>
<section class="comment-area">
...
</section>
{% endblock main %}
{% block toc %}
<div class="widget widget-content">
<h3 class="widget-title">文章目录</h3>
<ul>
<li>
<a href="#">教程特点</a>
</li>
<li>
<a href="#">谁适合这个教程</a>
</li>
<li>
<a href="#">在线预览</a>
</li>
<li>
<a href="#">资源列表</a>
</li>
<li>
<a href="#">获取帮助</a>
</li>
</ul>
</div>
{% endblock toc %}
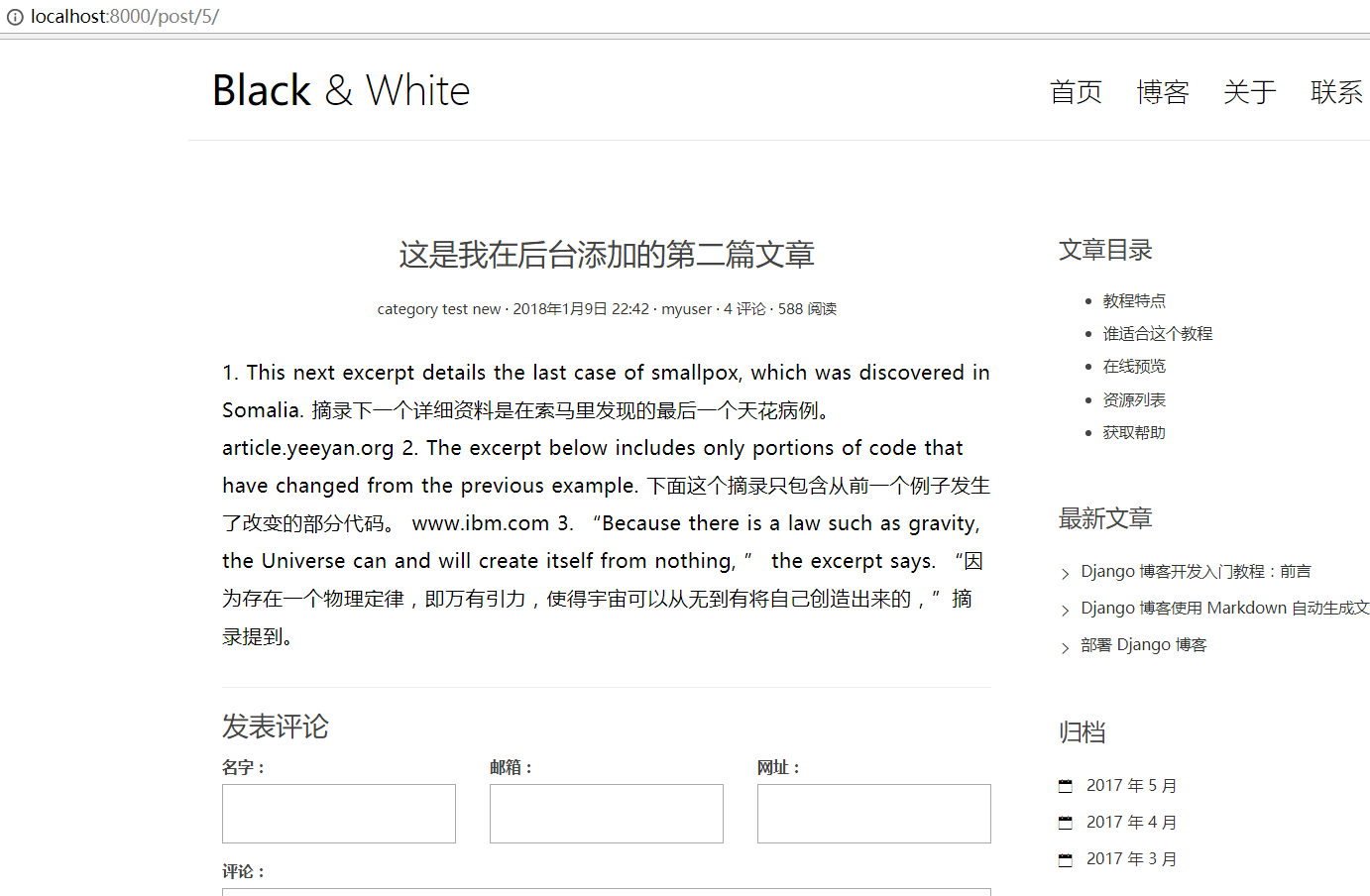
修改 article 标签下的一些内容,让其显示文章的实际数据:
<article class="post post-{{ post.pk }}">
<header class="entry-header">
<h1 class="entry-title">{{ post.title }}</h1>
<div class="entry-meta">
<span class="post-category"><a href="#">{{ post.category.name }}</a></span>
<span class="post-date"><a href="#"><time class="entry-date"
datetime="{{ post.created_time }}">{{ post.created_time }}</time></a></span>
<span class="post-author"><a href="#">{{ post.author }}</a></span>
<span class="comments-link"><a href="#">4 评论</a></span>
<span class="views-count"><a href="#">588 阅读</a></span>
</div>
</header>
<div class="entry-content clearfix">
{{ post.body }}
</div>
</article>
再次从首页点击一篇文章的标题或者继续阅读按钮跳转到详情页面,可以看到预期效果了!
django博客项目8:文章详情页的更多相关文章
- python 全栈开发,Day81(博客系统个人主页,文章详情页)
一.个人主页 随笔分类 需求:查询当前站点每一个分类的名称以及对应的文章数 完成这个需求,就可以展示左侧的分类 它需要利用分组查询,那么必须要会基于双下划线的查询. 基于双下划线的查询,简单来讲,就是 ...
- django博客项目6:Django Admin 后台发布文章
在此之前我们完成了 Django 博客首页视图的编写,我们希望首页展示发布的博客文章列表,但是它却抱怨:暂时还没有发布的文章!如它所言,我们确实还没有发布任何文章,本节我们将使用 Django 自带的 ...
- Django——博客项目
博客项目 目前的目标是构建一个基于Django的前后端完整的博客系统,首先对项目流程整理如下: 1. 分析需求 1.1. 基于用户认证组件和Ajax实现登录验证 图形验证码核心代码: 模板: < ...
- django博客项目5:博客首页视图(2)
真正的 Django 博客首页视图 在此之前我们已经编写了 Blog 的首页视图,并且配置了 URL 和模板,让 Django 能够正确地处理 HTTP 请求并返回合适的 HTTP 响应.不过我们仅仅 ...
- django博客项目3:创建 Django 博客的数据库模型
设计博客的数据库表结构 博客最主要的功能就是展示我们写的文章,它需要从某个地方获取博客文章数据才能把文章展示出来,通常来说这个地方就是数据库.我们把写好的文章永久地保存在数据库里,当用户访问我们的博客 ...
- django博客项目2.建立 Django 博客应用
建立博客应用 我们已经建立了 Django 博客的项目工程,并且成功地运行了它.不过到目前为止这一切都还只是 Django 为我们创建的项目初始内容,Django 不可能为我们初始化生成博客代码,这些 ...
- django博客项目1.环境搭建
安装 Python Windows 下安装 Python 非常简单,去 Python 官方网站找到 Python 3 的下载地址,根据你的系统选择 32 位或者 64 位的安装包,下载好后双击安装即可 ...
- 9.28 Django博客项目(一)
2018-9-28 17:37:18 今天把博客项目 实现了注册和添加图片的功能! 放在了自己的github上面 源码! https://github.com/TrueNewBee/bbs_demo ...
- <Django>博客项目
0.项目的通用流程 项目立项 需求分析 原型 前端 页面设计 UI及交互实现 后端 架构设计 数据库设计 代码模板实现 单元测试 网站整合 功能及集成测试 网站发布 1.BBS项目需求分析 需要哪些表 ...
随机推荐
- thread_CountDownLatch同步计数器
CountDownLatch类是一个同步计数器,构造时传入int参数,该参数就是计数器的初始值,每调用一次countDown()方法,计数器减1,计数器大于0 时,await()方法会阻塞程序继续执行 ...
- nyoj 460 项链 (区间dp)
项链 时间限制:1000 ms | 内存限制:65535 KB 难度:3 描述 在Mars星球上,每个Mars人都随身佩带着一串能量项链.在项链上有N颗能量珠.能量珠是一颗有头标记与尾标记的珠子, ...
- Window 窗口类
窗口类 WNDCLASS 总结 总结为下面的几个问题: . 什么是窗口类 . 窗口类的三种类型 . 窗口类各字段含义 . 窗口类的注册和注销 . 如何使用窗口类,子类化.超类化是什么 下面分别描述: ...
- js arguments 内置对象
1.arguments是js的内置对象. 2.在不确定对象是可以用来重载函数. 3.用法如下: function goTo() { var i=arguments.length; alert(i); ...
- 实现DIV居中的几种方法
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- java集成开发环境常用操作集
1.简单搭建maven集成开发环境 一. Jetty安装 下载地址(包涵windows和Linux各版本,Jetty9需要JDK7):http://download.eclipse.org/j ...
- PHP——上传头像(1)
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- 用docker搭建测试环境--docker的基本操作
上一篇文章中最后执行了docker pull centos的指令,经过一段时间的等待,会从hub.docker.com上下载docker官方最新的centos的images,接下来熟悉一下docker ...
- xaf 学习 RuleUniqueValueAttribute 唯一验证。
xaf 学习 RuleUniqueValueAttribute 唯一验证. RuleUniqueValue("", DefaultContexts.Save, CriteriaE ...
- sublime3 10款必备插件
http://www.cnblogs.com/lhb25/p/10-essential-sublime-text-plugins.html