优化MySchool数据库设计总结
数据库的设计
一:什么是数据库设计?
数据库设计就是将数据库中的数据实体以及这些数据实体之间的关系,进行规范和结构化的过程.
二:为什么要实施数据库设计?
1:良好的数据库设计可以有效的解决数据冗余的问题
2:效率高
3:便于进一步扩展
4:使得应用程序开发变得容易
三:设计数据库的步骤
第一步 需求分析: 分析客户的业务和数据处理需求(收集信息,标识实体,标识每个实体需要存储的详细信息,标识实体间的关系)
第二步 概要设计: 绘制E-R图,用于与客户或团队成员的交流
第三步 详细设计: 将E-R图转换成多张表,进行逻辑设计,应用数据库设计的三大范式进行审核,选择具体的数据库然后建库建表建约束,创建完成开始编写代码,开发前端应用程序.
四:绘制E-R图
(1) 什么是实体?
实体是指现实世界中具有区分其他事物的特征或属性并与其他实体有联系的实体(实体一般是名词)
严格来说,实体是指表中一行特定的数据,也常常把表称为一个实体
(2)什么是属性?
属性可以理解为实体的特征,属性对应表中的列
(3)什么是联系?
联系是两个或多个实体之间的关联关系(一般是动词)
(4)什么是映射基数?
映射基数是表示通过联系与该实体关联的其他实体的个数,具体有 一对一 , 一对多, 多对一, 多对多.
(5)什么是关系实体图?
E-R图以图形的方式将数据库的整个逻辑结构表示出来. 矩形表示实体集;椭圆表示属性;菱形表示联系集;
直线用来连接属性和实体集,也用来联系实体集和联系集.
例如,酒店管理系统中E-R图:

五:绘制数据库模型图
例如:酒店管理系统数据库模型图
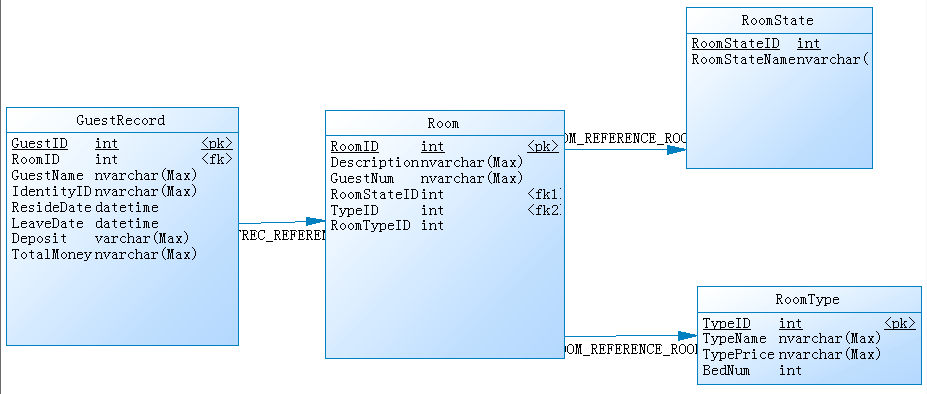
六:数据规范化
规范设计
第一范式:
第一范式的目标是确保每列的原子性,如果每列都是不可再分的最小单元(也称为最小的原子单元),则满足第一范式
第二范式:
如果一个关系满足第一范式,并且除主键以外的其他列,都依赖于该主建,则满足第二范式,第二范式要求一张表只描述一件事情
第三范式:
如果一个关系满足第二范式,并且除了主键以外的其他列都不传递依赖于主键列,则满足第三范式
注:第二范式是其他列都依赖于主键列但是没有说明是直接依赖还是间接依赖,也就是直接依赖和间接依赖均可,但第三范式明确指出只能是直接依赖,如果出现间接依赖的情况,要单独创建一张表出来
七:规范化和性能的关系
为了满足某种商业目标,数据库性能比规范数据库更重要
具体策略和方法:
(1):通过在给定的表中添加额外字段,以大量减少需要从中搜索信息所需要的时间
(2):通过在给定的表中插入计算列(比如成绩总分),以方便查询
在数据库规范时,要综合考虑数据库性能.
用SQL语句建库建表建约束(用SQl语句在指定盘符创建文件夹)
一 :创建数据库
创建一个数据文件和一个日志文件(MySchool)
create database MySchool
on primary --默认属于primary主文件组,可省略
(
--数据文件的具体描述
name = 'MySchool_data' --主数据库文件的逻辑名称
filename = 'D:\project\MySchool_data.mdf', --主数据库文件的物理名称
size = 5MB, --主数据库文件的初始大小
maxsize = 100MB, --主数据库文件增长的最大值
filegrowth = 15% --主数据文件的增长率
)
log on
(
--日志文件的具体描述,各参数含义同上
name = 'MySchool_log', --主数据库文件的逻辑名称
filename = 'D:\project\MySchool_data.ldf', --主数据库文件的物理名称
size=2MB, --主数据库文件的初始大小
filegrowth = 1MB --主数据文件的增长速度
)
go
创建多个数据文件和多个日志文件(employees)
create database employees
on primary
(
--主数据库文件的具体描述
name='employee1',
filename='D:\project\employee1.mdf',
size=10,
filegrowth=10%
),
(
--次要数据库文件的具体描述
name='employee2',
filename='D:\project\employee2.mdf',
size=20,
maxsize=100,
filegrowth=1
)
log on
(
--日志文件1的具体描述
name='employeelog1',
filename='D:\project\employee1_log.ldf',
size=10,
maxsize=50,
filegrowth=1
),
(
--日志文件2的描述
name='employeelog2',
filename='D:\project\empolyee2_log.ldf',
size=10,
maxsize=50,
filegrowth=1
)
go
二:删除数据库
usr master
if exists(select * from sysdatabases where name='....')
drop database ......
三:创建和删除表
use MySchool --在Myschool中创建表
go
create table Student
(
StudentNo int not null. --学号,int 类型,不允许为空
LoginPwd nvarchar(50) not null, --密码 nvarchar类型,不允许为空
StudentName nvarchar(50) not null, --名字,nvarchar类型,步允许为空
Sex bit not null, --性别,取值0或1
Email nvarchar(20) --邮箱,可为空
)
go
删除表
use MySchool
go
if exists(select * from sysobjects where naem='Student')
drop table Student
四:创建和删除约束
主键约束(Primary Key Constraint)
非空约束(Not Null)
唯一约束(Unique Constaraint)
检查约束(Check Constaraint)
默认约束(Default Constaraint)
外建约束(Foreign Key Constarint):用于在两表之间建立关系,需要指定引用主表的哪一列
alter table 表名
add constraint 约束名 约束类型 具体的约束说明
例:
--添加主键约束
alter table Student
add constraint PK_StudentNo Primary Key(StudentNo)
--添加唯一约束
alter table student
add constraint UQ_IdentityCard unique(IdentityCard)
--添加默认约束
alter table Student
add constraint DF_Address default('地址不详') for address
--添加检查约束
alter table Student
add constraint CK_BornDate checke(BornDate>='1980-01-01')
--添加外键约束(Result是从表,Student是主表)
alter table Result
add constraint FK_StudentNo
foreign key(StudentNo) references Student(StudentNo)
go
删除约束
alter table 表名
drop constraint 约束名
例:删除学生表中的默认约束
alter tablte Student
drop constraint DF_Address
怎样向已存在数据的表中添加约束
alter table Employee with nocheck ( whit nocheck不向已存在的数据约束)
add constraint
向已存在的数据表中插入一列
alter table 表名
add 列名 数据类型 null
在数据库中用SQL语句创建文件夹(例:在E盘创建一个project文件夹)
exec sp_configure 'show advanced option',1
go
reconfigure
go
exec sp_configure 'xp_cmdshell',1
go
reconfigure
go
exec xp_cmdshell 'mkdir D:\project'
使用变量 数据类型转换 逻辑控制语句(begin ...end; case...end; if...else; while)
一:变量
变量分为局部变量和全局变量 (全局变量是系统自定的,是不可手动给值的,若想自己定义全局变量可考虑创建全局临时表!)
局部变量的定义: declare @变量名 数据类型 (局部变量只能用于同一批处理当中!!!!!!!)
全局变量: @@
@@error 最后一个T-SQL语句错误的错误号
@@identity 最后一次插入的标识值
@@rowcount 受上一个SQL语句影响的行数
@@servicename 该计算机上SQl服务器的名称
@@version SQL Server的版本信息
@@transcount 当前连接打开的事务数
@@timeticks 当前计算机上每刻度的微秒数
@@max_connections 可以创建的,同时连接的最大数目
@@language 当前使用的语言的名称
二:给变量赋值 (set 和seklect)
set和select的区别
1:set不支持多个变量赋值,select支持
2:表达式返回多个值时,set出错,select返回最后一条数据
3:表达式未返回任何值时,set赋值为null(没有) select 保持不变
三:输出语句
print @变量名 或
select @变量名
一般从数据库中查找数据后赋值使用select赋值方法
四:数据类型转换
隐式转换: 类型相同或相兼容,自动转换
显式转换: 类型不同,可用convert 函数 或 cast 函数
相同点: 都用于某种数据类型的表达式转换为另一种数据类型
不同点: 在转换日期的时候,convert可以转化为指定的格式
cast (变量名 as 数据类型)
convert(数据类型, 变量名)
五:逻辑控制语句
流程控制语句 begin....end
通常使用在if判断和while循环中,相当于C#中的 {}
分支结构 if..else 或
case ...end(多重选择)
eg:
select 成绩=case
when 条件一 then 结果一
when 条件二 then 结果二
else 其他结果(可省略)
循环结构: while
事务,视图,和索引
一.事务
1.什么是事务:事务是一种机制,一个操作序列,它包含一组数据库的操作命令。并把所有命令作为一个整体一起向系统提交或撤销操作请求
,要么这些数据库操作都执行,要不都不执行。同生共死同进退,事务是一个不可分割的整体。
2:事务的四种特性:原子性、一致性、隔离性、持久性
3:如何执行事务操作:1.开始事务:begin transaction
2.提交事务:commit transaction
3.回滚事务:rollback transaction
例如:转账问题假定张三的账户直接转账1000元到李四的账户上:
use mybank
create table bank
(
cardId int primary key identity(,) not null,
cardowner nvarchar() not null,
moneyNum money
)
go
alter table bank
add constraint CK_moneyNum check(moneyNum>=)
go
insert into bank
values('张三',)
insert into bank
values('李四',)
set nocount on
print '查看转账前的余额'
select * from bank
go
begin transaction
--定义变量,用于累加事务执行中出现的错误
declare @errorSum int
set @errorSum=
update bank set moneyNum-= where cardId=
set @errorSum+=@@error
update bank set moneyNum+= where cardId=
set @errorSum+=@@ERROR
print '查看转账中的余额'
select * from bank
if(@errorSum<>)
begin
print '交易失败,回滚事务'
rollback transaction
end
else
begin
print '交易成功,提交事务'
commit transaction
end
go
print '查询账户余额'
select * from bank
go
消息为: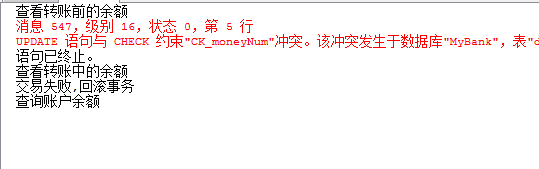 结果为:
结果为:
4:事物的分类:
1:显式事务:用begin transaction明确指定事物的开始(自己动手写的)
2:隐式事务:通过设置set implicit_transaction on 语句将隐式事务模式设置打开.当隐式事务操作时,SQL Server将在提交或回滚后自动启动新事务.不许描述开始,记得提交和回滚
3:自定义事务:将单独的T-SQL语句默认为一个事物.
二.视图
视图本质:视图是一张虚拟表,真正保存的是一堆SQL语句
创建视图的语法:
create view view_name
as
<SQL语句>
删除视图的语法:
drop view view_name
查看视图数据的语法:
select col_name1,col_name2,col_name3..........from view_name
例:使用T-SQL语句为教员创建查看'oop'课程最近一次考试成绩的视图,并通过视图查询结果
use MySchool
go
if exists(select * from sysobjects where name='vw_studentresult')
drop view vw_studentresult
go
create view vw_studentresult
as
select 姓名=Studentname,学号=student.studentNo,成绩=studentresult,
课程名称=subjectname,考试日期=examdate
from student,Result,Subject
where subject.SubjectId=(select SubjectId from Subject where SubjectName='oop')
and examdate=(select max(ExamDate) from Result where SubjectId=(select SubjectId from Subject where SubjectName='oop'))
go
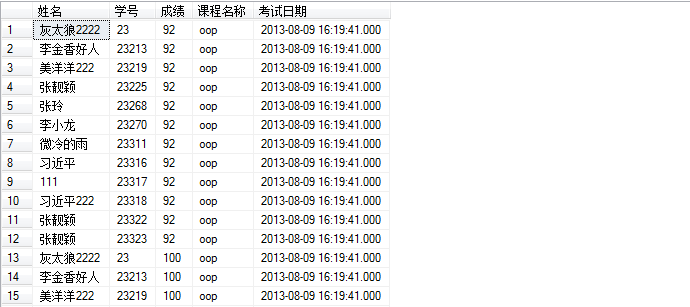
select * from vw_studentresult
查询结果如图所示:
问题:能不能对视图进行增删改操作:(考试可以,面试不行)
视图可以嵌套
视图中的select后不能跟(
Order by ,除非有top关键字
不能有into
引用临时表或者是变量).
三.什么是索引:
1.索引:是SQL Server编排数据的内部方法。它为SQL Server提供一种方法来编排查询数据
2.索引分类:唯一索引、主键索引、聚集索引、非聚集索引、复合索引、全文索引
3.使用T-SQL语句创建索引:
create unique clustered|nonclustered index indexname
on table (column_name[,column_name]...)
[with fillfactor=x]
4.删除索引:drop index table_name.index_name
例:为学生姓名创建非聚集索引
--创建索引
if exists(select name from sysindexes where name='IX_studentname')
drop index.student.IX_studentname
create nonclustered index IX_studentname
on student(studentname)
with fillfactor=
go
--查看数据
select * from Student
with (index=IX_studentname)
where StudentName like '张%'
如图结果为:

查看索引:
用系统储存过程sp_helpindex查看
sp_helpindex table_name
用视图sys.indexes查看
select * from sys.indexes
一.存储过程定义:
接收在数据库服务器上存储的预先编译好的一堆SQL语句
二.存储过程的优点:
1.执行速度快(预编译:可以看成编译后的中间代码,存储过程将会在SQL SERVER服务器上进行预编译)
2.允许模式化程序设计
3.安全性更高
4.减少网络流量
三.存储过程的分类:
1.系统存储过程:一般以sp开头(stored Procedure),由sql server 创建.管理和使用,存放在resource数据库中,类似于C#中的方法.
2.扩展存储过程:一般以xp开头,使用编辑语言(如C#)创建的外部存储过程,以DELL的形式单独存在.
3.用户自定义存储过程:一般以usp开头,由用户在自己的数据库中创建的存储过程(类似于C#中自定义的方法).
四.常用的系统存储过程:
sp_databases 列出服务器上的所有数据库
exec sp_databases
sp_helpdb 报告有关指定数据库或所有数据库的信息
sp_renamedb 更改数据库的名称
sp_tables 返回当前环境下可查询的对象的列表
sp_columns 返回某个表列的信息
sp_help 查看某个表的所有信息
sp_helpconstraint 查看某个表的约束
sp_helpindex 查看某个表的索引
sp_stored_procedures 列出当前环境中的所有存储过程
sp_password 添加或修改登录帐户的密码
sp_helptext 显示默认值、未加密的存储过程、用户定义的存储过程、触发器或视图的实际文本
五.用户自定义的存储过程
语法:
Create Procedure usp_info
as
select
注意:1.参数置于as前,且不用declare关键字
2.as后的变量需要declare关键字
六.带参数的存储过程
alter procedure usp_GetStuResult
@PassScore int=,
@name nvarchar()
--as之前给参数
as
if(@PassScore>= and @PassScore<=)
begin
select studentname,studentresult
from student,result
where student.studentno=result.studentno
and
studentresult>@PassScore
end
else
begin
raiserror('及格线输入有误',,)
end --开始测试存储过程书写是否存在问题
exec usp_GetStuResult @name='张三'
raiserror用法:
raiserror返回用户定义的错误信息时,可指定严重级别.设置系统变量记录所发生的错误
七.带output参数的存储过程:
alter proc usp_getpaglist
@pageindex, int--当前是第几页
@pagesize,--每页的记录数
@totalpages int output--总页数
as
select * from
(
select * ,row_number()over(order by studentno)as myid
from student
)as tmp
where myid between(@pageindex-)*@pagesize+ and@ pageindex * @pagesize
--总记录数=总记录数/@pagesize
declare @totalrecord int
select @totalrecord =count() from student
set @totalpages =ceiling( @totalrecord *1.0/@pagesize)
--调用
declare @pages int
set @pages=
exec usp_getpagelist ,@pages output
print @pages
优化MySchool数据库设计总结的更多相关文章
- 优化MySchool数据库设计之【巅峰对决】
优化MySchool数据库设计 之独孤九剑 船舶停靠在港湾是很安全的,但这不是造船的目的 By:北大青鸟五道口原玉明老师 1.学习方法: 01.找一本好书 初始阶段不适合,可以放到第二个阶段,看到知识 ...
- accp7.0优化MySchool数据库设计内测笔试题总结
1) 在SQL Server 中,为数据库表建立索引能够(C ). 索引:是SQL SERVER编排数据的内部方法,是检索表中数据的直接通道 建立索引的作用:大大提高了数据库的检索速度,改善数据库性能 ...
- S2--《优化MySchool数据库设计》总结
第一章 数据库的设计 1.1 数据库设计 数据库中创建的数据库结构的种类,以及在数据实体之间建立的复杂关系是决定数据库系统效率的重要因素. 糟糕的数据库设计表现在以下两个方面: *效率低下 * ...
- 优化MySchool数据库设计
第一章 数据库的设计 1.E-R图中: 矩形:实体 椭圆:属性 菱形:关系 直线:连接实体,属性和关系 2.映射基数 一对多 多对一 多对多 3.范式: 第一范式:确保每列的原子性 第二范式:确保表中 ...
- <<MySchool数据库设计优化>> 内部测试
1) 在SQL Server 中,为数据库表建立索引能够( C ). A. 防止非法的删除操作 B. 防止非法的插入操作 C. 提高查询性能 D. 节约数据库的磁盘空间 解析:索引的作用是通过使用索引 ...
- 《MySchool数据库设计优化》内部测试
1) 在SQL Server 中,为数据库表建立索引能够( C ). A. 防止非法的删除操作 B. 防止非法的插入操作 C. 提高查询性能 D. 节约数据库的磁盘空间 解析:索引的作用是通过使用索引 ...
- 优化MySchool数据库(一)
<优化MyShcool数据库>:能够的独立的分析|设计|创建|运营|你的独立的数据库系统 设计--->实现--->TSQL--->查询优化---->性能优化技术-- ...
- 优化MySchool数据库(二)
优化School数据库(TSQL建库建表建约束) 使用T_sql代码建库.建表.建约束: 建库: Create database HotelManagerSystem on ( ---- 数据文件-- ...
- 优化MySchool数据库(存储过程)
什么是“存储过程”: ---- 数据库中,用于存储“业务逻辑”的技术!(T-SQL代码当做数据一样保存到数据可) 语法 : [if exists(select * from sysobjects wh ...
随机推荐
- mysql悲观锁总结和实践--转
原文地址:http://chenzhou123520.iteye.com/blog/1860954 最近学习了一下数据库的悲观锁和乐观锁,根据自己的理解和网上参考资料总结如下: 悲观锁介绍(百科): ...
- swift 如何实现点击view后显示灰色背景
有这样一种场景,当我们点击view的时候,需要过0.几秒显示一个灰色或者别的颜色的背景 用button来实现,只有按下去的时候才会出现,往往在快速按下,快速抬起的时候是看不出这个变化的 下边是解决方案 ...
- YAML 语法
YAML 语法 来源:yaml 这个页面提供一个正确的 YAML 语法的基本概述, 它被用来描述一个 playbooks(我们的配置管理语言). 我们使用 YAML 是因为它像 XML 或 JSON ...
- C#字符串的不变性
看过一些C#教程的人都应该知道这句话:“在C#中,一旦对字符串对象进行初始化,该字符串对象就不能再被该变“.这句话可用简单的图示来说明: 1.声明变量 string str="first&q ...
- Angularjs真是个好东西
事件篇: 实例:(点击按钮内容加1) <!DOCTYPE html><html><head><meta charset="utf-8"&g ...
- C# ~ 从 委托事件 到 观察者模式 - Observer
委托和事件的部分基础知识可参见 C#/.NET 基础学习 之 [委托-事件] 部分: 参考 [1]. 初识事件 到 自定义事件: [2]. 从类型不安全的委托 到 类型安全的事件: [3]. 函数指针 ...
- JS基础之对象
JS中一切皆为对象,这是一句常说的话.了解JS对象,从这句话开始吧.JS中的基本数据类型如number,bool,字符串,数组,null,undefined等等都是对象. 对象的本质: 带有属性和方法 ...
- php中用GD绘制折线图
php中用GD绘制折线图,代码如下: Class Chart{ private $image; // 定义图像 private $title; // 定义标题 private $ydata; // 定 ...
- spring Mvc + Mybatis 中使用junit
在Spring Mvc + Mybatis的项目中我们有时候需要在测试代码中注入Dao操作数据库,对表进行增删改查,实现如下: 这是一般的maven项目项目结构 测试代码一般写在src/test/ja ...
- SpringMVC处理客户端请求的过程
SpringMVC处理客户端请求的过程 以程序部署在Tomcat上为例,网站程序使用SpringMVC框架开发. 1.客户端发起一个访问网站的请求(如: localhost:8080/index). ...